- 글자를 컴퓨터로 처리하기 위해서는 숫자로 변환해야 한다. 인코딩
- 각자 의미를 가지는 단어들을 그 의미가 사라지지 않도록 적절한 (차원)공간을 찾고 그 공간에 단어를 배치하는 것이 임베딩
- (차원)공간에 배치되면 그 위치 정보가 벡터
- 적절한 (차원)공간을 찾았다면 인접(의미가 비슷), 벡터 연산([왕] - [남자] + [왕비] = [여자]) 등 의미를 가지게 됨
[출처] https://blog.naver.com/2feelus/221985553891
인공신경망(딥러닝)의 Embedding 이란 무엇일까? (1/3) | 작성자 IDEO
Deep Learning에서 자주 등장하는 Embedding에 대해서 알아보도록 하겠습니다. (원글이 존재합니다)
Embedding을 위키피디아에서 찾아보면 다음과 같이 정의 되어있습니다.
'수학에서 embedding(혹은 imbedding)이란 하나의 사례안에 포함된 수학적 구조의 한 예로,
모집단의 성격을 보존하면서도 모집단과는 다른 형태의 소집단으로 매핑(mappig) 되는 것' 이라고 볼수 있습니다.
만약에 부모집단의 형태나 성격을 잘 보존할수 있는 소집단이 만들어 질수 있다면, 공간과 계산량이 적어져서 효율적인 계산이 이루어지는 효과를 얻을수 있을 것입니다.
인공 신경망에서의 Embedding은 어떤 의미를 가질까요?
인공신경망은 최근 몇년간 이미지 분석부터 자연어 처리및 시계열 예측까지 그 활용범위가 크게 확장되어왔습니다.
이중 큰 성공사례중 하나가 바로 embedding이라고 할수 있는데요, 그것은 바로 이름 성별 지역등의 분리된 이산변수(discrete variable)가 연속적인 벡터로 표현될수 있도록 했다는 점입니다. deep learning이 embedding기법이 만들어지면서 자연어 번역이나 범주(category)형 변수에 vector화가 가능하게 된것이죠.
이 글에서는 인공신경망의 임베딩에 대해서 설명하고, 왜 우리가 그것들을 사용하고 싶은지 어떻게 학습될수 있는지를 배워보려고 합니다.
위키피디아의 모든 책들을 Vector화 할수 있을까?
이글에서는 책 추천 시스템을 만들기 위해서, 위키피디아상의 모든 책들을 벡터로 만들어 볼겁니다. 이 시도를 통해서 어떻게 Embedding이 되는지 볼거에요.
Embeddings
임베딩은 이산된(범주형의)값을 연속적인 숫자로 구성된 벡터로 만드는것으로 볼 수 있습니다.
특히 인공신경망에서는 임베딩은 원래 차원보다 저차원의 벡터로 만드는 것을 의미하는데요, 원래 차원은 매우많은 범주형 변수들로 구성되어있고 이것들이 학습방식을 통해 저차원으로 대응되게 됩니다. (인근에 모여있는 것들끼리 그룹화)
인공신경망의 임베딩은 수천 수만개의 고차원 변수들을 몇백개의 저차원 변수로 만들어 주고, 또한 변형된 저차원 공간에서도 충분히 카테고리형 의미를 내재하기 때문에 유용합니다. (차원축소)
인공 신경망의 임베딩은 3가지의 주요 용도가 있습니다.
1. 가장 가까운 이웃정보를 찾도록 해준다. 이것이 유저의 관심사나 클러스터 카테고리에 대해서 추천을 하도록 도와줍니다.
2. 머신러닝의 지도식학습(Supervised Learning)의 입력값으로 임베딩을 사용할 수 있습니다.
3. 카테고리간의 개념과 관련도를 시각화 해주는 용도로 사용합니다.
책 추천 프로젝트관점에서 볼때, 임베딩 방식으로 37,000개의 책서평을 각각 50짜리 벡터로 만드는 것입니다.
더우기 임베딩이 학습되면서 책들은 유사한 책들끼리 임베딩 공간상에서 서로 가까이 위치 되게 됩니다.
One Hot Encoding의 한계
One Hot encoding 이란 하나의 범주형 데이터를 하나의 공간에 할당하는 것입니다. 주 절차는 특정 카테고리를 Vector상의 여러 공간중 하나에 할당하는 것이지요. 카테고리에 포함되면 1로 표시하고 포함되지 않으면 0으로 표시합니다. 이런 One Hot 방식은 두가지의 큰 단점이 있습니다.
1. 높은 카디널리티 (High-cardinality) 변수 : 카테고리성 변수가 범위가 너무 큰경우. 이런 값이 벡터로 변환되면 차원 관리가 어렵다.
2. 대응된 값이 완전히 무식방 방식으로 연결 : 비슷한 카테고리라고 할지라도, 벡터공간상에 전혀 관련성이 없이 위치된다.
첫번째 문제는 많이 알려져 있다. 각각의 카테고리가 추가될때마다 우리는 하나의 one-hot 방식으로 encoding된 vector공간하나를 추가해야 한다.
책이 37,000개면 37,000차원의 백터가 필요하다. 어떤 ML머신도 이렇게 큰 벡터를 학습하기는 어렵다.
두번째 문제 또한 제한적인 셩격이 있다 : one-hot 인코딩은 벡터공간상에 서로 다른 개체정보를 가까지 위치시킬수가 없다. 만약 벡터간의 유사도를
cosine 거리를 통해 확인한다면, one-hot방식에서는 항상 유사도가 0이 나오게 될것이다.
One-hot encoding 방식에서는 "전쟁과 평화"와 "안네 카레리나"(모두 톨스토이 작품)는 "전쟁과 평화"와 "은하수를 여행하는 히치하이커를 위한 가이드"보다 가깝게 위치할수 가 없다.
# One Hot Encoding Categoricals
books = ["War and Peace", "Anna Karenina",
"The Hitchhiker's Guide to the Galaxy"]
books_encoded = [[1, 0, 0],
[0, 1, 0],
[0, 0, 1]]
Similarity (dot product) between First and Second = 0
Similarity (dot product) between Second and Third = 0
Similarity (dot product) between First and Third = 0
이상적으로는 아래처럼 가까운 책들끼리 유사도가 높게 나와야겠죠.
# Idealized Representation of Embedding
books = ["War and Peace", "Anna Karenina",
"The Hitchhiker's Guide to the Galaxy"]
books_encoded_ideal = [[0.53, 0.85],
[0.60, 0.80],
[-0.78, -0.62]]
Similarity (dot product) between First and Second = 0.99
Similarity (dot product) between Second and Third = -0.94
Similarity (dot product) between First and Third = -0.97
다음 시간에는 One-hot encoding의 관련성 부족을 극복하기 위해, 위키피디아의 책과 링크정보를 이용해 Book Embedding을 만드는 과정을 살펴보도록 하겠습니다.
[출처 1] https://kh-kim.gitbook.io/natural-language-processing-with-pytorch/00-cover-5/02-dimension-reduction
차원의 저주(Curse of dimensionality)
차원이 증가하면 그것을 표현하기 위한(그 공간을 가득 채우기 위한) 데이터 양이 기하급수적으로 증가한다는 것입니다.
데이터가 부족하면 대부분 공간이 비어있는 희소성 문제가 발생. 그리고 대부분 데이터들이 뚝뚝 떨어져 있어서 군집화가 어려움.
차원 축소
높은 차원에서 데이터를 표현하는 과정에서 희소성 문제가 많이 나타남. 따라서 같은 정보를 표현할 때는 더 낮은 차원을 사용하는 것이 중요합니다.
데이터의 의미를 제대로 표현하는 특징을 추려내는 것
대부분의 상황에서 차원의 크기는 특징의 개수를 나타내고
특징(feature)이 너무 많으면 학습이 어렵기 때문에 더 좋은 특징만 가지고 사용하겠다는 것입니다.
주성분 분석 (PCA)
대표적인 차원 축소 방법으로는 주성분 분석principal component analysis(PCA)이 있습니다.
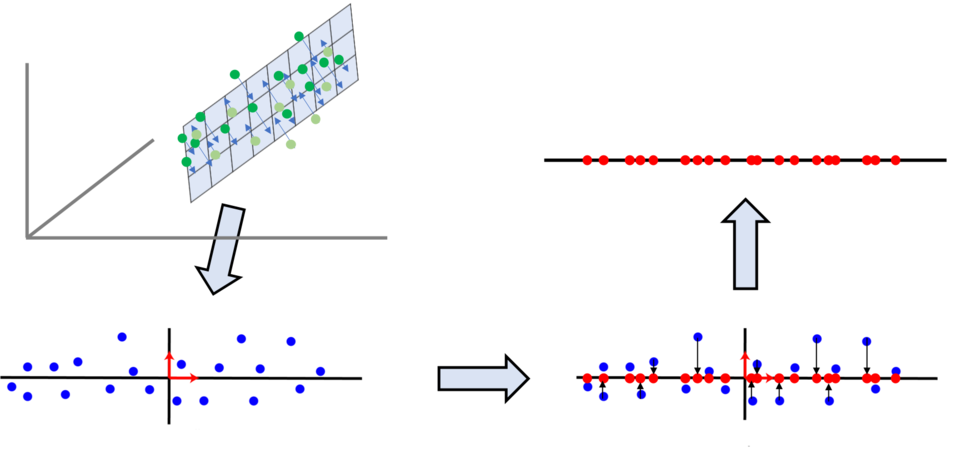
3차원에서 2차원, 다시 1차원으로 PCA를 수행하는 예
이와 같이 고차원high-dimension의 데이터를 더 낮은 차원으로 표현할 수 있습니다. 주로 특잇값 분해singular value decomposition(SVD)를 통해 주성분을 분석할 수 있습니다. 이때 축소를 위한 주성분은 다음과 같은 조건을 만족합니다.
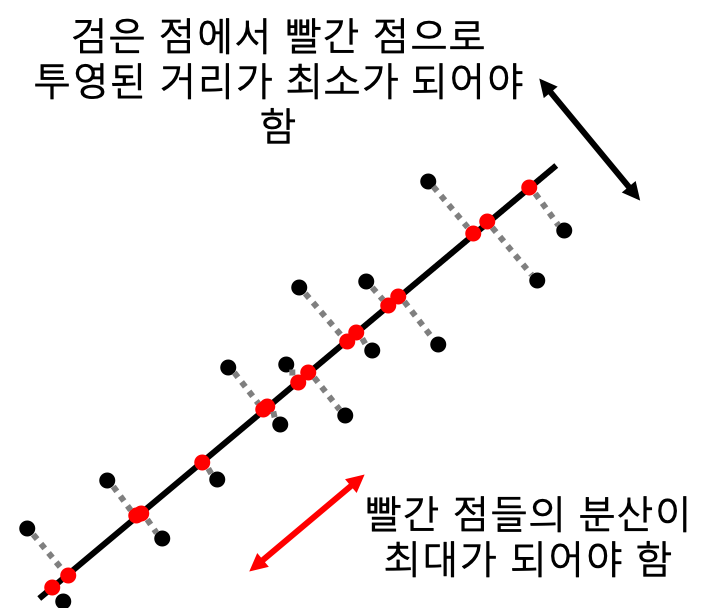
주성분의 조건
고차원에서 주어진 데이터들을 임의의 주성분 고차원 평면(초평면)hyperplane에 투사했을 때 투사점들 사이가 서로 최대한 멀어져야 합니다. 즉, 투사점들의 분산이 최대가 되도록 합니다.
또한, 고차원 평면으로 투사할 때 원래 벡터와 고차원 평면상의 투사된 거리가 최소가 되어야 합니다. ???
주성분분석은 데이터의 분포를 가장 잘 표현하는 성분을 찾아주는 것입니다.
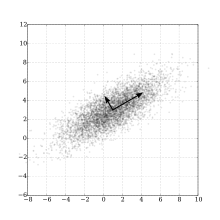
데이터 분포와 그들의 주성분 — Wikipedia
위의 그림에서 x, y 축보다 화살표방향의 두 축이 이 데이터를 더 잘 표현하는 것(주성분)을 알 수 있습니다.
주성분은 통계학적으로 데이터들의 분산이 가장 큰 방향 벡터를 말합니다.
(분산 - 데이터가 평균에서 얼마나 떨어져 있는가를 의미)
주성분 분석을 통해 고차원의 데이터를 더 낮은 차원으로 효과적으로 압축할 수 있습니다. 하지만 앞에서 언급했듯이 실제 데이터(점)의 위치와 고차원 평면에 투사된 점의 거리가 생길 수 밖에 없습니다. 이는 곧 정보의 손실을 의미합니다. 특히 주성분은 직선 또는 평면이므로, 이러한 손실은 불가피하게 나타납니다. 이 과정에서 너무 많은 정보가 손실된다면 효율적으로 정보를 학습하거나 복구할 수 없습니다. 따라서 높은 차원에 표현된 정보를 지나치게 낮은 차원으로 축소하여 표현하기는 어렵습니다. 특히 데이터가 비선형적으로 구성될수록 더욱 어려워집니다.
매니폴드 가설
이때 하나의 가설을 통해 차원 축소에 더 효율적으로 접근해볼 수 있습니다. 높은 차원에 존재하는 데이터들의 경우, 실제로는 해당 데이터들을 아우르는 낮은 차원의 다양체manifold 역시 존재한다는 매니폴드 가설manifold hypothesis입니다.

3차원 공간에 기묘한 모양으로 분포한 샘플들이 2차원 매니폴드에 속하는 모습
이와 같이 3차원 공간에 분포한 데이터를 아우르는 소용돌이 모양의 구부려진 2차원 매니폴드가 존재할 수도 있습니다. 이런 매니폴드를 찾아 2차원 평면에 데이터 포인트들을 맵핑할 수 있겠지요. 그러한 매니폴드를 찾을 수 있다면 앞서 살펴본 주성분 분석처럼 데이터를 고차원 평면에 선형적으로 투사하며 생긴 손실을 최소화할 수 있을 것입니다.
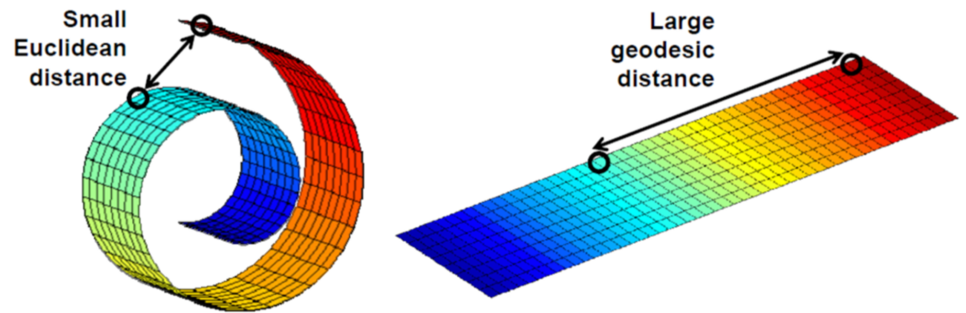
3차원 공간상의 최단경로와 2차원 매니폴드 공간의 최단경로가 다르다
매니폴드 가설에 따르면 또 하나의 흥미로운 특징이 있습니다. 앞서 그림에서 볼 수 있듯이, 고차원상에서 가까운 거리에 있던 데이터 포인트들일지라도, 매니폴드를 보다 저차원 공간으로 맵핑하면 오히려 거리가 멀어질 수 있다는 것입니다. 그리고 저차원의 공간상에서 가까운 점끼리는 실제로도 비슷한 특징feature을 갖는다(군집화 가능하다)는 것입니다. 즉, 저차원의 각 공간의 차원축은 고차원에서 비선형적으로 표현될 것이며, 데이터의 특징을 각각 표현하게 될 것입니다.
예를 들어 다음 그림과 같이 MNIST 데이터를 2차원의 숨겨진 저차원low-dimensional latent space에 표현한다고 가정합니다. 빨간색으로 표시된 각 샘플은 2차원 공간에서는 사람이 인지하는 특징과 비슷한 특징을 갖는 위치와 관계에 있겠지만, 원래의 데이터 차원인 784차원의 고차원 공간에서는 전혀 다른 거리와 관계를 지닐 것입니다.

MNIST 데이터를 2차원 공간에 표현했을 때 두 샘플의 위치
딥러닝이 잘 동작한 이유
아마도 딥러닝이 훌륭한 성능을 내는 이유를 여기서 찾을 수 있을 것입니다. 대부분의 경우 딥러닝이 문제를 풀기 위해 차원 축소를 수행하는 과정은, 데이터가 존재하는 고차원상에서 매니폴드를 찾는 과정입니다. 주성분 분석(PCA)과 같이 다른 선형적인 방식에 비해 딥러닝은 비선형적인 방식으로 차원 축소를 수행하며, 그 과정에서 해당 문제를 가장 잘 해결하기 위한 매니폴드를 자연스럽게 찾아냅니다. 이것이 바로 딥러닝이 그토록 성공적으로 동작하는 이유일 것으로 예상합니다.
아직 증명되지 않은 가설이기 때문에 확언할 수는 없습니다. 하지만 대부분의 연구가 실제 이 가설에 기반하여 이루어지고 있으며 성과를 내고 있습니다.
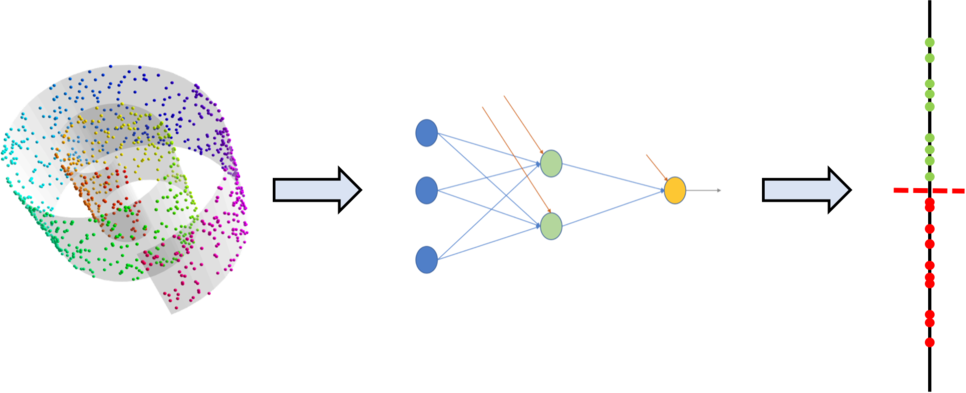
3차원 데이터를 입력으로 받아 1차원의 이진 분류를 수행할 때
오토인코더
자연어 처리에서 단어를 표현하기 위한 차원 축소를 본격적으로 다루기에 앞서, 오토인코더autoencoder에 관해 이야기해보겠습니다. 오토인코더는 다음과 같은 구조를 가진 딥러닝 모델 입니다.
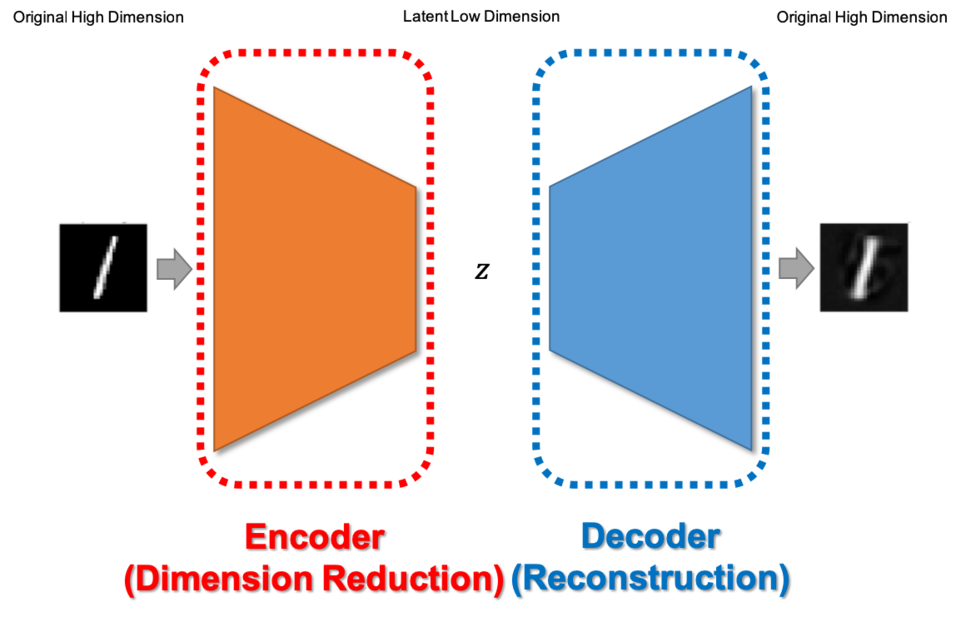
전형적인 형태의 오토인코더
고차원의 샘플 벡터를 입력으로 받아 매니폴드를 찾고, 저차원으로 축소하는 인코더를 거쳐 병목bottle-neck 구간에서의 숨겨진hidden 벡터로 표현합니다. 그리고 디코더는 저차원의 벡터를 받아, 다시 원래 입력 샘플이 존재하던 고차원으로 데이터를 복원하는 작업을 수행합니다. 복원된 데이터는 고차원 상의 매니폴드 위에 위치하게 될 겁니다.
이때 고차원의 벡터를 저차원으로 압축한 후 다시 복원하는 과정에서, 오토인코더는 병목의 차원이 매우 낮기 때문에 복원에 필요한 정보만 남기고 필요 없는 정보는 버려야 합니다. 좁은 병목구간을 통과하기 위해서는 복원에 필요 없는 정보부터 버려질 것입니다. 따라서 이 구조의 모델을 훈련할 때는 복원된 데이터와 실제 입력 데이터 사이의 차이를 최소화하도록 손실 함수를 구성합니다.
이때 정보량이 낮은 정보부터 버려질 것입니다.
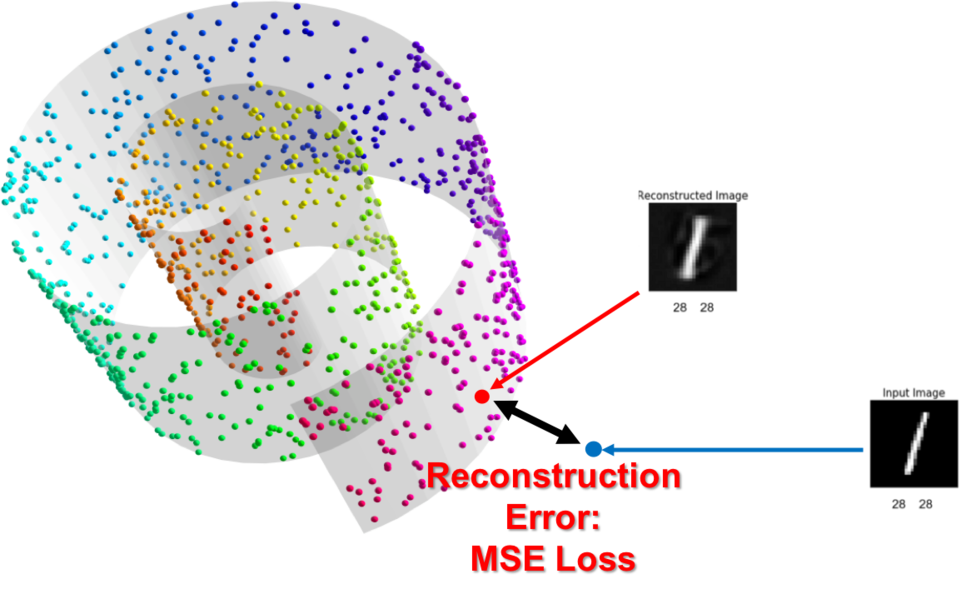
고차원(3차원)에서 저차원(2차원)으로 투사할 때의 정보 손실(복원 오류)
하지만 고차원에서 저차원으로 데이터를 표현하면서 손실이 따를 수 있으므로, 훈련이 완료된 모델일지라도 복원된 데이터는 실제 입력과 차이가 있을 수 있습니다.
오토인코더를 사용하여 이전 장에서 TF-IDF 등을 활용해 계산한 희소 단어 특징 벡터를 입력으로 넣고 같은 출력값을 갖도록 훈련했을 때, 오토인코더의 병목 계층 결괏값을 덴스 단어 임베딩 벡터로 사용할 수 있을 것입니다.
단어 임베딩
대표적인 word2vec, word2vec의 단점을 보완한 GloVe
[출처] https://eda-ai-lab.tistory.com/428
임베딩 기법들
· One Hot Encoding
· TF-IDF
· LSA
· Word2Vec
· Glove
· FastText
One Hot Encoding
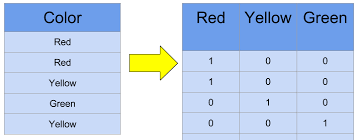
· 개념 : 각 단어에 Index를 부여하는 방식으로 표현하는 단어의 Index에 1을 넣고 그렇지 않은 곳 에는 0을 넣는 방법
· 장점 : 사용하기 매우 쉬움. pandas의 get_dummies함수나 sklearn의 preprocessing.OneHotEncoder을 사용하면 됨
· 단점 : 단어의 의미를 전혀 이해하지 못함. 단어의 개수가 많아지면 차원의 길이가 매우 커지는 문제가 생기고 Sparse 하게(대부분 0으로 채워지는) 벡터가 구성됨.
TF-IDF

· 개념 : 단어의 빈도와 역 문서의 빈도를 사용하여 단어에 가중치를 부여하는 방식
· 장점 : 어떤 단어가 중요한 단어인지 직관적인 해석이 가능.
· 단점 : 문맥에 대한 고려를 해주지 않음 (단어의 의미가 포함되지 않음)
LSA
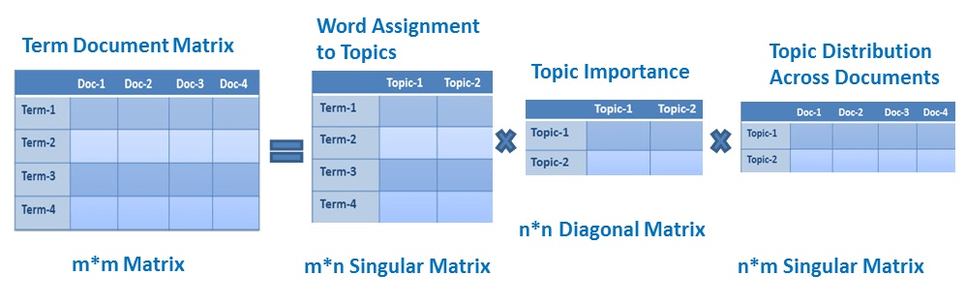
· 개념 : 기존의 원핫인코딩이나 TF-IDF의 경우 단어의 의미를 고려하지 못하는 단점을 해결한 방법
· 장점 : 단어의 잠재적인 의미를 고려
· 단점 : 새로운 정보에 대한 업데이트가 어렵고 단어-문서 간의 유사도를 계산하기 어려움 (차원이 축소되어서 단어 간의 의미 파악이 힘듦. 후에 Glove에서 이를 지적하고 해결)
Word2Vec
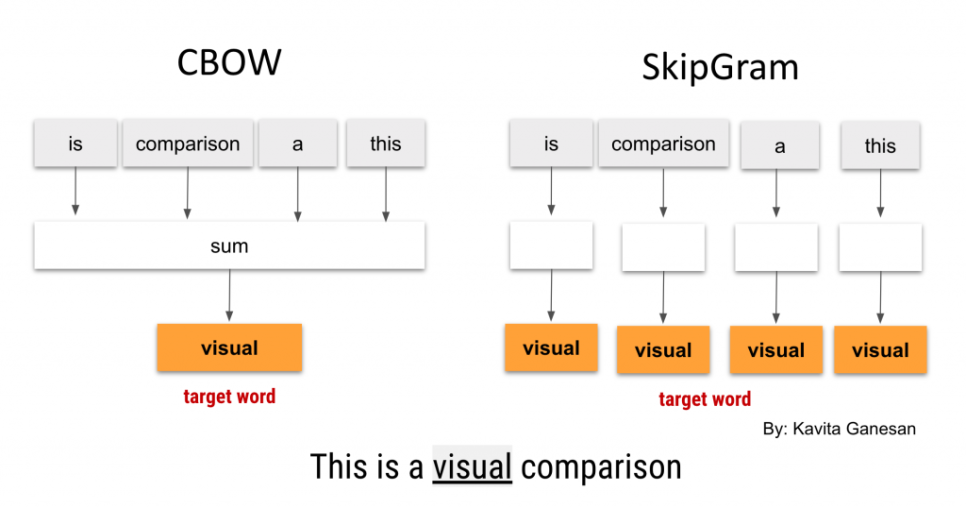
Difference between SkipGram and CBOW training architectures
· 개념 : 기존의 원핫인코딩이나 TF-IDF의 경우 단어의 의미를 고려하지 못하는 단점을 해결한 방법으로 중심 단어와 주변 단어 간의 관계를 통해서 임베딩 하는 방법
· 방법
· CBOW : 주변에 있는 단어들을 가지고, 중간에 있는 단어들을 예측하는 방법
· Skip-Gram : 중심의 단어로 주변에 있는 단어들을 예측하는 방법
· 장점 : 단어들의 유사도를 계산하기에 임베딩 된 벡터 자체가 단어의 의미를 포함함. (Dense Representation이기에 적은 차원으로 대상을 표현할 수 있고 일반화 능력을 갖추고 있음). 온라인 방식으로 모델에 데이터가 공급될 수 있으며 전처리가 거의 필요하지 않으므로 메모리가 거의 필요하지 않음
· 단점 : 사용자가 지정한 윈도우(주변 단어 몇 개만 볼지) 내에서만 학습/분석이 이뤄지기 때문에 말뭉치 전체의 공기 정보(co-occurrence)는 반영되기 어려움(Glove에서 지적한 단점). 데이터가 충분히 많아야 학습이 잘 됨(아래와 같이 데이터가 적은 경우 학습이 잘 안 됨). 카테고리 수가 너무 많으면(어휘가 많으면) softmax함수를 사용하면 모델을 학습하기가 매우 어려움, 이를 해결하기 위해 negative sampling 같은 방법이 도입
Glove
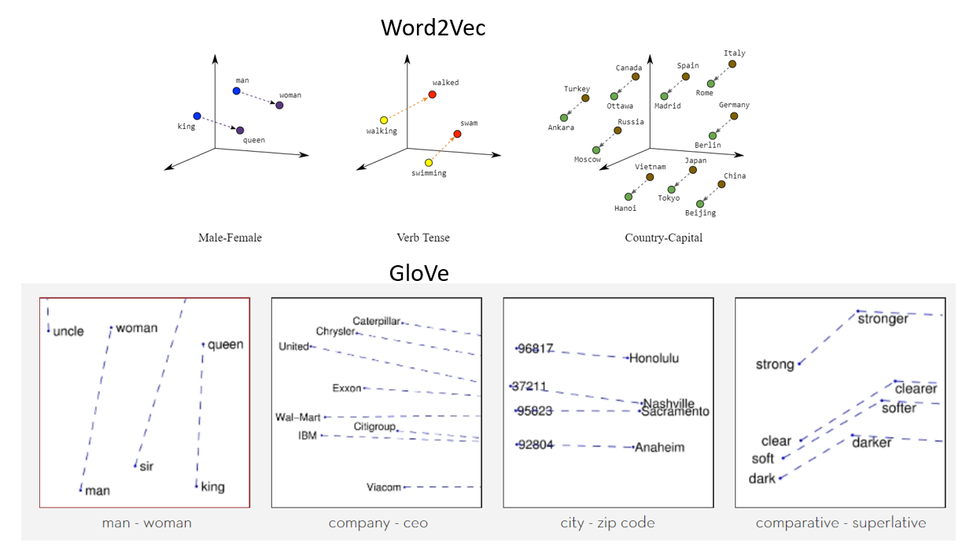
· 개념 : LSA, Word2Vec의 문제점을 개선한 모델로 “임베딩 된 단어 벡터 간 유사도 측정을 수월하게 하면서도 말뭉치 전체의 통계 정보를 좀 더 잘 반영”
· 방식 : Co-occurrence 가 있는 두 단어의 단어 벡터를 이용하여 co-occurrence 값을 예측하는 regression 문제를 품
· 장점 : 벡터 공간에서 하위 선형 관계를 포착하도록 단어 벡터를 적용 보통 Word2Vec보다 성능이 좋음. 단어와 단어보다는 단어 쌍과 단어 쌍 사이의 관계를 고려하여 단어 벡터에 좀 더 실용적인 의미 추가. "the"와 같은 무의미한 stop words에 가중치를 낮게 줌
· 단점 : 계산 복잡성이 높고 메모리를 많이 필요로 함. 특히, 동시 발생 행렬과 관련된 하이퍼 파라미터를 변경하는 경우 행렬을 다시 재구성해야 하므로 시간이 많이 걸림. 반대 단어 쌍을 분리하는 방법. 예를 들어, "양호한"및 "나쁜"은 일반적으로 벡터 공간에서 서로 매우 가깝게 위치하므로 정서 분석과 같은 NLP 작업에서 단어 벡터의 성능이 제한(Word2Vec도 동일한 문제를 안고 있음)
FastText
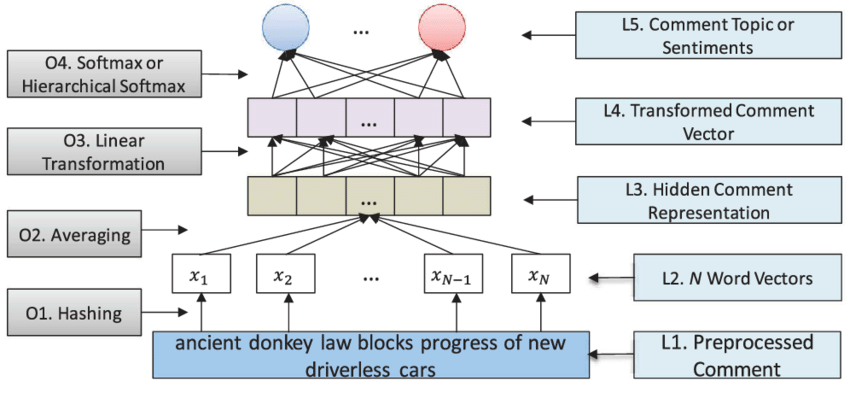
Model architecture of fastText, where L (in L1) represents layer and O (in O1) operation.
· 개념 : Facebook에서 개발한 word embeddings과 text classification 용도의 라이브러리로 294개의 언어에 대해 학습된 모델을 가지고 있음. (Word2vec이 영어에만 잘되는 것에 비해 FastText는 많은 언어에 대해서도 잘된다는 장점이 있음). 기본적인 모델은 Word2vec의 확장판으로 구성 단어에 대한 벡터를 생성(포함된 문자의 하위 문자열로 구성된 벡터로 만들어짐, 이를 통해 word2Vec은 어휘가 없는 단어를 볼 경우 아무것도 모르지만, fast Text는 어느 정도 모방을 함)
· 장점 : n-grams에서도 유연함. 어휘가 없는 단어를 볼 경우 아무것도 모르지만, fast Text는 어느정도 모방을 함. 동시 등장 정보를 보존
· 단점 : Supervised learning으로 학습하는데 많은 양의 데이터가 필요.
