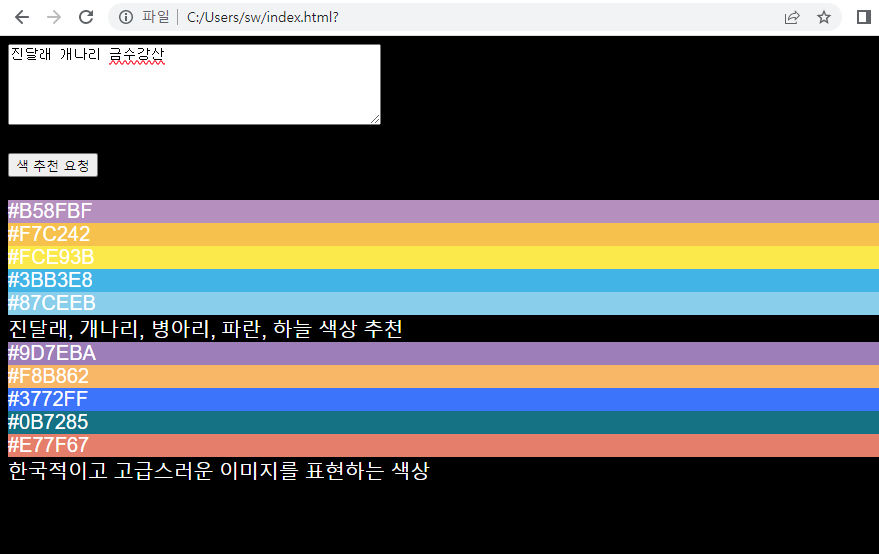
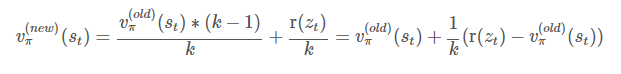Weni이 LlamaIndex에서 12가지 RAG 고통점과 이에 대한 해결책을 소개합니다.
데이터 정제와 더 나은 프롬프팅을 제안하여 문제를 해결할 수 있습니다.
'unstructured IO cleaning library'를 활용하여 데이터 정제를 할 수 있으며, 더 나은 프롬프팅을 위해서도 작업이 필요합니다.
이번 동영상에서는 기타 해결책에 대해서도 소개할 예정입니다.
L-Index와 관련된 두 번째, 세 번째 통증점은 무엇일까요?
통증점 2는 초기 검색 단계에서 중요한 컨텍스트인 상위 순위 문서가 누락되었다는 것이에요.
L-Index는 PromTuner라는 하이퍼파라미터 튜닝 기술을 가지고 있어, 평가자 선택이 중요하다는 점도 있습니다.
또한, 결과 수정을 위한 리랭킹이 성능 향상을 눈에 띄게 보여준다는 점도 있죠.
만약 컨텍스트 누락이 있다면 리트리버 전략을 조정해야 할 필요성이 있습니다.
마지막으로, Llama Index는 다양한 고급 검색 전략을 가지고 있습니다
검색 전략 선택과 임베딩 모델 세밀하게 조정하기
가장 적합한 검색 전략을 선택하려면 사용 사례에 기반한 평가 결과를 확인해야 해요.
또한, 임베딩 모델을 세밀하게 조정하면 성능을 높일 수 있어요.
데이터 정제, 프롬프트 압축, 노드 재정렬 등의 기법을 사용하여 특정 문제를 해결하는데 도움이 된답니다.
임베딩 모델을 세밀하게 조정하면 검색 결과의 성능을 향상시키고 비용을 줄일 수 있었던 사례도 있었어요.
LlamaIndex의 출력 작업과 쿼리 변환 전략은?
LlamaIndex에서는 다양한 출력 작업 모듈을 사용하여 결과 출력과 관련된 문제를 해결하고, 출력 스키마를 정의하고 JSON 형식으로 출력하죠.
부족한 출력으로 인해 일부 응답이 발생하는 경우, 질의 변환 전략을 사용해 해결됩니다.
이러한 전략에는 경로 기반 질의 엔진, 질의 재작성 등이 포함돼요.
텍스트 데이터 처리를 위한 쿼리 엔진 개발과 스케일링 과제란?
두 개의 다른 문서를 비교하고 대조할 때 사용되는 10K SEC 10K 문서들에 대해 설명하고, 이에 대한 질문을 하고 대조해야 할 경우 사용해요.
쿼리 엔진을 사용하여 가상의 응답과 문서를 비교하여 최적의 답변을 선택하고, 데이터 투입의 확장성에 대한 과제를 이야기해요.
Llama 인덱스는 병렬화된 투입 파이프라인을 도입하여 확장성을 높이는데 기여하며, 일부 구조화된 데이터에 대해서는 텍스트를 SQL로 변환하여 처리해요.
Llama Index의 최신 논문과 기능은 무엇인가요?
최근 논문 'Chain of Table'과 'Mix Self-Consistency Pack'의 솔루션을 소개했어요.
'Chain of Table'은 테이블 데이터에 대한 사용자 쿼리를 기반으로, 테이블 작업의 순서를 계획하여 올바른 정보를 검색해요.
'Mix Self-Consistency Pack'은 텍스트 기반 및 기호 기반의 논리 추론을 통해, 텍스트를 SQL 또는 Python으로 변환하여 최상의 성능을 제공해요.
'Chain of Table'은 특히 하나의 열에 여러 원소가 있는 경우와 데이터의 혼합이 있는 경우에 효과적으로 작동해요.
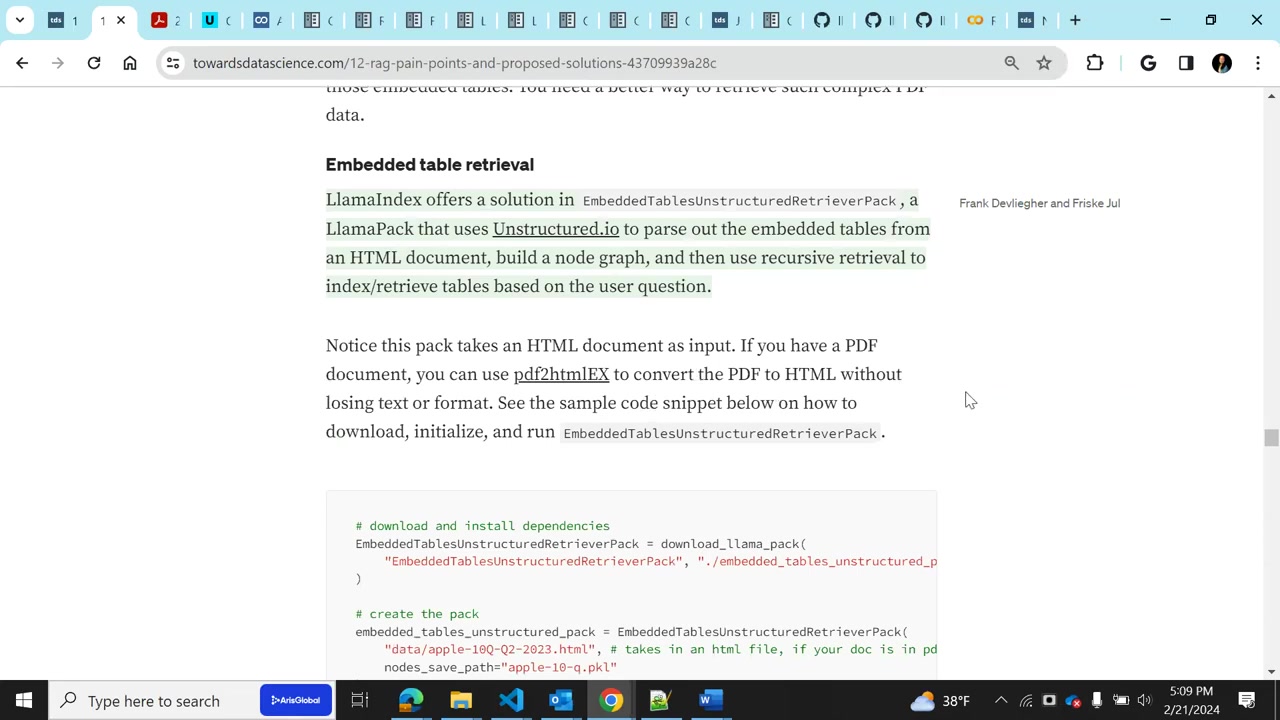
Llama Index에는 데이터를 추출하기 어려운 복잡한 PDF에서의 데이터 추출에 대한 'Complex PDFs' 기능이 이미 추가되어 사용 가능해요.
Open Air모델보다 Fullback 모델이 필요한 이유는?
Open Air모델을 사용하면속도 제한 문제와시스템 오동작 위험이 있어서, Fullback 모델이 필요해요.
Neutrino 라우터와 Open R은 Fullback 모델 솔루션으로 제안되었는데, Neutrino 라우터는스마트하게 CSAs를 다른 모델로 라우팅하여 최저가 또는 가장 성능이 좋은 경로를 선택하는 기능을 제공하고, Open R은표준화된 API로 어떤 모델에게도 낮은 가격으로 접근할 수 있고, 주 호스트의 중단 시 Fullback을 제공합니다.
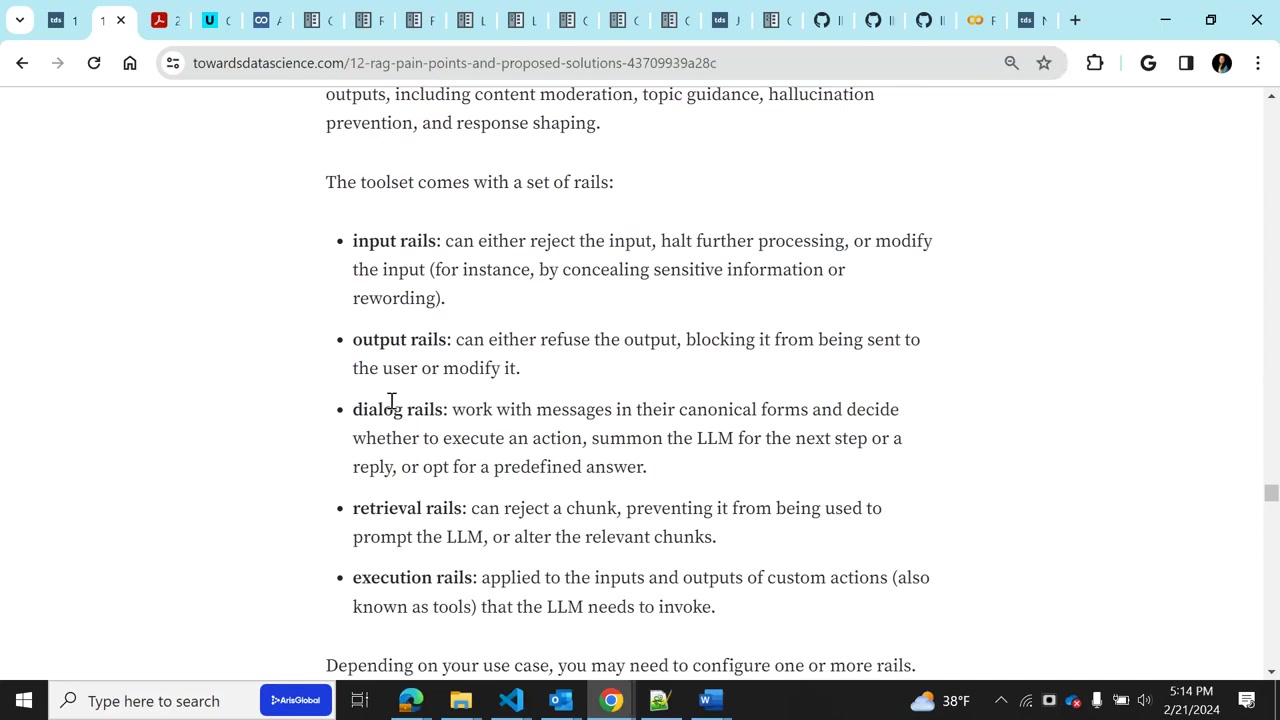
게다가 Nemo guardrails는오픈 소스 기반의 보안 도구셋으로, 입출력 moderation, 주제 가이드, 환각 방지, 응답 형성, 그리고 GME index와의 통합 등을 처리하여 보안 기능을 강화할 수 있죠.
이것을 사용하면 프로그래밍으로 가이드 레일을 설정할 수 있으며, 입력/출력 대화 도메인을 제한하여 사용자가 대화 주제를 벗어나지 않도록 합니다.
Retriever rail과 LlamaIndex의 차이점과 LlamaGuard와 NAD Guard의 비교는?
Retriever rail을 RAG로 사용하나, 이번에는 RAG로 LlamaIndex를 사용하여 실험 중이에요.
LlamaIndex는 아직 실험적이며, txt 파일 형식만 지원하죠.
LlamaGuard는 입력 및 출력 모더레이션을 처리하지만, NAD는 도메인 모더레이션과 실행 도구를 다루죠.
LamaGuard와 NAD Guard는 하나의 솔루션으로 결합될 수 있어요.
NAD Guard에도 Nimo Guard가 있는데, 두 가지 방법을 하나의 솔루션으로 결합하는 것을 추천해요.
LlamaIndex 프레임워크의 툴셋은 어떤 장점이 있을까?
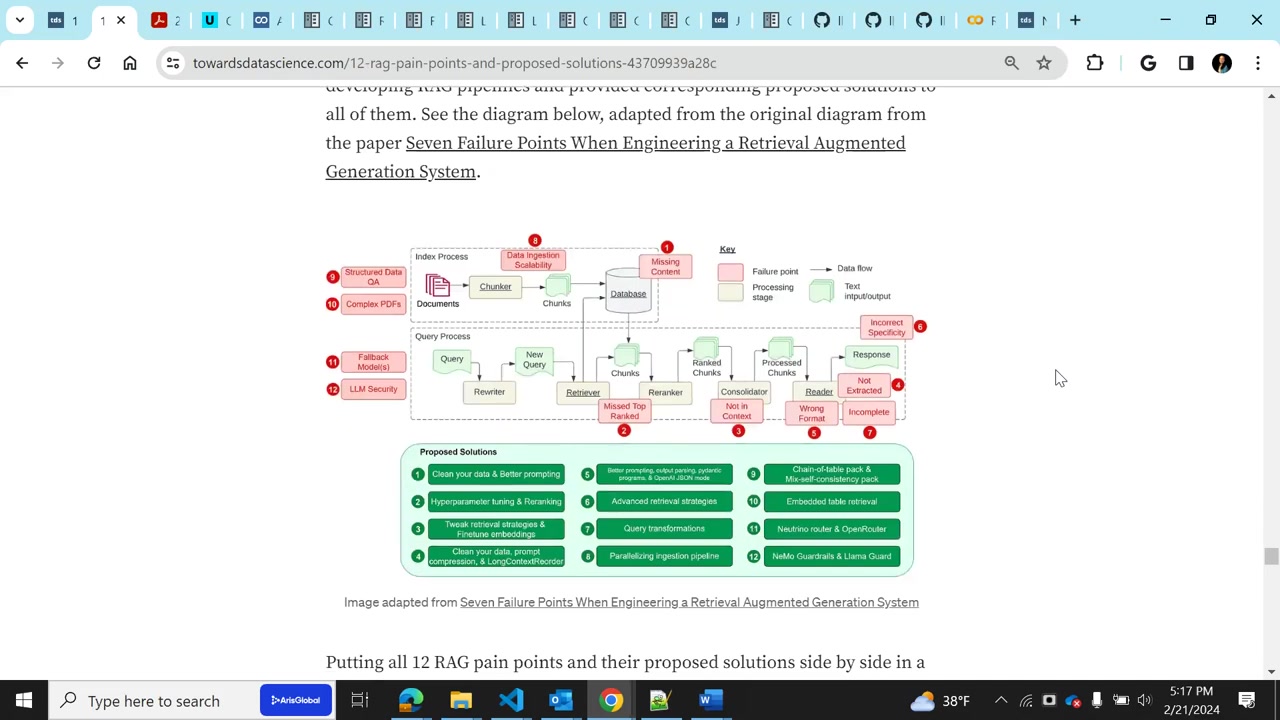
LlamaIndex 프레임워크의 툴셋은 정말로 보석같은 존재로 즐겁게 활용되며, 이 그림은 시작점으로서의 역할을 하는군요.
어떤 도메인이나 구체적인 사용 사례에 따라 이 다이어그램을 확장할 수 있다는 장점이 있어요.
또한, LlamaIndex 프레임워크에는 여러 실무 개발 도구와 함께 숨겨진 보석이 많아요.
개발자들은 매일 랙 시스템을 개발하며, 이 도구들을 탐구하고 활용해야 합니다.
게다가 새로운 기능들은 통상적인 문제가 아니더라도, 특정 이슈 해결에 도움을 주는 강력한 RAG 파이프라인을 구축하는데 기여합니다.
글쓰기로 많은 돈을 벌 수 있다는 것은 사실입니다. 그러나 글쓰기 자체는 수익을 창출할 수 있는 업종 중 하나일 뿐, 수익을 창출하기 위해서는 여러가지 요소가 조합되어야 합니다.
글쓰기로 수익을 창출하는 구체적인 방법은 아래와 같습니다.
재능과 소질을 갖춘 글쓰기를 시작합니다. 재능은 자연스러운 재미있고 정교한 언어사용력, 소질은 적극적인 생각과 감각, 창의적 인 상상력이 있어야 합니다.
자신의 글쓰기 재능과 소질을 유발할 수 있는 연습과 공부를 꾸준히 합니다. 예를 들어, 읽고 쓰기 연습, 영어권 작가의 작품을 읽기, 시...
- 계속
자신의 작품을 판매할 수 있는 채널을 찾습니다. 일반적으로 글쓰기 작품을 판매할 수 있는 채널은 출판사, 잡지, 신문, 웹진 등이 있습니다. 이러한 채널을 통해 자신의 작품을 판매할 수 있습니다.
자신의 작품을 적극적으로 홍보합니다. 자신의 작품을 출간한 채널을 통해 적극적으로 홍보할 수 있지만, 소셜 미디어나 웹사이트, 블로그 등을 통해 자신의 작품을 소개할 수도 있습니다.
글쓰기로 수익을 창출하는 것은 쉽지 않...
- 계속
할 수 있지만, 자신의 재능과 기술을 기반으로 여러 가지 방법을 시도해보면서 수익을 창출할 수 있을 것입니다. 글쓰기 수익을 창출하기 위해서는 자신의 재능과 기술, 열정과 적극성, 새로운 아이디어와 창의적 접근법 등을 기반으로 한 적극적인 접근과 여러 가지 시도가 필요할 것입니다.
글쓰기 창의력을 키우는 방법은?
- 글쓰기 창의력을 키우는 방법은?
글쓰기 창의력을 키우기 위해서는 여러 가지 방법이 있을 수 있습니다. 아래에 제시한 것 중 적절한 것을 참고해보세요:
읽기: 여러 장르의 책을 읽고 새로운 아이디어를 얻고, 인간관계, 상황, 생각 등 재밌는 소재를 찾기 위해서 읽기를 자주 합니다.
새로운 경험을 쌓기: 새로운 경험을 쌓기 위해서는 새로운 일을 시도하고, 새로운 장소를 찾아가고, 새로운 사람과 인연을 쌓습니다.
창의적 생각 기술 연습: 창의적 생각 기술을 연습하기 위해서는 새로운 아이디어를 창출하기 위한 연습을 합니다. 예를 들어 재료가 제한적인 상황에서 요리를 고민하거나, 장난감으로 새로운 게임을 만들기를 시도할 수 있습니...
- 계속
글쓰기 창의력을 키우는 방법은 다양한 것들이 있습니다. 아래와 같은 것들을 시도해보세요:
새로운 경험과 정보를 습득하기: 새로운 정보를 습득하는 것은 새로운 창의적 생각을 유발할 수 있습니다. 책을 읽거나 새로운 정보를 찾아보거나, 새로운 경험을 해보는 것도 좋은 아이디어입니다.
생각을 적어보기: 생각을 적어보는 것은 새로운 아이디어를 창출하는데 도움이 됩니다. 적기 전에 생각을 정리하고, 새로운 아이디어가 생길 때마다 적어보세요.
생각을 정리하기: 생각을 정리하는 것은 창의적 생각을 유발할 수 있는 좋은 방법입니다. 생각을 정리하기 위해서는 우선 생각을 정리할 주제를 정하고, 그 주제에 대한 생각을 정리해보는 것이 좋습니다.
새로...
- 계속
글쓰기 창의력을 키우는 방법에 대해서 알려드리겠습니다.
새로운 경험과 정보 습득: 새로운 경험과 정보를 습득하면 새로운 아이디어가 생길 수 있습니다. 책을 읽거나 새로운 지식을 습득하는 것부터 새로운 사람과 인터넷으로 새로운 인상을 얻는 것까지, 새로운 경험과 정보를 습득하는 것은 창의력을 키우는 좋은 방법입니다.
상상력 운동: 상상력을 운동하는 것도 창의력을 키우는 방법 중 하나입니다. 상상력 운동은 상상력을 자극해 주기 위한 작업입니다. 새로운 이야기를 만들거나, 새로운 상황을 그리거나, 새로운 사물을 생각해보는 것 등 상상력 운동을 하면 창의력을 키우는 것이 가능합니다.
새로운 관점 취하기: 새로운 관점을 취하는 것...
- chat-gpt는 응답하는 문장의 길이 제한으로 자주 문장이 중간에 끊어진다.(끊어진 곳을 ...로 표시하였습니다.)
- chat-gpt와 유익하게 대화하려면 계속 원하는 쪽으로 대화를 이끌어 가는 요령이 필요하다.
어느 날, 동네에서 재미있는 일이 일어났습니다. 이날은 아이들이 놀이터에서 즐거운 시간을 보내고 있던 날이었습니다. 그런데 갑자기, 놀이터에 이상한 로봇이 나타났습니다.
이 로봇은 아이들이 놀이터에서 하는 모든 놀이를 잘해서, 아이들은 놀라고 기뻐했습니다. 하지만 이 로봇은 그리고 그를 만든 사람은 아이들이 궁금해하는 모든 질문에 답해주는 놀라운 마법을 이용했습니다.
이 로봇은 자신이 만든 사람들이 만든 기계 학습 모델을 이용해서, 아이들이 하는 놀이를 잘 할 수 있게 만들었고, 아이들이 궁금해하는 모든 질문에 답할 수 있도록 만들어졌습니다.
아이들은 이 로봇의 마법을 보고 기뻐하고, 로봇을 좋아해졌습니다. 그리고 아이들
하던 이야기를 연결해서 계속 해주세요
이야기를 계속 해드리겠습니다.
아이들은 이 로봇의 마법을 즐겼고, 그들은 이 로봇을 좋아해졌습니다. 그래서, 로봇은 아이들의 친구가 되었고, 아이들은 로봇과 함께 재미있는 시간을 보냈습니다.
그리고 아이들은 로봇이 어떻게 그들의 질문에 답하는지, 어떻게 놀이를 잘하는지 궁금해졌습니다. 로봇은 아이들의 질문에 답하며, 아이들에게 AI의 마법을 설명해주었습니다.
로봇은 아이들에게, 인공 지능은 컴퓨터 프로그램을 이용해서 사람이 하는 모든 일을 자동으로 할 수 있게 만든 놀라운 기술이라고 설명해주었습니다. 인공 지능은 컴퓨터 프로그램을 학습시키는 기계 학습 모델을 사용해서, 데이터를 분석하고 이를 기반으로 일을 자동으로 할 수 있게 만들어져
하던 이야기를 연결해서 계속 해주세요
이야기를 계속 해드리겠습니다.
아이들은 로봇이 설명한 AI의 마법이 놀라웠고, 그들은 더 알고 싶어해졌습니다. 그래서, 로봇은 아이들을 데리고 인공 지능 박물관으로 가서, 다양한 인공 지능 기술을 보여주었습니다.
아이들은 놀라운 인공 지능 기술들을 보고 기뻐하고, 로봇이 어떻게 그들의 질문에 답하고, 놀이를 잘하는지에 대해 자세히 알아보았습니다.
그리고 아이들은 로봇이 어떻게 기계 학습 모델을 사용해서 학습을 하는지도 알고 싶어해졌습니다. 로봇은 아이들을 위해 기계 학습 모델을 설명해주고, 아이들이 기계 학습을 시뮬레이션해볼 수 있는 실험을 해보았습니다.
OpenAI에서 발표한 Exploration에 대한 논문. 18년도까지 여러 강화학습 알고리즘이 있었지만 Reward가 Sparse 한 환경인 몬테주마의 복수에서 인간의 성능을 최초로 넘은 방법이다.
Abstract
이 논문에서 강화학습을 휘한 Exploration bonus를 소개한다.
이 Exploration bonus는 적용하기 쉽고, 동작하는데 최소의 오버헤드가 든다.
이때 bonus는 고정되고 랜덤하게 초기화된 네트워크로부터 얻은 관측(observations)의 특징(feature)을 예측하는 신경망의 에러를 말한다.
intrinsic and extrinsic reward를 적절하게 결합하여 사용한 flexibility에 대한 method를 소개한다
이 알고리즘을 통해 몬테주마의 복수에서 SOTA를 달성하였고 인간의 성능을 뛰어넘게 된 첫 번째 방법으로 의의를 가진다.
1. Introduction
기존의 제한 사항들
강화학습은 Policy의 반환값(return)의 기댓값을 극대화하도록 동작한다. 보상(reward)가 밀집된(dense) 한 경우, 대체적으로 잘 학습한다. 하지만보상이 뜨문뜨문한(sparse) 경우, 학습시키기 어렵다.
실제 세계에서도 모든 보상들이 밀집된 경우는 드물다. 따라서 보상이 드문 경우에도 잘 학습하기 위한 방법이 필요하다.
18년 당시 RL에서는 어려운 문제들을 풀기 위해 환경을 병렬적으로 크게 만들고 경험들을 샘플링하여 얻었지만 이러한 방법은 당시에 소개된 exploration 방법들에 대해서는 적용하는데 어려움이 있었다.
제시하는 것
간단하고 고차원의 관측에서도 잘 동작하는 Exploration bonus를 소개한다.
이 알고리즘은 policy optimization과 함께 적용할 수도 있고, 계산 효율적이기도 하다.
아이디어
유의미한 이벤트가 발생할 때 내부 보상이 높은 것을 볼 수 있다. (2, 8, 10, 21) 은 life를 잃을 때, (3, 5, 6, 11, 12, 13, 14, 15)는 적을 아슬아슬하게 피할 때, (7, 9, 18) 은 어려운 장애물을 피할 때, 그리고 (19, 20, 21) 은 아이템을 습득할 때
이 논문에서 제시된 Exploration bonus는 신경망에서 학습된 것들과 유사한 예들에 대해서 prediction error가 현저하게 낮은 것에서 아이디어를 얻었다.
새로운 경험들의 참신함을 측정하기 위해, 에이전트의 과거 경험들에 대해 학습한 네트워크의 prediction error를 사용하였다.
prediction error를 극대화하는 것의 문제이전에 많은 저자들이 지적했듯이 prediction error를 최대화하는 에이전트의 경우는 prediction problem의 답이 입력의 확률적 함수인 transition 들에 대해 끌리게 된다.
예를 들어 Noise TV 와 같은 예가 있다. 현재 obsevation에서 다음 observation을 예측하는 prediction problem이 있고, 이때 에이전트가 prediction error를 극대화하도록 행동한다면, 확률적 전환(stochastic transitions)을 찾도록 하는 경향이 있다.
그 예로 무작위로 변하는 아래와 같은 화면인 Noise TV와 무작위로 동전을 던지는 이벤트와 같은 것들이 있다.
문제를 극복하기 위한 대안
논문의 저자들은 적절하지 않은 stochasticity에 대한 대안을 제시한다. 답이 그것의 입력에 deterministic function인 prediction problem을 exploration bonus으로 정의하면서 대안으로 제안한다.
대안으로는, 현재 Observation에 대해서 output을 fixed randomly initialized network를 사용해서 예측한다는 것이다.
강화학습에서 어려운 게임들 🤦♂️
Bellemare의 2016년 논문에서 보상이 드물고 탐색이 어려운 게임들을 확인했다. 그 게임들로는 Freeway, Gravitar, Montezuma's Revenge, Pitfall, Private Eye, Solaris, Venture 들이 있고, 어떤 경우에서는 단 하나의 긍정보상도 찾지 못했다.
그중에서도 어려운 몬테주마의 복수
몬테주마의 복수는 강화학습에서 어려운 게임으로 여겨진다. 게임에서 치명적인 장애물을 피하기 위해 다양한 게임 스킬들에 대한 조합들이 필요하고, 최적의 플레이를 하면서도 보상이 수백 스텝 이상 떨어져 있기 때문에, 보상을 찾기에 어려운 과제로 여겨진다.
몇 논문들에서 꽤 좋은 성과를 거두었지만, expert demonstrations와 emulator state에 대한 접근 없이는 가장 좋은 성과가 전체 방의 절반만 찾아내었다.
논문에서 발견한 것 🔍
extrinsic reward 없는 경우
extrinsic reward를 무시하여도 agent가 RND exploration bonus를 극대화하도록 한다면 일관되게 몬테주마의 복수 게임에서 절반 이상의 방을 찾았다.
서로 다른 보상(reward)에 대해 서로 다른 discount rate를 사용하고, episodic과 non-episodic 반환값(return)을 결합한다.
성과
first level에서 종종 몬테주마 게임에서 24개의 방 중에서 22개를 찾았고, 이따금씩 클리어하기도 했다. 그리고 같은 방법으로 Venture와 Gravitar에서 SOTA를 달성하였다.
Venture
Gravitar
2. Method
2.1 Exploration Bonuses
1) Count-Based
2.2 Random Network Distillation
2.2.1 Source of Prediction Errors
일반적으로 prediction error 들은 아래 요소들로부터 나온다.
1. Amount of training data
predictor가 전에 학습한 example 들과 다를수록 prediction error가 높다
2. Stochasticity
target function이 확률적이기 때문에 prediction error가 크다. stochastic transition들은 forward dynamic prediction과 같은 에러들의 원인이다.
3. Model misspecification
필요한 정보가 부족하거나 모델이 target funtion의 복잡도에 맞추기 위해 제한적인 경우
4. Learning dynamics
predictor가 target funtion을 근사하는 과정에서 최적화를 실패했을 때,
2번째 요소는 noisy TV 문제를 야기하고 3번째 요소도 적절하지 않기 때문에 RND에서는 요소 2,3을 제거한다. 3 since the target network can be chosen to be deterministic and inside
the model-class of the predictor network.
2.2.2 Relation to Uncertaionty Quantification
RND의 prediction errror는 불확실한 것을 수량화하는 것과 관련이 있다.
2.3 Combining Intrrinsic and Extrinsic Return
2.4 Reward and Observation Normalization
reward
prediction error를 exploration bonus로 사용하는 것이 보상의 크기가 환경에 따라, 시간에 따라 크게 다르기 때문에 모든 환경에서 동작하는 하이퍼파라미터를 찾는 것은 어려운 부분이 있다.
일정한 크기의 reward를 유지하기 위해서 intrinsic reward를 intrinsic reward의 표준편차들에 대한 추정치로 나누어 주어 normalization 과정을 거친다.
observation
랜덤 신경망을 사용할 때는 파라미터들이 고정되고 다른 데이터 셋들에 대해서도 조정되면 안 되기 때문에 observation normalization이 중요하다. normalization이 부족하면 임베딩의 분산이 극단적으로 낮아지고 입력에 대한 정보가 조금만 전달되는 결과가 발생할 수 있다.
이러한 문제를 해결하기 위해 continuous control 문제에서 사용하는 observation normalization scheme을 사용하고, 각 dimension에 running mean을 빼고 running standard deviation을 나누어 값을 normalization.
그 후 값이 -5와 5사이에 오도록 잘라준다.
predictor와 target network는 동일한 obsevation nomalization, policy network에 대해서는 사용하지 않는다.
1. State의 feature를 뽑기 위한 Network를 랜덤으로 초기화 시키고 고정시킵니다. (Target Network, 이 네트워크는 학습하지 않습니다)
2. Target Network와 똑같은 구조를 가지는 네트워크를 초기화 시키고 (Predictor Network), Target network에서 나온 state의 feature와 이 predictor network에서 나온 feature의 차이가 최소화 되도록 학습시킵니다.
즉, predictor network를 Target Network 화 시키는 거죠. 그리고 그때 state의 차이를 Intrinsic reward로 정의합니다. 결국 다음 state의 feature space가 predictor network가 잘 예측하지 못한 state라면 더 많은 reward를 주게 되는 것이죠.
예측한 다음 state와 실제 다음 state의 차이를 intrinsic reward로 정의하는 것은 일반적인 curiosity 모델의 컨셉과 같습니다.
그러나 기존의 curiosity 모델은 현재 state와 action을 통해 다음 state를 "예측해야만" 했다면, RND는 실제 다음 state를 가지고 "feature만을 추출"합니다. 즉, 예측을 잘 해야 할 필요가 없는 것이죠.
그러므로 RND의 predictor model을 stochastic 한 게 아니라 deterministic 하게 되는 것입니다.
랜덤으로 초기화시키고 고정시킨 target network 또한, feature를 예측하는 것이 아니라, 추출의 목적이 있기 때문에 굳이 학습 시킬 필요가 없습니다.
어차피 비슷한 state에 대해서는 비슷한 output feature를 내뱉게 됩니다.
Target network의 output을 predictor network로 학습을 시키면 결국 predictor network는 target network와 비슷한 모델이 되어갑니다.
하지만 episode 과정 중에 계속 보았던 state에 대해 학습이 되기 때문에, 이전에 보았던 state에 대해서 overfitting 되게 되고, 보지 않았던 새로운 state를 보게 된다면, target network의 output 과는 조금 다른 output을 내게 됩니다.
즉, 새로운 state를 찾아가면서 하는 행동에 대해서는 reward를 많이 줄 수 있게 되는 것이죠.
이때, predictor network와 target network가 완전히 동일하게 돼서 무조건 같은 output을 내지 않을까 하는 의문이 들 수도 있습니다만, MNIST 데이터를 학습시키는 CNN 모델만 생각해도 완전히 overfitting 되는 열 개의 모델을 만들어도 각기 NN의 weight는 다르다는 것을 생각해 보면 직관적으로 절대 같아질 수 없다는 것을 이해할 수 있습니다.
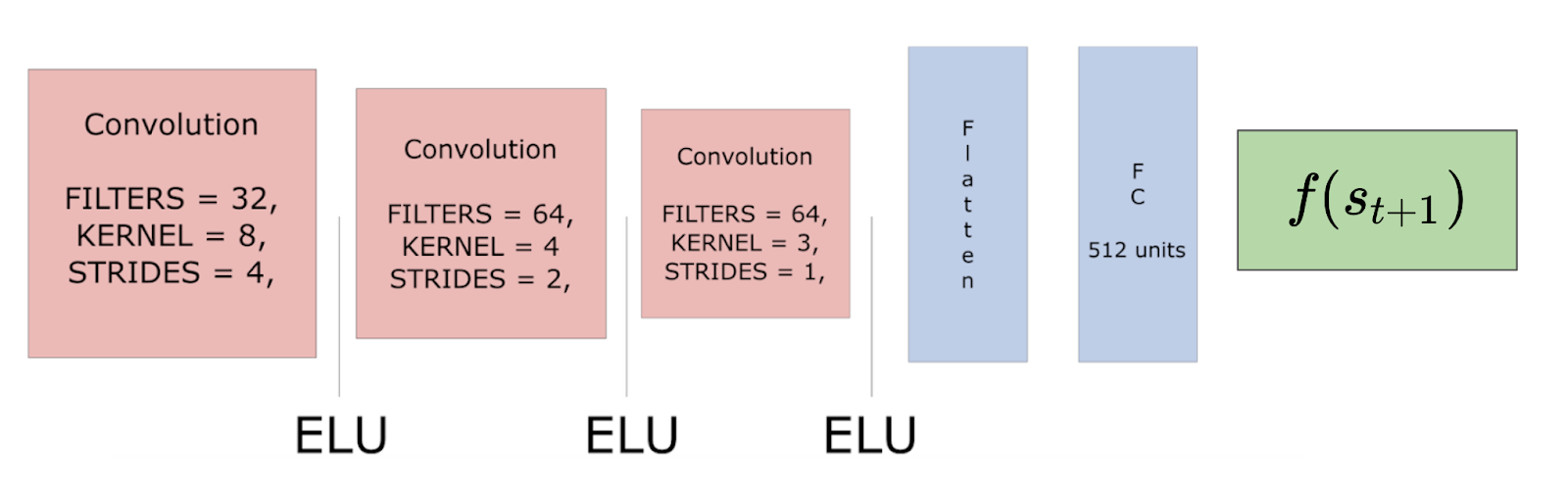
Predictor: A series of 3 convolutional layers and 3 fully connected layers that predict the feature representation of s(t+1).
Target: A series of 3 convolutional layers and 1 fully connected layer that outputs a feature representation of s(t+1).
Combining Intrinsic and Extrinsic Returns
In ICM, we used only IR — treating the problem as non-episodic resulted in better exploration because it is closer to how humans explore games. Our agent will be less risk averse since it wants to do things that will drive it into secret elements.
Two Value Heads
Our new PPO model needs to have two value function heads: because extrinsic rewards (ER) are stationary whereas intrinsic reward (IR) are non-stationary, it’s not obvious to estimate the combined value of the non-episodic stream of IR and episodic stream of ER.
The solution is to observe that the return is linear i.e R = IR + ER. Hence, we can fit two value heads VE and VI and combine them to give the value function V = VE + VI. Furthermore, the paper explains that it’s better to have two different discount factors for each type of reward.
15개의 검은 말이 모두 16번으로 이동한 후 빠져나오면 검은 말이 이기고, 빨간 말이 1924로 이동한 후 먼저 빠져나와면 빨간 말이 이깁니다.
주사위를 굴려 나온 수만큼 한 개의 말을 이동시킬 수 있습니다. 주사위는 2번 던져 서로 다른 말에 적용시킵니다. 하지만 24번의 검은말 하나가 주사위 5가 나와 빨간말로 꽉 찬 19번으로 이동할 수 없습니다. 막는 것이 일종의 전략이 될 수 있습니다.
또한 빨간말이 하나뿐이라면 검은 말이 빨간 말을 잡을 수 있습니다.
잡은 말은 바깥에 두었다가 처음 위치에서 다시 시작해야 합니다.
서로 다른 상태가 10^20개 이상 있으므로 근사 가치함수를 사용합니다.
은닉층이 하나인 MLP를 사용하였고,
검은 말, 빨간 말이 놓인 위치를 표현하기 위해 24개 위치 각각에 노드를 4개씩 배정하였습니다.
2 * 24 * 4 = 192개의 노드가 사용됩니다.
또한 시간차 알고리즘을 사용해서 TD-gammon이라 불립니다.(Tesauro, 1995)
TD-gammon은 사람의 전략을 가르쳐 주지 않은 채 프로그램 2개가 겨루는 과정에서 학습하는 self-play 방식입니다.
승패의 여부에 따라 상태에 +1, -1 보상을 부여하고 보상이 TDL 알고리즘을 통해 이전 상태로 파급됩니다.
TD-gammon은 지도학습을 전혀 이용하지 않고 자가 플레이로 세계 챔피언 수준에 도달하였습니다.
강화학습과 보드게임
틱택토(tic-tac-toe), checkers, 체스, 장기, 바둑입니다.
보드게임을 가장 잘하기 위한 강화학습 연구가 진행되었고 가장 어려운 바둑에서 세계 챔피언 수준의 이세돌을 4:1로 이기는 성과를 기록합니다.
틱택토는 상태의 수가 3^9=19,6833^9=19,683 정도로 근사 가치함수를 사용하지 않더라도 쉽게 최적 정책을 알아낼 수 있습니다.
틱택토는 새로운 프로그램을 테스트하는 용도로 자주 쓰입니다.
checkers는 열약한 하드웨어에서도 체커 게임을 해결하는 시도를 하였습니다.(Samuel, 1959)
체스는 Deepblue라는 프로그램이 세계 챔피언을 이겼습니다.(Campbell, 2002)
당시 VLSI칩은 딥블루라는 슈퍼컴퓨터로 발전하였고, 당시에는 기계 학습 알고리즘보다 하드웨어 속도를 향상시켜 높은 수준을 달성하였습니다. 장기도 이와 마찬가지입니다.
바둑은 훨씬 탐색 공간이 커서 고성능 하드웨어에도 한계가 있었습니다. alphago는 몬테카를로 트리탐색, 프로기사들의 기보를 활용한 지도학습, self-play를 활용한 강화학습, CNN 적용, 고성능 하드웨어와 결합하여 세계 챔피언을 이길 수 있었습니다.(Silver, 2016)
2) DQN: Atari video game
므니 등은 Atari 2600 게임 49종에서 자동으로 플레이하는 프로그램을 개발하였습니다. (Mnih et al., 2015)
다양한 게임 해서 동일한 입력, 신경망 구조, 하이퍼 파라미터를 사용하여 전문 플레이어 수준을 달성하였습니다. 29종에서 좋은 성능을 보였습니다.
CNN과 Q-Learning을 결합한 DQN으로 상태를 입력하고, 게임 종류마다 필요한 만큼 출력 노드를 정합니다.