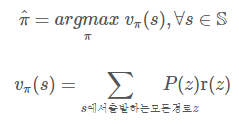훈련 집합으로 상태, 행동->보상을 학습하여 입력 상태에 따라 최대의 보상이 기대되는 행동을 선택한다.
정책 : 현재 상태에서 최대의 가치를 주는 상태로 가는 행동을 선택하는 것
가치 : 상태 최대 기대 보상 값
최대한 넓게 깊게(많은 샘플링) 탐색한다.
(행동선택) 정책 모델로 넓게를 효율적으로
(가치 예측) 가치 모델로 깊게를 효율적으로
동적 프로그래밍 vs. 몬테카를로 방법

동적 프로그래밍에서는 r(z)를 직접 추정할 수 없어서 순환식을 사용했지만,
몬테카를로 방법은 샘플을 만들어 이를 직접 계산합니다.
또한 몬테카를로 방법에서는 어떤 상태가 자신에 속한 샘플만 가지고 자신의 값을 결정할 수 있으므로, 특정 상태만 골라 가치 함수를 계산하여 시간을 줄일 수 있는 장점이 있습니다.
훈련 데이터 수집 방식
1. 현장 샘플링 -> 훈련 집합
2. 시뮬레이션(환경, 에이전트(정책)) -> 에피소드 -> 샘플링 -> 훈련 집합
3. 불완전 모델 정보 -> 샘플 생성 -> 훈련 집합
훈련 데이터 형식
1. Z(s) 집합 = 상태 샘플
2. Z(s, a) 집합 = 상태-행동 샘플
정책 π 평가(policy evalutation)
정책 π 평가 = 가치 함수(π) = vπ = 샘플의 평균
Z(s)를 이용한 상태 가치 함수
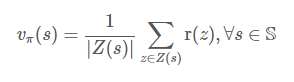
Z(s, a)를 이용하여 상태-행동 가치 함수

정책 반복
for 정책
for 가치
for 정책
가치 반복
for 가치
for 상태
최적 정책 탐색
- 모델(MDP, P(s',r|s,a))이 있는 경우: max가 되는 행동을 찾아 정책으로 변환합니다.
- 모델이 없는 경우: Z(s, a)를 사용하여 탐험, 탐사 조절
탐험과 탐사 조절
- 오프라인(offline) 방식
- 충분히 큰 훈련 집합 Z를 한꺼번에 수집합니다.
- 지역 최적점을 구하는 것을 걱정할 필요가 없습니다.
- 온라인(online) 방식
- 알고리즘 수행하면서 에피소드를 발생시킵니다.
- 어떤 상태에 우연히 열등한 행동이 먼저 발생했다면 이후 그 행동만 선택할 가능성이 커져
지역 최적점으로 조기 수렴(premature convergence) 현상이 나타날 수 있습니다.
이에 따라 온라인 방식에서는 탐험을 강제할 기법이 추가되어야 합니다.
1) 탐험형 시작(exploring starts) : 에피소드 생성 시 모든 상태-행동 쌍이 골고루 발생하도록 배려
2) ϵ-soft : 주류에서 벗어난 상태-행동에 일정한 확률을 배정하여 선택될 가능성 열기
Monte-Carlo method 특성
1) 환경 모델이 없어도 됩니다. (샘플링)
2) bootstrap 방식이 아니므로 관심 있는 상태만으로 구성된 부분집합으로 최적 가치와 최적 정책을 추정할 수 있습니다.
3) Markov property에서 크게 벗어나는 상황에서도 성능 저하가 적습니다. 시작부터 종료까지 정보를 포함하여 에피소드를 충분히 많이 사용하여 학습하기 때문입니다.
[RL] 강화학습 part2 - Dynamic programming, Monte Carlo Method
3. 동적프로그래밍
Dynamic programming 강화학습에서 사용하는 고전적인 방법입니다.
MDP 확률분포가 주어지고, 상태, 행동 개수가 적어 계산 시간과 메모리 요구량이 현실적이어야 구현이 가능합니다.
알고리즘 교과서에서 배우는 동적 프로그래밍은 결정론 문제를 풀도록 설계되어 있으므로, 강화학습에 적용할 수 없습니다.
강화학습은 스토캐스틱 동적 프로그래밍을 사용합니다.
1) 정책 반복 알고리즘
평가 : 현재 정책에서 가치함수 계산
개선 : 가치함수를 이용해 정책을 갱신
정책 반복 알고리즘(policy iteration)은 평가 개선 사이클을 최적 정책을 찾을 때까지 반복합니다.
이때 평가단계는 여러 번 반복하여 개선된 가치함수가 이전보다 좋아야 하므로 많은 시간이 소요 됩니다. 따라서 상태의 개수가 많은 현실 문제에는 적용할 수 없는 단점이 있습니다.
2) 가치 반복 알고리즘
value iteration
입력인 MDP를 보고 최적 가치함수를 찾은 후, 그로부터 최적 정책을 찾습니다.


line 6에서 계산한 가치함수는 장기 이득을 내포하고 있으므로, 순간 이득에 머물지 않습니다.
위 알고리즘은 반복할 때마다 가치함수를 저장하는 메모리를 별도로 사용합니다. 따라서 그대로 구현하면 메모리 사용이 과다해집니다. 하지만 알고리즘은 현재 - 다음 단계의 2개의 배열만 정의하고 이것을 번갈아 사용함으로써 이 문제를 조금 줄이는 효과가 있습니다.
line 13에서 확률을 배분할 때는 A(s) 안의 원소 개수 n 만큼 나누어 1/n씩 공정하게 해도 좋고, 또는 다른 방식으로 모든 합이 1이 되게 배분하면 됩니다. 이 행동 중 어느 것을 취하든 최적을 보장하기 때문입니다.
정책 반복과 가치 반복 알고리즘은 다른 상태 값을 보고 자신의 값을 갱신하는 부트스트랩(bootstrap) 방식입니다.

수렴하기 이전까지는 모든 상태가 불완전한 상황입니다.
추측 과정에서 MDP는 정확한 보상 값을 제공하고, 보상이 점점 정확한 추측 값에 근접하여 최적점에 도달합니다.
부트스트랩 방식은 모든 상태가 이전 값을 이용해 현재 값을 계산하여야 공평하므로, 하나의 배열만 가지고 갱신하는 제자리(in-place) 연산이 불가능하고, 2개의 배열을 필요로 합니다.
하지만, 제자리 연산으로 구현해볼 수도 있습니다. 이는 비록 공평성은 무시하지만 최적으로 수렴만 할 수 있다면 문제 될 것이 없습니다. 또한 실제 여러 실험에 따르면 제자리 연산을 통해 수렴 속도가 빨라지는 장점이 있는 것으로 밝혀졌습니다.
위 가치 반복 알고리즘에서 v(t+1)(s)를 하나의 v(s)로 표현하고 각 상태를 계산하자마자 대치해 주면 됩니다.
정책 반복은
for 정책
for 가치
for 정책
3중 for 문 구조이지만,
가치 반복은
for 가치
for 상태
2중 for 문 구조로 가치 반복이 더 빠릅니다.
하지만 상태공간이 방대한 백가몬(backammon)과 같은 응용에서 여전히 계산이 불가능합니다.
4. 몬테카를로 방법
MDP에 대한 완벽한 지식은 없지만, 불완전한 모델 정보로부터 샘플을 생성할 수 있거나, 에이전트와 환경에서 직접 샘플을 수집할 수 있다면 샘플을 훈련 집합으로 하여 최적 정책을 찾아낼 수 있습니다.
훈련 집합(train set)을 사용하여 학습에 기반을 둔 몬테카를로(Monte Carlo)방법을 설명합니다.
1) 훈련집합 수집과 정책 평가
적절한 방법으로 에피소드를 수집했다고 가정합니다.
예를 들어 바둑에서는 게임 시작부터 종료까지 기록, 즉 기보 하나를 에피소드로 사용할 수 있습니다.
에피소드 e를 다음 식으로 표현합니다.
e = [s0,r0]a0 [s1,r1]a1 ⋯[st,rt]at ⋯[sT,rT]
한 에피소드로부터 샘플을 여러 개 수집할 수 있습니다.
방법은 두 가지가 있습니다.
첫 방문(first visit): 상탯값이 여러 번 발생하면 최초 발생만 인정
모든 방문(every visit): 전부 인정
예제를 들어봅시다.
e = [10,0]동[11,0]북[7,0]남[11,0]서[10,0]서[9,0]북[5,0]북[1,5]
상태 10은 t=0, t=4 두곳에서 나오므로
first visit에서는 t=0만 인정하여 수집하므로
Z(10) = [10,0]동[11,0]북[7,0]남[11,0]서[10,0]서[9,0]북[5,0]북[1,5]
입니다.
every visit에서는 t=0, t=4 둘다 모두 수집하여
Z(10) = [10,0]동[11,0]북[7,0]남[11,0]서[10,0]서[9,0]북[5,0]북[1,5] , [10,0]서[9,0]북[5,0]북[1,5]
가 됩니다.
샘플은 몬테카를로 방법을 사용하기 위해 Z(s)에 추가됩니다.
몬테카를로 방법은 주로 환경 모델에 대한 완벽한 확률분포 없이 수행되는데,
상태만으로 최적 정책을 추정할 수 없어 상태-행동 정보가 필요합니다.
따라서 상태-행동 샘플을 수집하여 Z(s, a) 집합을 구해야 합니다.

에피소드는 실제 현장 수집 또는 시뮬레이션으로 생성합니다.
알파고를 만든 DeepMind는 KGS 바둑 서버에서 16만 개의 기보에서 3천만 개의 샘플을 수집해 알파고를 학습하였습니다. (Silver, 2016)
경기당 평균 184수까지 둔 꼴이며, T=184인 셈입니다. 알파고는 자신 복제 프로그램 2개를 대결하게 하여 샘플을 수집하기도 했습니다.
시뮬레이션은 환경 모델을 활용합니다. 모델의 확률분포 P(s', r | s, a)가 주어진 경우 확률분포에 따른 난수를 이용하여 쉽게 생성할 수 있습니다.
정책 평가(policy evalutation)
정책 π를 평가, 즉 π에 해당하는 가치함수를 추정하는 일은 아주 쉽습니다.
샘플의 평균으로 vπ를 추정합니다.


위 식은 Z(s)를 이용하여 상태 가치함수를 추정,
아래 식은 Z(s, a)를 이용하여 상태-행동 가치함수를 추정합니다.

동적프로그래밍 vs. 몬테카를로 방법

동적 프로그래밍에서는 r(z)를 직접 추정할 수 없어서 순환식을 사용했지만,
몬테카를로 방법은 샘플을 만들어 이를 직접 계산합니다.
또한 몬테카를로 방법에서는 어떤 상태가 자신에 속한 샘플만 가지고 자신의 값을 결정할 수 있으므로, 특정 상태만 골라 가치함수를 계산하여 시간을 줄일 수 있는 장점이 있습니다.
2) 최적 정책 탐색
모델(MDP, P(s',r|s,a))이 있는 경우: max가 되는 행동을 찾아 정책으로 변환합니다.

모델이 없는 경우: Z(s, a)를 사용하여 탐험, 탐사 조절합니다.
탐험과 탐사 조절
오프라인(offline) 방식 : 충분히 큰 훈련집합 Z를 한꺼번에 수집합니다. 지역 최적점을 구하는 것을 걱정할 필요가 없습니다.
온라인(online) 방식 : 알고리즘 수행하면서 에피소드를 발생시킵니다. 어떤 상태에 우연히 열등한 행동이 먼저 발생했다면 이후 그 행동만 선택할 가능성이 커져 지역 최적점으로 조기 수렴(premature convergence) 현상이 나타날 수 있습니다.
이에 따라 온라인 방식에서는 탐험을 강제할 기법이 추가되어야 합니다.
1) 탐험형 시작(exploring starts) : 에피소드 생성 시 모든 상태-행동 쌍이 골고루 발생하도록 배려
2) ϵ-soft : 주류에서 벗어난 상태-행동에 일정한 확률을 배정하여 선택될 가능성 열기
Exploring starts
여기서의 예는 상태-행동 데이터 Z(s, a)를 훈련집합으로 사용하는 버전입니다.
탐험형 시작은 상태가 가질 수 있는 값과 행동이, 가질 수 있는 값의 모든 조합이 0보다 큰 발생 확률을 갖게 하여 한 번도 시도되지 않은 조합을 배제하는 전략입니다.

ϵ−soft
가능한 모든 상태-행동 쌍이 골고루 발생하도록 배려하는 방침이 반영되었습니다.
line 12가 핵심인데, 최적행동으로 선택되지 못한 나머지 행동에 작은 확률을 배분하여 현재 최적이 아니더라도 선택될 가능성을 열어 정책 개선에 공헌을 할 수 있도록 합니다.

Monte-Carlo method 특성
1) 환경 모델이 없어도 됩니다. (샘플링)
2) bootstrap 방식이 아니므로 관심 있는 상태만으로 구성된 부분집합으로 최적 가치와 최적 정책을 추정할 수 있습니다.
3) Markov property에서 크게 벗어나는 상황에서도 성능 저하가 적습니다. 시작부터 종료까지 정보를 포함하여 에피소드를 충분히 많이 사용하여 학습하기 때문입니다.
Reference
기계학습, 오일석, 2017, 09. 강화학습

'머신러닝' 카테고리의 다른 글
| 강화학습 - DQN (0) | 2021.01.18 |
|---|---|
| 강화학습3 - Temporal Difference Learning (0) | 2021.01.17 |
| 강화학습 (0) | 2021.01.15 |
| 이미지 객체 검출 YOLO, DETR (0) | 2020.12.03 |
| kaggle, dacon, google colab, tensorflow, torch, 머신러닝 기초 입문 (0) | 2020.11.27 |