반응형
배울 점이 많은 강의가 있어서 추천드리며, 시리즈로 글을 쓰고자 합니다.
비정형 데이터 분석 10/11 #Transformer
키워드 및 핵심 내용
Transformer
Seq2Seq(Encoder + Decoder) 구조이지만 Attention을 활용한 병렬 처리 가능
Incoder 구조
Input Embedding -> Positional Encoding -> Multi-Head Attention(+정규화) -> Feed Forward(+정규화)
Positional Encoding : sin, cos 함수 이용
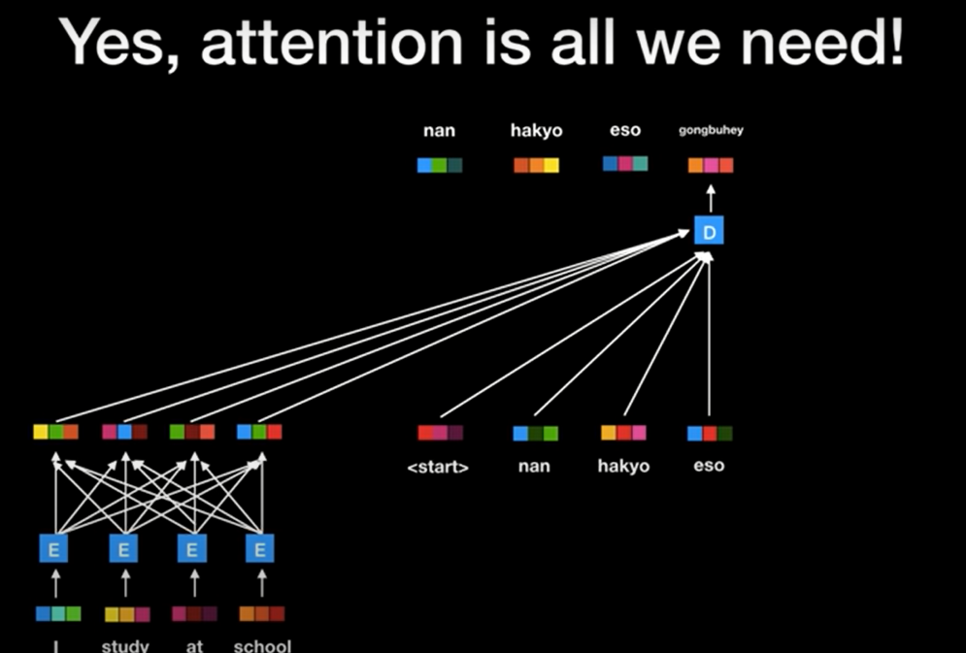
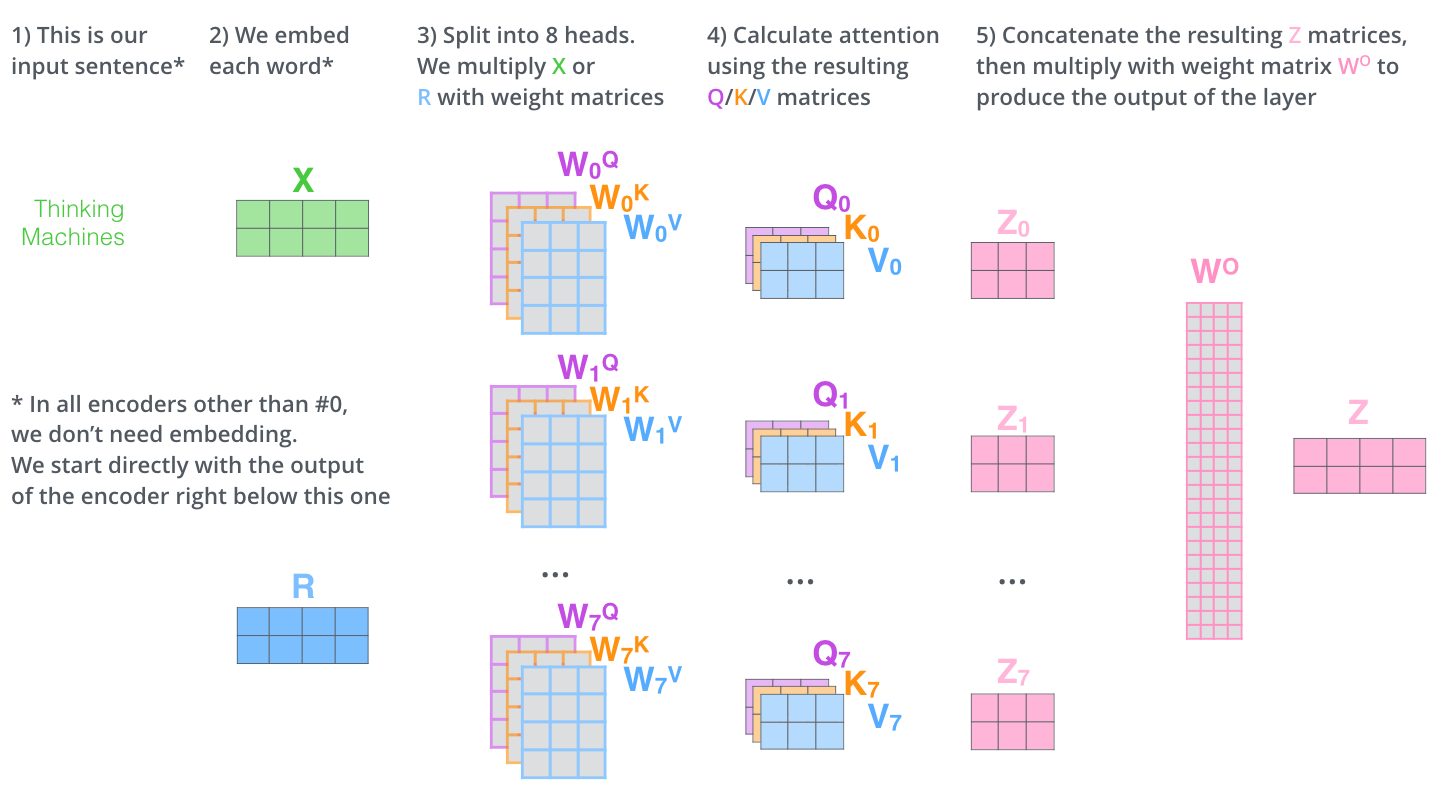
Attention(q, k, v) -> Multi-Head Attention (Wq, Wk, Wv) -> Wz
[Transformer 추가 자료]
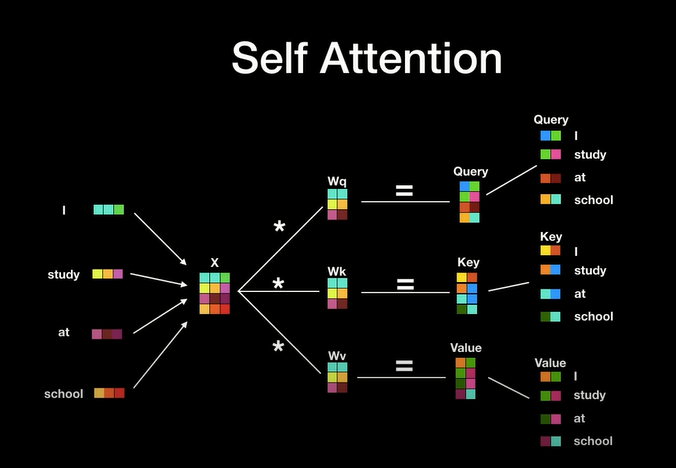
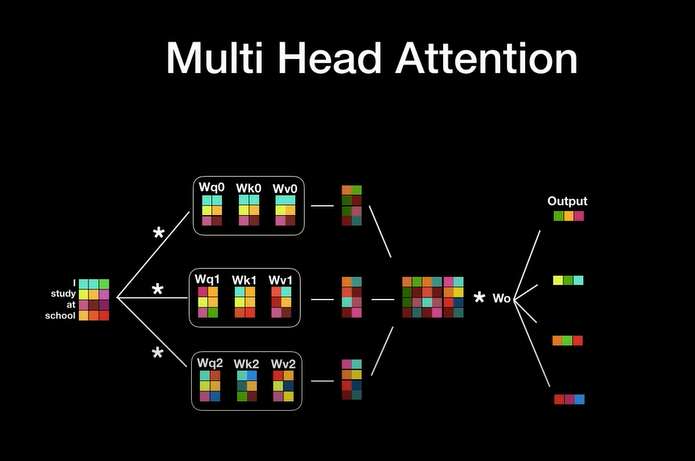
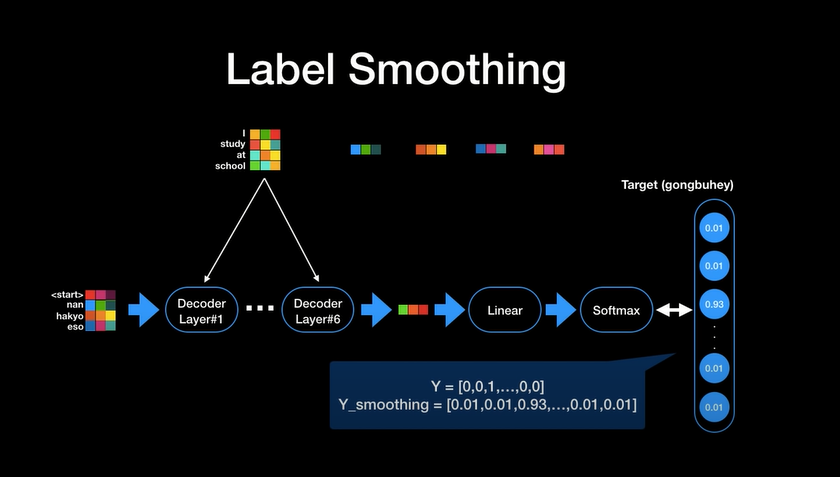
[Transformer 추가 자료]
https://nlpinkorean.github.io/illustrated-transformer/
전체구조
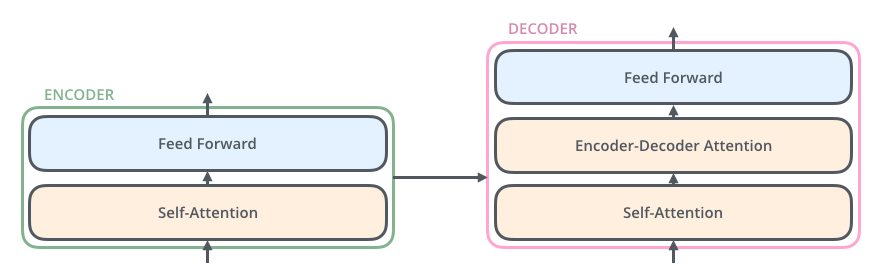
Encoder
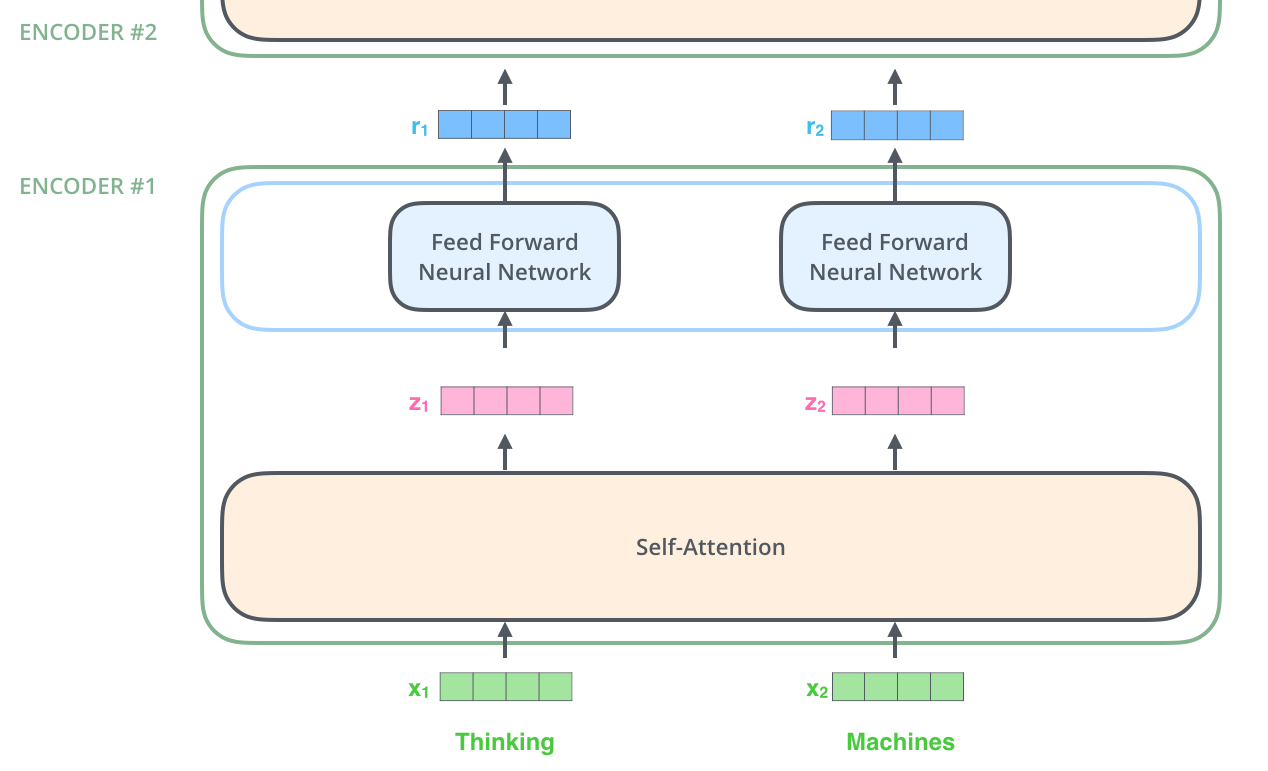
self-attention
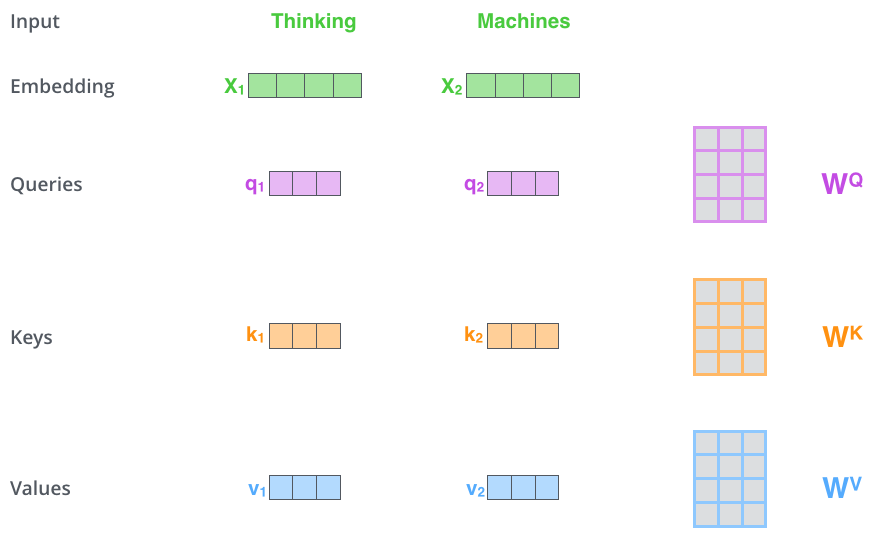
self-attention의 계산 과정
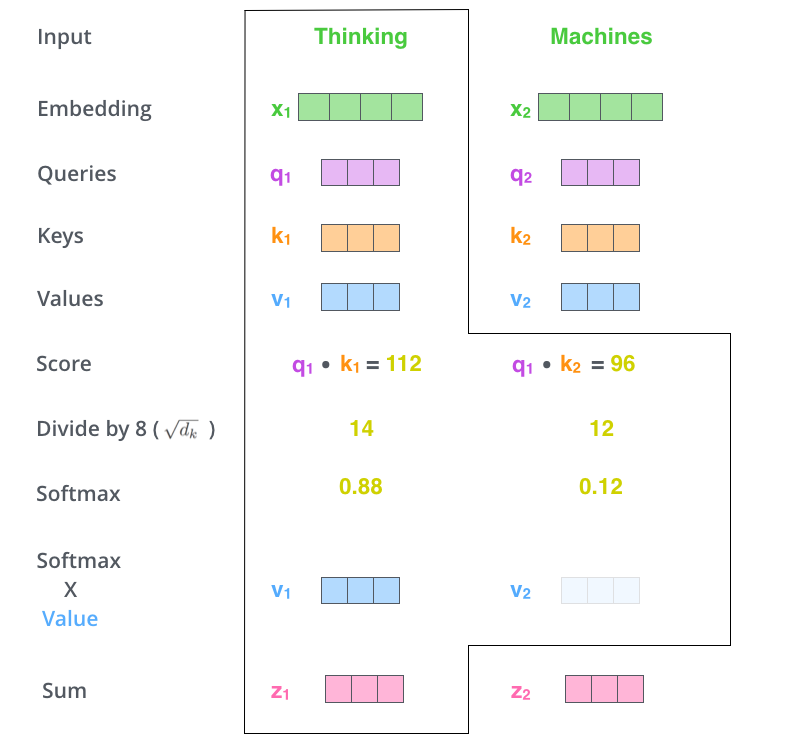
multi-headed self-attention
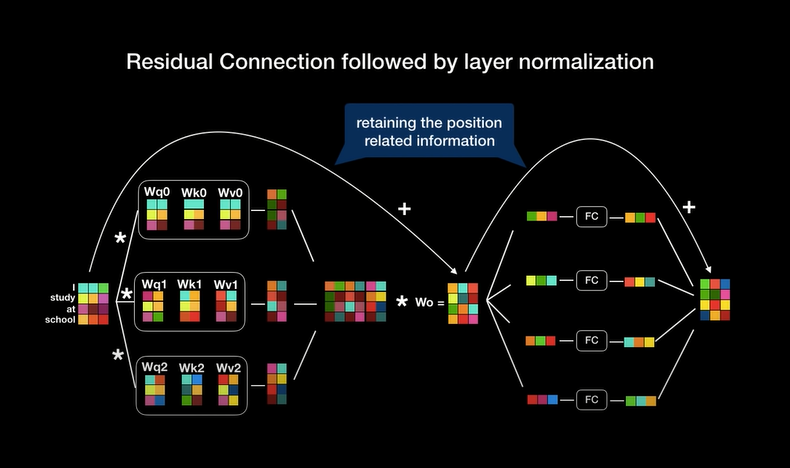
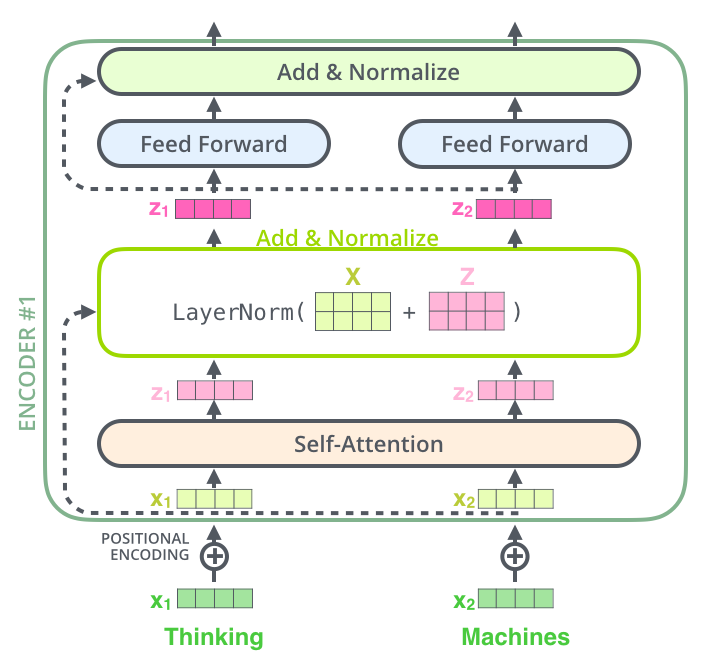
Encoder layer-normalization 과정
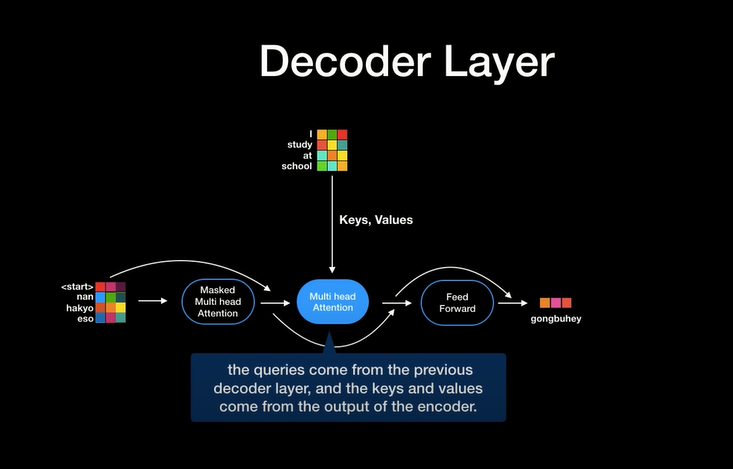
Decoder
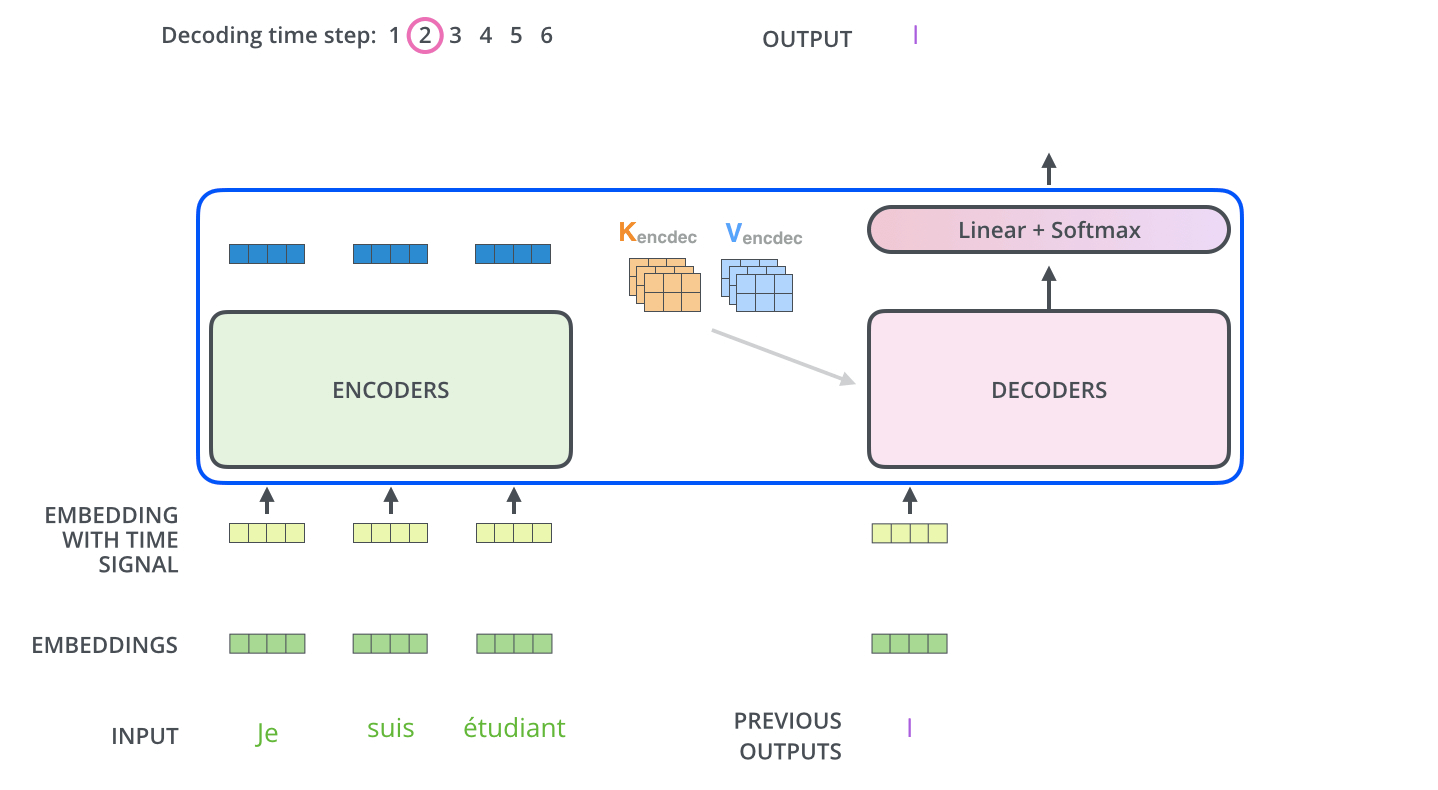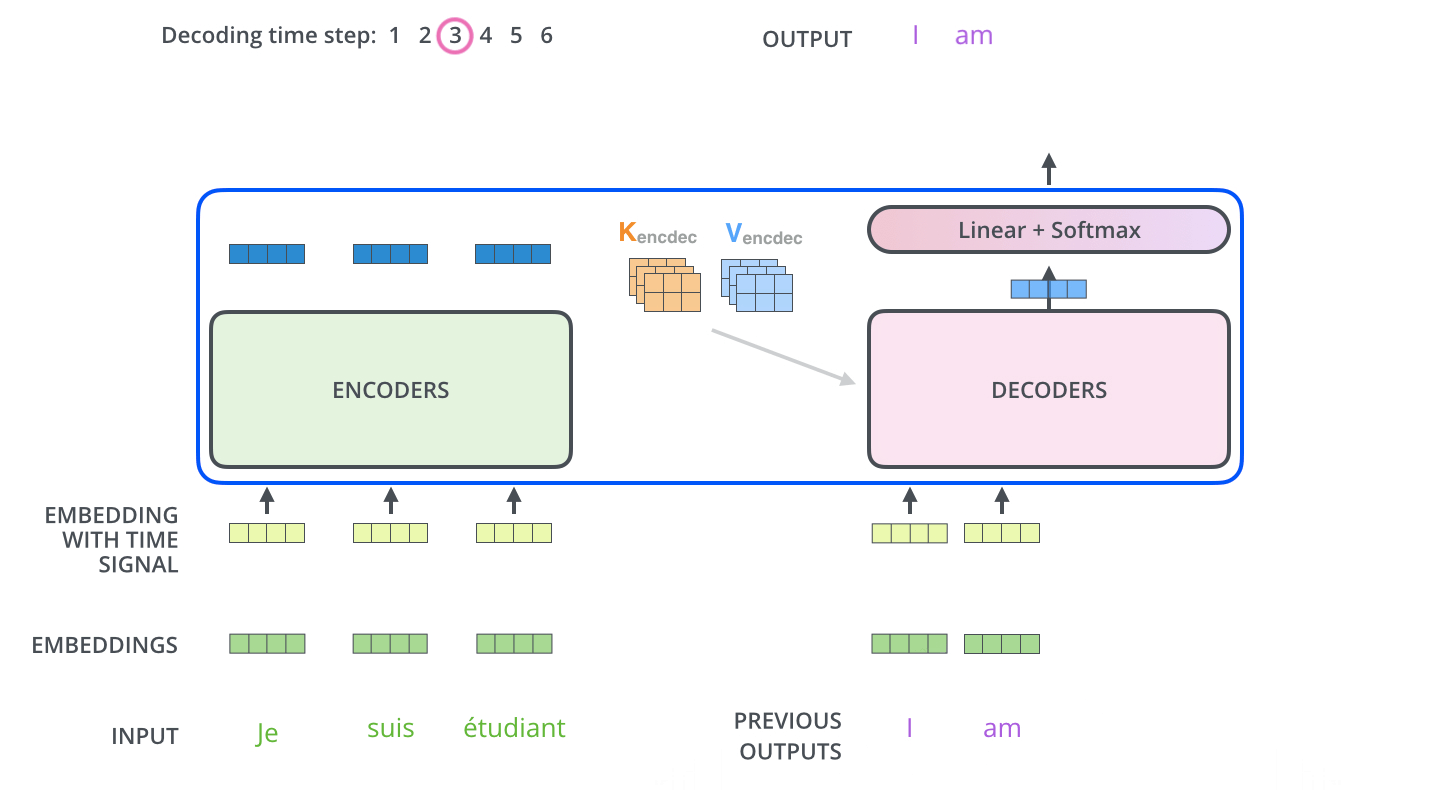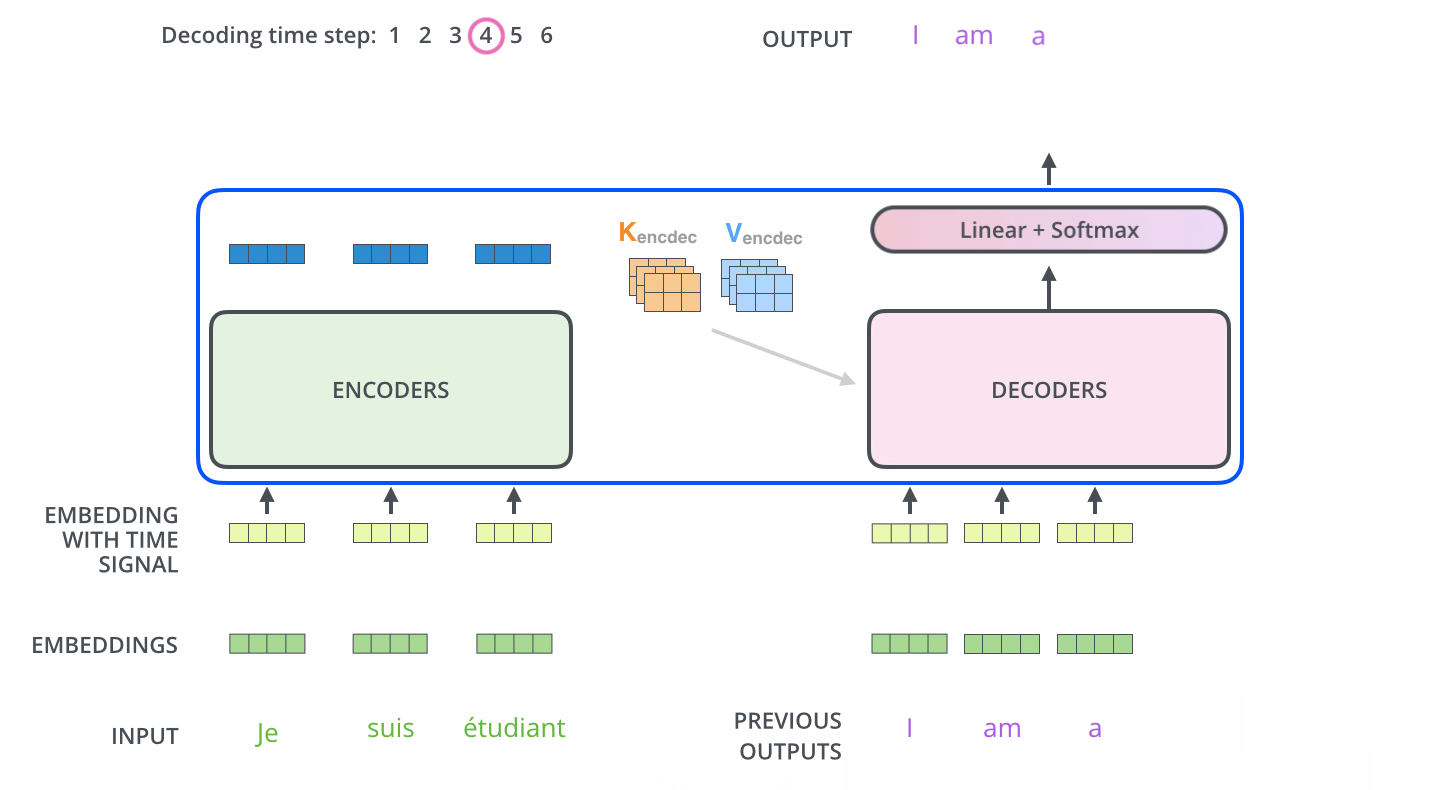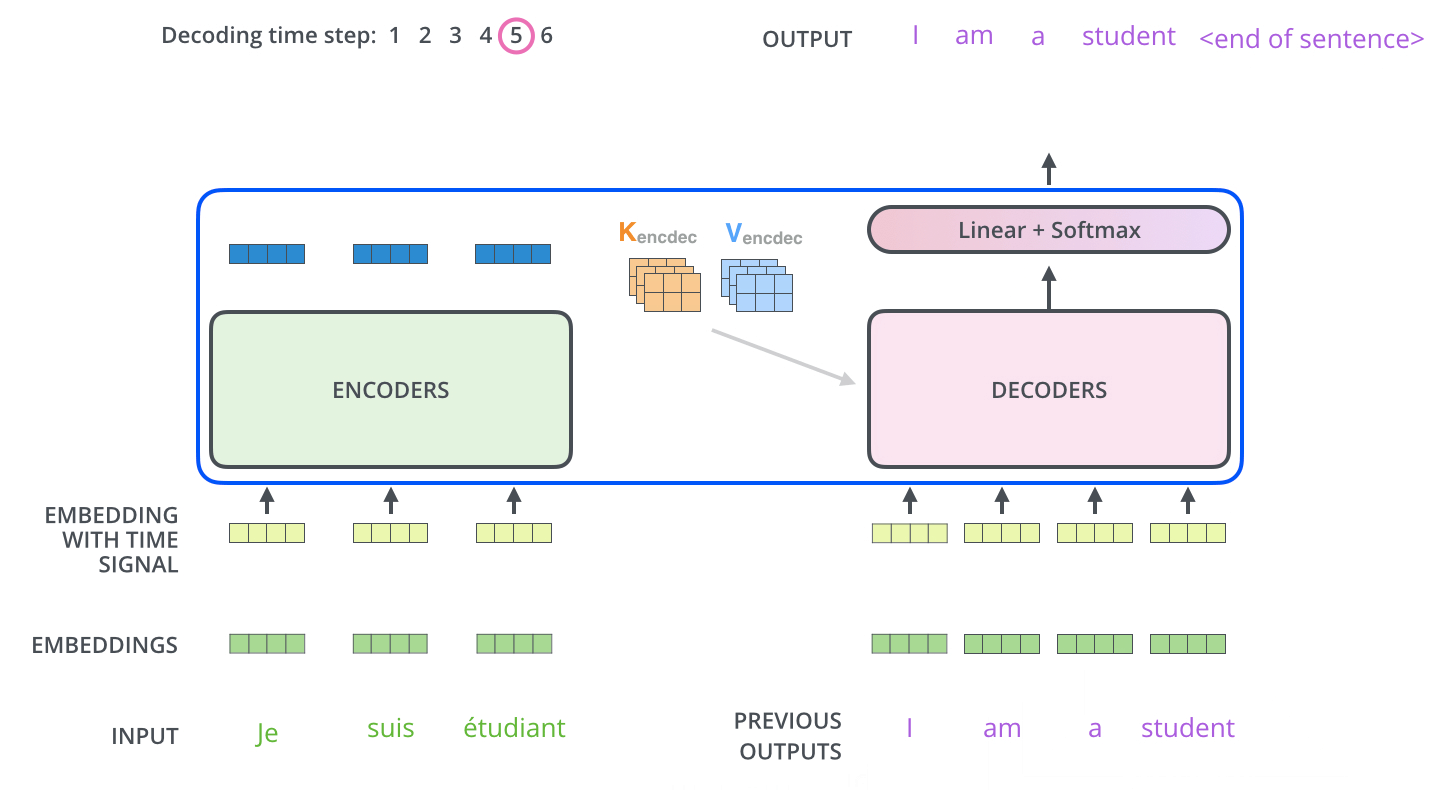
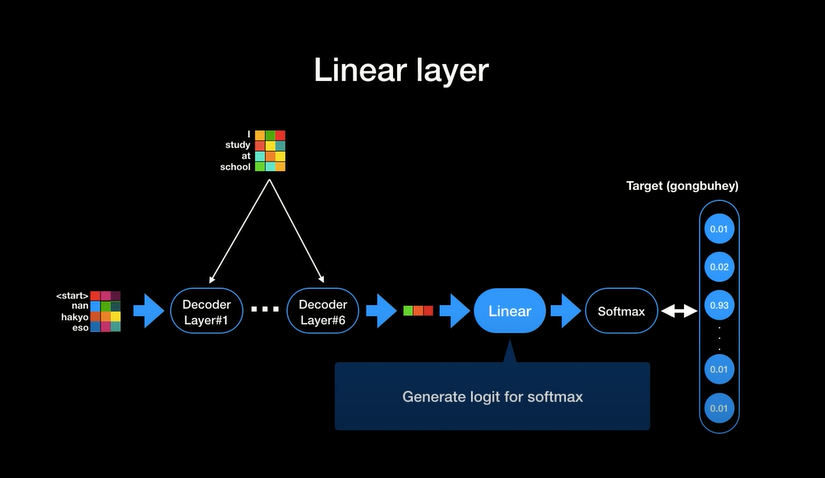
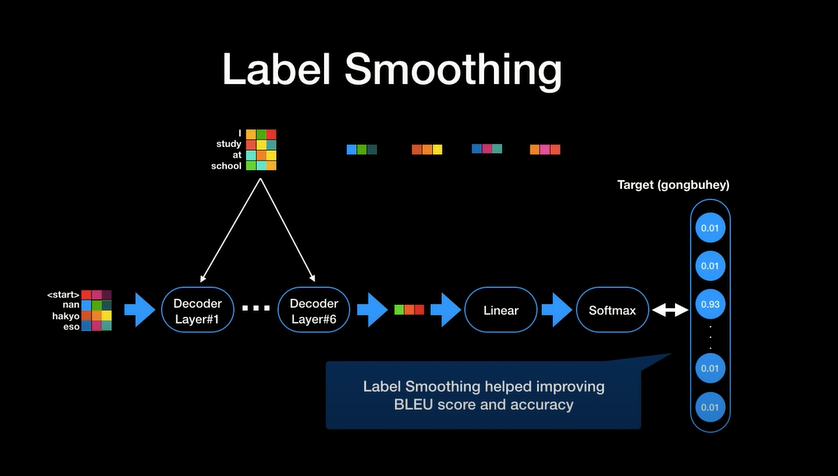
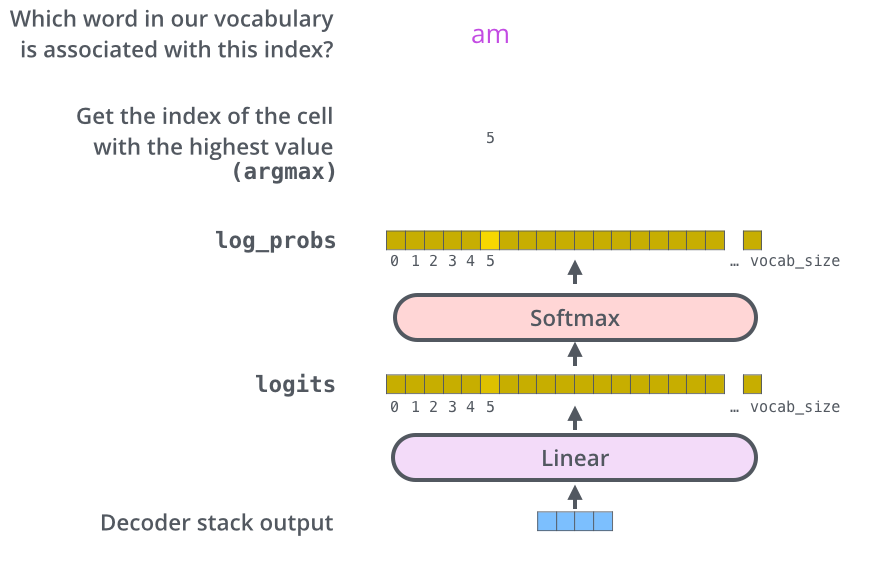
Decoder 최종 출력 과정
[자연어처리 추가 자료]
[이은아님 강의 모음]
https://www.youtube.com/playlist?list=PLGAnpwASolI0vViZItiP90nWI_s9m91Av


반응형
'머신러닝' 카테고리의 다른 글
| 교육용 추천 시스템 (추천 알고리즘) (0) | 2020.08.04 |
|---|---|
| [추천강의] 이은아님 머신러닝 비정형 데이터 분석 11/11 GPT (0) | 2020.07.23 |
| 머신러닝으로 투자에 성공할 수 있을까? (0) | 2020.07.16 |
| [추천강의] 이은아님 머신러닝 비정형 데이터 분석 9/11 Seq2Seq, Attention (0) | 2020.07.15 |
| [추천강의] 이은아님 머신러닝 비정형 데이터 분석 8/11 LDA Inference: Collapsed Gibbs Sampling (0) | 2020.07.13 |