환경(environment)
에이전트(agent)
상태(state)
행동(action)
보상(reward)
탐험과 탐사 갈등(Exploration and exploitation conflict)
마르코프 결정 프로세스(MDP) Markov Decision Process
정책(policy)
가치(value)
상태 가치 함수(State value function)
벨만 수식(Bellman equation)
상태-행동 가치함수(state-action value function)
할인 누적 보상액(discounted accumulating reward)
MDP(Markov Decision Process) 확률분포
상태 -> 상태 가치 함수 -> 상태-행동 가치함수 -> 행동
상태 -> 가치 -> 정책 -> 행동
https://wordbe.tistory.com/entry/RL-%EA%B0%95%ED%99%94%ED%95%99%EC%8A%B5-part1-policy-value-function
[RL] 강화학습 part1 - policy, value function
[RL] 강화학습 part1 - policy, value function Reinforcement Learning 1. 강화학습 원리와 성질 state, action을 번갈아 가면서 목표를 달성합니다. 강화학습 교과서(Sutton, 2017) 참고 1) 계산 모형 상태, 행..
wordbe.tistory.com

강화학습의 목표는 '누적' 보상액을 최대화하는 것입니다.
에이전트가 행동을 선택하는 데 사용하는 규칙을 정책(policy)이라고 하며, 강화 학습 알고리즘은 최적의 정책을 찾아야 합니다.
탐험과 탐사 갈등(Exploration and exploitation conflict) :
k-손잡이 밴딧(k-am bandit) 문제
이 둘의 방식을 보완하기 위해 균형 방식을 사용합니다.
2번에서 잭팟이 나온 이후로 2번 기계를 더 자주 선택하는 대신 다른 기계에게도 계속 기회를 주며 잭팟이 또 터지면 새로운 정보를 고려하여 확률을 배분하고 수정하는 것입니다.
마르코프 결정 프로세스(MDP) Markov Decision Process
현재 상태에서 행동을 결정할 때 이전 이력은 중요하지 않고, 현재 상황이 중요한 조건을 마르코프 성질(Markov Property)을 지녔다고 합니다. 예를 들면 바둑이 있습니다.
강화학습은 마르코프 성질을 만족한다는 전제하에 동작합니다.
따라서 Markov property를 근사하게라도 만족하는 문제에 국한하거나, 근사하게 만족할 수 있도록 상태 표현을 설계해서 적용합니다.
결정론적(Deterministic) MDP : 딱 한가지 상태와 보상이 있는 경우, 나머지 보상은 전부 0
확률론적(Stochastic) MDP : 다음 상태와 보상이 확률적으로 결정되는 경우
정책과 가치함수
강화 학습의 핵심은 좋은 정책을 찾아내는 것입니다.
좋은 정책이 있으면 누적 보상을 최대로 만들 최적 행동을 매 순간 선택할 수 있습니다.
정책 공간은 너무 방대해서 최적 정책을 찾는 접근 방법은 무모하며,
최적 정책을 찾아가는 길잡이 역할을 하는 가치함수를 소개합니다.
1) 정책(policy)
정책이란 상태 s에서 행동 a를 취할 확률을 모든 상태와 행동에 대해 명시한 것입니다.
최적 정책 찾기
goodness(π)가 정책 π의 품질을 측정해주는 함수라고 합시다.
학습 알고리즘은 위를 만족하는 정책 π^를 알아내어야 합니다.
바둑 같은 문제 에서는 상태공간(state space)이 방대합니다.
정책 공간(policy space)은 서로 다른 정책 집합을 뜻하며, 상태 공간보다 훨씬 방대합니다.
따라서 강화학습에서는 정책공간을 일일이 직접 탐색하는 대신 '가치함수'를 이용합니다.
최적 가치함수를 찾으면 최적 정책을 찾는 것은 사소한(trivial) 문제가 됩니다.
2) 가치함수(Value function)
가치함수는 특정 정책의 좋은 정도(상태 s로부터 종료 상태 이르기까지 누적 보상치의 추정치)를 평가합니다.
정책 π에서 추정하며 상태 s의 함수이므로 vπ(s)로 표기합니다.
즉, 위에서 쓰인 goodness는 곧 가치함수로 바뀝니다.
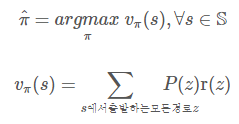
P(z)는 경로 z의 발생확률, r(z)는 경로 z의 누적 보상액입니다.
강화학습에서 유한 경로를 가진 과업을 에피소드 과업(episode task)이라고 합니다.
반면, 무한경로를 가진 과업을 영구과업(continuing task)이라고 합니다.
특별히 영구과업은 무한대 보상을 막기 위해 할인 누적 보상액(discounted accumulating reward)을 사용합니다.
γ를 할인율(discounting rate)이라고 하며, 0≤γ≤1입니다.

0이면 rt+1만 남으므로 순간의 이득을 최대화하는 탐욕 방법인 근시안적 보상액이 되며,
1이면 맨 위의 식처럼 된다.
따라서 할인 누적 보상액은 현재에서 멀어질수록 보상을 할인하여 공헌도를 낮추는 전략을 사용합니다.
가치함수 추정을 위한 순환식
마치 점화식처럼, 다음 상태에서의 가치함수를 표현하여, 가치함수를 간단히 쓸 수 있습니다.

스토캐스틱 프로세스에서 가치함수 추정
지금 까지 수식은 결정론적 프로세스(deterministic process)였습니다.
결정론적 프로세스는 많은 응용을 설명하지 못하지만,
현실에서 모든 요인을 상태 변수에 반영하는 대신 주요 요인만 반영하고 나머지는 무시한 상황서의 상태, 행동, 보상을 스토캐스틱 프로세스(stochastic process)라고 합니다.
스토캐스틱한 성질은 P(s', r|s,a) 확률로 표현됩니다. 이는 MDP 확률분포입니다. 즉, 상태 s에서 행동 a를 취했을 때 상태 s'로 전환하고 보상 r을 받을 확률입니다. 스토캐스틱은 이 값이 여러개일 수 있으므로, 모두 더해줍니다.
가치함수는 MDP 확률분포가 제공하는 정보와 정책 π가 제공하는 정보를 모두 활용하여 정책을 평가합니다.
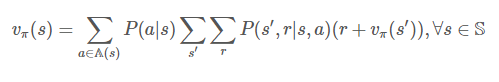
무한 경로를 가진 응용문제에는 할인율을 적용한식을 사용하면 됩니다.
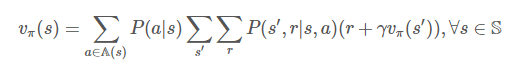
위 두식은 상태 가치 함수(State value function)라고 합니다.
위 두식의 순환식을 가치함수를 위한 벨만 수식(Bellman equation)이라고 하며, 현재 상태의 가치는 다음 상태의 가치의 관계를 간결하게 표현합니다.
이와는 다르게 상태와 행동에 대한 가치함수는 상태-행동 가치함수(state-action value function)라고 하며 식은 아래와 같습니다.
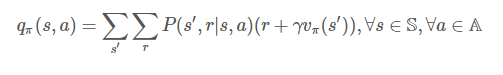
3) 최적 가치 함수
최적 가치함수를 알아 최적 정책을 쉽게 결정할 수 있습니다.
상태 가치함수는 mean 연산을 통해 구하는 반면, 최적 가치함수는 max 연산을 통해 구합니다.


1) 처음에는 임의값으로 정책을 설정하고 출발합니다.
2) 정책에 따라 가치함수를 계산합니다.(정책의 품질 평가)
3) 얻은 가치함수로 더 나은 정책으로 개선합니다.
정책의 평가와 개선은 MDP 확률분포를 기초로 이루어집니다.
4) 정책 개선 싸이클이 없을 때까지 반복합니다.
동적 프로그래밍, 몬테카를로 방법, 시간차 학습 알고리즘은 모두 이 아이디어에 근거합니다.
'머신러닝' 카테고리의 다른 글
| 강화학습3 - Temporal Difference Learning (0) | 2021.01.17 |
|---|---|
| 강화학습2 - 몬테카를로 방법 (0) | 2021.01.16 |
| 이미지 객체 검출 YOLO, DETR (0) | 2020.12.03 |
| kaggle, dacon, google colab, tensorflow, torch, 머신러닝 기초 입문 (0) | 2020.11.27 |
| 교육용 추천 시스템 (추천 알고리즘) (0) | 2020.08.04 |