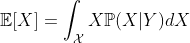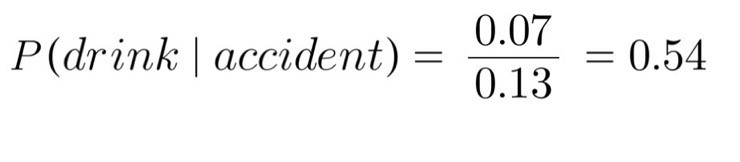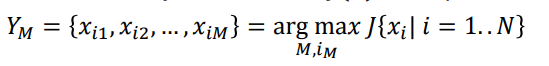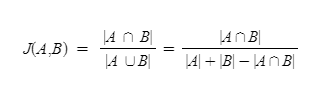따라서(A 안의 cute가주제2일확률) = 0.916 *0.125 ...= 0.114...가 됩니다.
즉 A 안의 cute는 (0.00008, 0.114)의 카테고리 분포를 따라주제1이되거나주제2가되겠죠. 가능도 비중을 따라 주제1이나 주제2중에 하나를 뽑습니다. (물론 높은 확률로주제2가뽑히겠죠. 하지만주제1이뽑힐 가능성이 아예 0이 되지는 않습니다. 이는 하이퍼 파라미터α와β가 하는 역할 중하나에요.)여기서는주제2로배정되었다고 가정할게요.
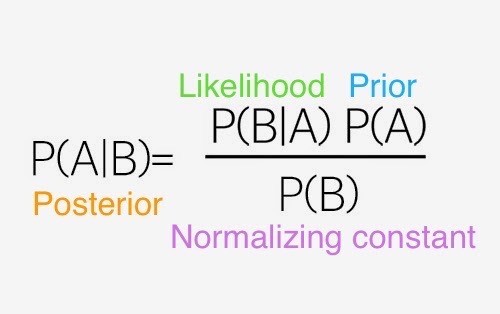
우리의 현상, 혹은 관측을 Y라 하고, 이 현상의 원인을 X라 했을 때, 다음 세 가지를 정의한다.
- 편의상 X를 내면의 감정이라 하고, Y를 외면의 표현이라고 하자.
- X는 기쁨, 슬픔, 등등이 있고, Y에는 웃음, 울기, 짜증 등등이 있을 것이다.
1.Likelihood(개인적으로 우도란 단어를 별로 좋아하지 않는다.)
P(Y|X)
이것이 의미하는 것은 어떤 (원인)의도가 주어졌을 때 (관찰)현상이 일어날 확률이다. 예를 들면 슬플 경우 꽤나 높은 확률로 울 것이다.
2.Posterior
P(X|Y)
베이지안의 주된 목적은 바로 이것을 구하는 것이다. 다시 말해서 우리에게 현상이 주어졌을 때 원인을 찾는 것이다. 예를 들면 누가 웃고 있을 때 과연 이 사람이 슬픈지, 기쁜지를 알아내는 것이다. 이는 단순히 Likelihood와는 다르다.현상에서 원인을 '역으로' 맞추는 것이기 때문에 추가 정보가 필요하고, 이것이 Prior이다.이는 해당 사람이 평소에 슬픈지, 기쁜지에 대한 사전 정보이다.
3.Prior
P(X)
이것은 앞서 말한 사전 정보이다. 사람이 평소에 기쁜지, 슬픈지, 짜증 내는지에 대한 정보이다.이 정보의 유무에 따라 베이지안과 프리퀀티스트를 나눈다고 볼 수 있다.
그리고, 위의 식들을 하나로 묶는 것이 바로베이즈 법칙이다.
말로 풀어서 설명을 해보면 어떤 사람이 울고 있을 때 이 사람이 기쁠 확률은
1. 해당 사람이 기쁠 때 울 확률과
2. 해당 사람이 평소에 기쁠 확률을
곱해서 구해진다는 것이다. 나름 일리가 있다.
여기서 한 가지 주의할 점은 비례한다는 것이다. 정확한 확률 분포를 구하기 위해서는 normalize를 해줘야 하고, 이는.. 어렵다! 특정 Likelihood와 Prior가 곱해졌을 경우 Posterior를 쉽게 구할 수 있는 경우가 있는데 이런 Prior를 Conjugate Prior라고 한다. 대표적인 예로는 가우시안-가우시안+인버스 감마, 디리클레-멀티노미알 등이 있다. 자세한 건 위키를 참고하면 된다.
위에서 설명한 Likelihood, Prior, Posterior에 대한(?) 그림
우리가 어떤 '값'을 원한다고 하자. 예를 들면 울고 있는 저 사람이 기쁠 '확률'을 구하시오! 혹은 이 사람이 기쁜지 슬픈지를 '구분'하시오! 란 명령이 내려졌다고 하자. 이런 경우에 베이지언은 다음과 같은 해답을 내놓는다.
즉 Posterior mean을 구한다는 의미이다. 그리고 이 적분은 가능한 모든 X의 공간인 X에서 수행되어야 한다. 하지만 우리가 모두 알듯이 적분은 어렵다. 그래서 이를 근사하고자 할 때 사용되는 것이 바로 Monte Carlo Markov Chain (MCMC) 알고리즘이다. 위의 적분은 큰 수의 법칙에 따라 다음과 같이 표현될 수 있다.
그리고 여기서 필요한 가정이
이다. 즉 우리가 모은 N 개의 데이터가Posterior에서 '추출된'데이터야 한다는 것이다.
하지만 이는 생각보다 쉽지가 않다. 여기에는 두 가지 이슈가 있다.
1. 우리가 추출할 수 있는 확률은 Uniform 혹은 Gaussian 정도이다.
2. 데이터의 차원이 커질수록 exponential 하게 어려워진다..
첫 번째 문제를 다루고 있는 것이 Metropolis-Hastings (MH) 알고리즘이고, 두 번째 문제를 다루고 있는 것이 Gibbs 샘플링이다.
Metropolis-Hastings (MH) Algorithm
알고리즘 자체는 매우 간단하고, 증명은 매우 복잡하니 알고리즘 설명만 하겠다. 여기서 증명이라는 것은 이런 식으로 뽑아도 괜찮다는 것을 의미한다.
1.목적
가 주어졌을 때, pi(X)에서 N 개의 샘플인 X_1, X_2, ..., X_N 을 구하는 것이다.
2.알고리즘
초기화
: 임의의 q(y|x)를 설정한다. 그리고 이는 우리가 sample 할 수 있어야 한다. 일반적으로 다음과 같이 설정한다.
의미를 생각해보면 현재 샘플 된 값 주변에서 다음 샘플을 뽑고자 하는 것이다.
: 초깃값 X_1을 구한다.
n-th 샘플링
1.에서 Y를 뽑는다.
2. 다음과 같이 r을 구한다.
이때 f는 pi에 비례하는 함수이다.
3. r의 확률로 X_n = Y로 하고, 1-r의 확률로 X_n = X_n-1로 한다.
사족 1: r의 의미를 살펴보면, 이 값은 Y가 우리의 분포인 pi(Y)에 대해서 얼마나 적합한지를 나타낸다. 분모에 f(Y)가 있으므로, 확률이 더 높은 걸 뽑으려고 하는 경향성을 볼 수 있다. 사실 우리는 X_i들을 다 모아서 empirical distribution을 그렸을 때 pi(·)이 되도록 하길 원하므로 일맥상통한다고 볼 수 있다.
사족 2: 여기서 f는 우리가 관심 있는 pi에 비례함에 주목하자. 바꿔 말하면 정확한 확률 분포가 아니라 비례하는 pseudo-distribution이여도 이 알고리즘은 돌아갈 수 있다.
위의 알고리즘에서 알 수 있듯이 우리는 우리의 목적인 pi(X)에서 X를 직접 뽑을 필요가 없다. 하지만 이 알고리즘은 데이터의 차원이 커질수록 매우 오랜 시간이 걸려서 알고리즘이 돌아간다.
깁스 샘플링에 대한 포스팅은 예전에 한 적이 있다. (http://enginius.tistory.com/296) 벌써 2년 전이다.. 시간 참 빠르다. 여튼 깁스 샘플링의 의의(?)는 고차원 공간에서 샘플링을 효과적으로 할 수 있다는 데 있다. 사실 개념은 굉장히 straight-forward 하다. d 차원의 랜덤 변수를 d 개의 1차원 변수로 나눠서 보겠다는 것이다.
2.알고리즘
우리가 관심 있는 것이 X = {x_1, x_2, ..., x_d}의 d 차원 변수라고 할 때, 이들을 나눠서 샘플링 하면 된다. 즉,
를 잘 정의하고, i = 1, 2, ..., d로 반복하면서 X를 뽑는다. 간단하다.
물론 여기서 위의 확률 분포에서 뽑기가 힘들 땐, 앞서 설명한 Metropolis-Hastings 알고리즘을 이용하면 된다.
정리하자면 임의의 다차원 확률 분포가 주어졌을 때, 이들을 conditional distribution으로 변경할 수 있다면, Metropolis-Hastings 알고리즘과 Gibbs sampling을 이용해서 이들 분포를 따르는 확률분포의 seqeunce를 뽑아낼 수 있고, Posterior mean을 구할 수 있다.
Markov Assumption(=Markov Property) : 직전 사건에 의해서만 현재 사건이 영향을 받는 속성
Chain : discrete 한 Time Sequence 사건
Markov Chain : Markov Assumption 을 만족하는 Chain
Monte Carlo Method : 다음과 같이 여러 개의 표본을 추출해서 전체적인 분포를 파악하는 방법론
Sampling : 해당 모델을 만족하는 데이터를 생성, 추출해내는 것. 단 그 모델의 확률 분포에 비례하여 확률 밀도가 높은 곳에서 그에 비례하게 더 많은 데이터가 나오도록 추출해야 한다.
Markov Chain Monte Carlo : Markov Chain에서 샘플링을 하기 위해 Monte Carlo Method를 써서 확률 분포가 반영된 데이터를 샘플링하는 것. 여기서의 Markov는 샘플링을 Markov Chain으로 하는 의미임.
(Markov Random Field에서의 Markov는 그래프의 노드들이 서로 마르코프 프로퍼티를 갖는 의미인 듯)
Detailed Balance : MCMC에서 뽑은 샘플이 P(X)의 분포를 충분히 근사하기 위한 조건. P(X'->X)/P(X->X')=1 이면 만족하며, Ergodicity라는 개념 또한 관련이 있다. 간단히 말하면 확률 분포가 연속적이고 섬처럼 동떨어진 분포가 있지 않는 일반적인 경우를 말한다.
Rejection Sampling : MCMC 알고리즘 중 가장 기본적인 샘플링 기법. 랜덤하게 (Uniform 하게) 하나의 데이터를 추출한 다음, 그것의 확률 값을 계산하여 그 확률만큼 Accept 하고 나머지는 Reject 시키는 방법. (당연히 이렇게 하면 확률 값이 큰 곳의 샘플들은 많이 뽑히고, 확률 값이 적은 곳의 샘플들은 잘 뽑히지 않는다. 그러나 이 방법은 확률분포가 매우 넓고 길게 퍼져있는 공간에서는 버려야 하는 샘플이 너무 많아 시간 효율이 좋지 않다.)
Metropolis-Hastings : 조금 더 개선된 MCMC 알고리즘의 하나로 샘플링을 한 번 한 다음, 다음 샘플에 대해서 Accept 할지를 min(1, P(X')/P(X)) 의 확률로 결정하는 방법. X'은 다음에 샘플링하기 위해 랜덤하게 (Uniform 하게) 뽑아본 샘플이다. min(1, P(X')/P(X))을 해석해보면, X'에서의 확률이 기존 샘플 X에서의 확률보다 크면 무조건 샘플링을 하는 것이고(1이 선택되므로),X'의 확률이 더 작은 경우 그에 비례하여 Reject를 하는 방법이다. 이것은 Detailed Balance를 만족시키면서 보다 빠른 방법이다.
그러나 Metropolis-Hastings의 경우도 고차원으로 갈수록 한 샘플에서의 확률 값이 0으로 점점 가까워지기 때문에 Accept Ratio가 매우 낮아져 시간 상 비효율적이다.
(고차원에서도 어떤 확률 분포의 합은 결국 1이 되어야 한다. 그러나 차원이 커질수록 그것을 구성하는 분포도 차원에 따라 확장되어 퍼질 수밖에 없다.)
Gibbs Sampling : Metropolis-Hastings의 단점인 고차원에서의 느린 샘플링을 해결한 MCMC 알고리즘. 구현이 쉽고 간편하며, 실행 속도도 빨라 널리 사용되는 샘플링 방법이다.
맨 처음 하나의 Initial 한 샘플을 랜덤하게 정한 다음, 그 샘플에서 변수를 1개씩, 즉 1개 차원씩 번갈아가면서 정하는 방법.
이것은 Xi ~ P(Xi|X-i) 로 표현하며, 의미는 Xi라는 i 번 째 변수 하나를 결정할 때, i를 제외한 나머지(X-i) 변수들을 이용해서 결정하는 것이다.
만약 L 차원에서의 확률 분포라면, 1~L까지의 변수들을 하나씩 샘플링 한 다음, 다시 1~L까지를 또 샘플링하고 이것을 계속해서 반복한다. 그렇게 만든 샘플들이 쭉 있으면, 그것들을 다시 일정한 간격으로 택하여 최종 샘플링을 완성한다.
Gibbs Sampling은 고차원의 영역을 빠르게 여기저기 왔다 갔다 하면서 샘플들을 뽑기 때문에 딥러닝 등에서 자주 쓰인다.
(Gibbs Sampling의 Binary에서 예시)
1-1 : [1,0,1] // Initial 샘플로, 랜덤하게 정해진 것이며, 굵게 칠해진 숫자"1"을 0으로 바꿀지, 그대로 1로 놓을 지를 나머지 두 변수 0, 1의 확률을 이용해서 계산한다.
1-2 : [0,0,1] // 다시 두 번째 변수인 0에 대해서 결정 한다. 물론 확률적인 것으로, 0->0이 될 수도 있고 0->1이 될 수도 있다.
1-3 : [0,1,1] // 마지막 세 번째 변수인 1에 대해서 정한다. 이번엔 1->1로 변하지 않았다.
(3차원 변수이므로, 3회가 지날 때마다 전체 데이터를 샘플링한다.)
2-1 : [0,1,1] // 다시 마지막 상태에서부터 이어서 첫 번째 변수부터 시작한다.
2-2 : [1,1,1]
...
이렇게 1000사이클을 돌아 총 1000*3개의 결과가 완성되었다고 해보자, 그러면 이 3천 개의 데이터 셋에서 일정한 간격(N 차원 일 경우, N 번 째 간격)으로 데이터를 선택하여 최종적인 샘플링을 완성한다. 그 이유는 위와 같은 과정이 N 번 거쳐야만, 모든 차원에 대해 변화가 이루어지기 때문이다.
Gibbs Sampling은 일종의 현재 상태에서의 변수들의 상태를 체크해보고자 하는 방법으로 쓰일 것 같다는 느낌이다. 물론 활용 범위가 매우 매우 커서 공학적으로 안 쓰이는 곳이 없는 것 같다.
Gibbs sampling에서는 proposal distribution 이 그 확률 분포 자체의 conditional distribution이다. RBM 같은 경우 이 conditional 분포 자체가 gaussian 혹은 베르누이 분포이기 때문에 이 자체에서도 바로 샘플링이 가능하며, 이것의 의미는 N 차원의 공간에서 1축씩 이동할 때, conditional distribution을 통해서 샘플링을 하여 한 축씩 이동하는 것을 의미한다.
그런데 만약 gibbs sampling에서의 conditional distribution 자체만으로 proposal distribution으로 사용이 불가능할 때, 즉 샘플링이 불가능한 분포인 경우 이 1개의 축을 이동하는 과정에서도 metropolis-hastings 같은 방법을 사용해야만 한다. 즉 어떻게 보면 깁스 샘플링은 1축씩 이동하는 어떤 메타 방법론이라고 볼 수도 있다.
그리고 만약 gibbs sampling을 2차원의 변수에 대해서 할 때, 2개의 모드가 있는데 이 두 개의 모드가 x1과 x2의 대각선 방향으로 아주 멀리 서로 위치해 있다면, gibbs sampling만으로는 절대 다른 모드로 넘어갈 수가 없다. 왜냐하면 1축씩 이동하는 방식으로는 현재의 모드 밖을 넘어갈 확률이 0이기 때문이다.(대각선에 위치하므로 1개의 변수만 사용해서는 확률이 0이 됨)
그러나 아주 고차원 공간에서는 이런 식으로 모든 축에 대해서 걸리지 않는 모드가 존재할 확률이 매우 낮아지고, 반드시 어느 한 축에서는 다른 모드의 확률이 존재하게 된다. 그래서 고차원 공간에서는 이렇게 1개의 축이라도 걸리면, 이 축을 통해서 다른 모드로 넘어가는 것이 가능하다. 그래서 gibbs sampling이 고차원 공간에서 아주 빠르게 효과적으로 잘 동작한다고 볼 수 있다.
MCMC는 N 차원의 점에서 바로 N 차원의 점으로 모든 차원을 한 번에 이동하면서 샘플링을 한 것인 반면, 깁스 샘플링은 한 개의 차원을 제외한 나머지는 고정을 시킨 다음, 한 차원 씩 샘플링을 해서 총 N 번의 이동을 하고 난 다음 진짜 새로운 데이터를 샘플링하는 것이다.
단 깁스 샘플링을 하기 위해서는 말한 대로 한 개 차원을 제외한 나머지를 given으로 고정시켜야 한다. 즉 각 차원에 대한 conditional probability를 알아야만 사용이 가능하다.
그러나 RBM 같은 모델의 경우, 우리가 모델을 정의하였으므로 그 conditional probability를 알 수가 있다. 따라서 당연히 깁스 샘플링도 가능하다.
MH는 1~10차원의 샘플링은 잘 하지만, 수천 차원에서의 샘플링은 리젝션 레이트가 너무 높아서 작동을 하지 못한다.
깁스 샘플링이 좋은 이유는 한 번에 1개의 차원씩 이동을 하기 때문에, 문제를 훨씬 단순화 시켜서 풀었다는 것이고 그로 인해 고차원의 저주와 같은 문제가 안 발생하는 걸로 보인다. 그래서 고차원 분포의 샘플링에서 훨씬 빠르게 동작하는 것 같다.
문헌 d에 속하는 어떤 단어 m이 주제 j에 속할 확률은 주제 j에 속하는 모든 단어 중에서 단어 m이 차지하는 비중과 문헌 d에 속하는 모든 주제 중 주제 j가 차지하는 비중의 곱에 비례한다는 것입니다.
깁스 샘플링을 이용한 LDA는 다음과 같은 절차로 이뤄집니다.
1. 각각의 단어에 임의의 주제를 배정한다
2.(잘못됐겠지만) 모든 단어에 주제가 배정되어 있고, 그 결과 문헌별 주제 분포와 주제별 단어 분포가 결정되었음. 이를 깁스 샘플링을 통해서 개선해 나가자.
3.n 번째 단어를 골라 빼낸다. (나머지 단어들이 모두 적절하게 배정되어 있다고 가정하고)
4. 빼낸 단어를 제외하고, 그 단어가 속한 문헌의 주제 분포(P(Topic | Document))를 계산하고, 그 단어가 속한 주제의 단어 분포(P(Word | Topic))를 계산한다. P(Word | Topic) * P(Topic | Document)에서 Topic을 하나 뽑아 그 단어에 배정한다.
5.n <- n+1로 하고 3번으로 돌아간다.
6. 충분히 반복하다 보면 값들이 수렴하고 안정되게 된다. 그럼 끝.
적용예)
1. 각각의 단어의 임의의 주제를 배정한다
주제가 2개이므로 #1, #2둘 중에 하나를 각 단어에 임의로 배정했습니다. 이렇게 단어가 배정되었으니 우리는 이제 문헌별 주제 분포와 주제별 단어 분포를 계산할 수 있습니다.
2. 문헌별 주제 분포, 주제별 단어 분포를 계산한다.
문헌별 주제 분포 θ입니다. 각 값이 0으로 끝나는 게 아니라. 1인 이유는 모든 값에 하이퍼 파라미터 α값이 합쳐져 있기 때문입니다. A 문헌에는 #1, #2가 각각 하나씩이므로 (1.1, 1.1)이 계산된 것이고, C 문헌에는 #2만 2개 배정되었으므로 (0.1, 2.1)가 계산된 것입니다.
주제별 단어 분포 φ입니다. 마찬가지로 0.001로 끝나는 이유는 하이퍼 파라미터 β값이 합쳐져 있기 때문입니다.
3. 첫 번째 단어를 골라 빼낸다.
첫 번째 단어 cute를 빼냈습니다. 따라서 문헌별 주제 분포, 주제별 단어 분포도 다음과 같이 바뀌게 됩니다.
4. 새로운 주제를 배정한다
문헌 A에 속하는 단어 cute가 #1에 속할지 #2에 속할지 판단해야 합니다. 문헌 내 주제 분포를 따르면
따라서 (A 안의 cute가 #2일 확률) = 0.916 * 0.125 ... = 0.114... 가 됩니다.
즉 A 안의 cute는 (0.00008, 0.114)의 카테고리 분포를 따라 #1이 되거나 #2가 되겠죠. 가능도 비중을 따라 #1이나#2 중에 하나를 뽑습니다. (물론 높은 확률로 #2가 뽑히겠죠. 하지만 #1이 뽑힐 가능성이 아예 0이 되지는 않습니다. 이는 하이퍼 파라미터 α와 β가 하는 역할 중 하나에요.) 여기서는 #2로 배정되었다고 가정할게요.
3-1. 두 번째 단어를 골라서 빼낸다.
여기서부터는 반복입니다. 설명은 다 적지 않도록 하고 각 단어 샘플링 단계마다 주제 배정이 어떻게 바뀌었는지만 보여드리도록 하겠습니다.
마지막 단어까지 업데이트가 끝나면 이것이 1회 깁스 샘플링을 마무리한 것이 됩니다. 이 작업을 적절하게 여러 번 반복하다 보면 모든 단어가 적절하게 자기 주제를 찾아 배정되게 될 것이라는 것이 깁스 샘플링을 이용한 LDA의 가정이죠. 수렴할 때까지 반복하면 다음과 같은 결과가 나옵니다.
토픽 모델링은 문서의 집합에서 토픽을 찾아내는 프로세스를 말한다. (토픽은 한국어로는 주제라고 한다.)
이는 검색 엔진, 고객 민원 시스템 등과 같이 문서의 주제를 알아내는 일이 중요한 곳에서 사용된다.
잠재 디리클레 할당(Latent Dirichlet Allocation, LDA)은 토픽 모델링의 대표적인 알고리즘이다.
1. 잠재 디리클레 할당(Latent Dirichlet Allocation, LDA)
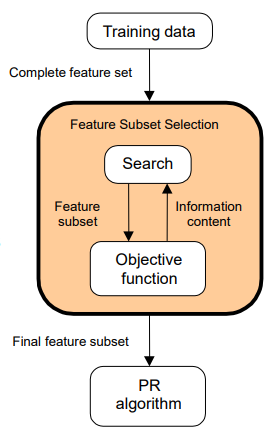
우선 LDA의 내부 매커니즘에 대해서 이해하기 전에, LDA를 일종의 블랙 박스로 보고 LDA에 문서 집합을 입력했다면, 어떤 결과를 보여주는지 예를 들어보겠다. 아래와 같은 3개의 문서가 있다고 가정한다면, 지금의 예제는 간단해서 눈으로도 토픽 모델링을 할 수 있을 것 같지만, 실제 수십만개 이상의 문서가 있는 경우는 LDA의 알고리즘의 도움이 필요하다.
문서1: 저는 사과랑 바나나를 먹어요
문서2 : 우리는 귀여운 강아지가 좋아요
문서3 : 저의 깜찍하고 귀여운 강아지가 바나나를 먹어요
LDA를 수행할 때 문서 집합에서 토픽이 몇 개가 존재할지 가정하는 것은 사용자가 해야할 일이다. 여기서는 LDA 알고리즘에 2개의 토픽을 찾으라고 요청하겠다. 토픽의 개수를 변수 k라고 하였을 때, k = 2 이다. k의 값을 잘못 선택하면 원치않는 이상한 결과가 나올 수 있다. 이렇게 모델의 성능에 영향을 주는 사용자가 직접 선택하는 매개변수를 머신러닝 용어로 하이퍼파라미터라고 한다. 이러한 하이퍼파라미터의 선택은 여러 실험을 통해 얻은 값일 수도 있고, 우선 시도해보는 것일 수도 있다.
LDA 알고리즘이 위의 세 문서로부터 2개의 토픽을 찾은 결과는 아래와 같다. 여기서는 LDA 입력 전에 주어와 불필요한 조사 등을 제거하는 전처리 과정은 거쳤다고 가정한다. 즉, 전처리 과정을 거친 TDM이 LDA의 입력이 되었다고 가정한다.
LDA 알고리즘은 토픽의 제목을 정해주지 않지만, 이 시점에서 알고리즘의 사용자는 두 토픽이 각각 과일에 대한 토픽과 강아지에 대한 토픽이라는 것을 알 수 있다.
2. LDA의 가정
LDA는 문서의 집합으로부터 어떤 토픽이 존재하는지를 알아내기 위한 알고리즘이다. LDA 알고리즘은 앞서 배운 빈도수 기반의 표현 방법들인 TDM 또는 TF-IDF 행렬을 입력으로 하는 데, 이로부터 알 수 있는 사실은 LDA는 단어의 순서는 신경쓰지 않는다는 점이다.
LDA는 문서들로부터 토픽을 뽑아내기 위해서 어떤 가정을 염두에두고 있다. 실제로 문서의 작성자가 그랬는지 안 그랬는지는 중요하지 않다. LDA는 기본적으로 이러한 가정을 전제로 한다. 모든 문서 하나, 하나가 작성될 때 그 문서의 작성자는 이러한 생각을 했다.
‘나는 이 문서를 작성하기 위해서 이런 주제들을 넣을거고, 이런 주제들을 위해서는 이런 단어들을 넣을 거야.’ 조금 더 구체적으로 알아보면, 각각의 문서는 다음과 같은 과정을 거쳐서 작성되었다고 가정한다.
1) 문서에 사용할 단어의 개수 N을 정한다.
ex) 5개의 단어를 정했다.
2) 문서에 사용할 토픽의 혼합을 결정한다.
ex) 위 예제와 같이 토픽이 2개라고 하였을 때 강아지 토픽을 60%, 과일 토픽을 40%와 같이 선택할 수 있다.
3) 문서에 사용할 각 단어를 (아래와 같이) 정한다.
3–1) 토픽 분포에서 토픽 T를 확률적으로 고른다.
ex) 60% 확률로 강아지 토픽을 선택하고, 40% 확률로 과일 토픽을 선택할 수 있다.
3–2) 선택한 토픽 T에서 단어의 출현 확률 분포에 기반해 문서에 사용할 단어를 고른다.
ex) 강아지 토픽을 선택했다면, 33% 확률로 강아지란 단어를 선택할 수 있다. 이제 3) 을 반복하면서 문서를 완성한다.
이러한 과정을 통해 문서가 작성되었다는 가정 하에 LDA는 토픽을 뽑아내기 위하여 위 과정을 역으로 추적하는 역공학(reverse engneering)을 수행한다. 앞서 LDA의 결과로 문서 내 토픽 분포와 토픽 내 단어 분포가 나왔던 이유가 여기에 있다.
3. LDA의 수행하기
이제 LDA의 수행 과정을 정리해보자.
1) 사용자는 알고리즘에게 토픽의 개수 k를 알려준다.
앞서 말하였듯이 알고리즘에게 토픽의 개수를 알려주는 역할은 사용자의 역할이다. LDA 알고리즘은 토픽 k가 M개의 문서에 걸쳐 분포되었다고 가정한다.
2) 모든 단어를 k개 중 하나의 토픽에 할당한다.
이제 각 문서는 토픽을 가지며, 토픽은 단어 분포를 가지는 상태이다. 물론 랜덤으로 할당하였기 때문에 사실 전부 틀린 상태이다. 만약 한 단어가 한 문서에서 2회 이상 등장하였다면, 각 단어는 서로 다른 토픽에 할당되었을 수도 있다.
3) 이제 모든 문서의 모든 단어에 대해서 아래의 사항을 반복 진행한다.(iterative)
3–1) 어떤 문서의 각 단어 w는 자신은 잘못된 토픽에 할당되어져 있지만, 다른 단어들은 전부 올바른 토픽에 할당되어져 있는 상태라고 가정한다. 이에 따라 단어 w는 아래의 두 가지 기준에 따라서 토픽이 재할당된다.
p(topic t | document d) : 문서 d의 단어들 중 토픽 t에 해당하는 단어의 비율
p(word w | topic t) : 단어 w를 갖고 있는 모든 문서들 중 토픽 t가 할당된 비율
이를 반복하면, 모든 할당이 완료된 수렴 상태가 된다. 두 가지 기준이 어떤 의미인지 예를 들어보자. 설명의 편의를 위해서 저자는 두 개의 문서라는 새로운 예를 사용했다.
위의 그림은 두 개의 문서 doc1과 doc2를 보여준다. 여기서는 doc1의 세번째 단어 apple의 토픽을 결정하고자 한다.
우선 첫번째로 사용하는 기준은 문서 doc1의 단어들이 어떤 토픽에 해당하는지에 대한 단어들의 비율이다. doc1의 모든 단어들은 토픽 A와 토픽 B에 50 대 50의 비율로 할당되어져 있으므로, 이 기준에 따르면 단어 apple은 토픽 A 또는 토픽 B 둘 중 어디에도 속할 가능성이 있다.
두번째 기준은 단어 ‘apple’이 전체 문서에서 어떤 토픽에 할당되어져 있는지를 본다. 이 기준에 따르면 단어 ‘apple’은 토픽 B에 할당될 가능성이 높다. 이러한 두 가지 기준을 참고하여 LDA는 doc1의 ‘apple’을 어떤 토픽에 할당할지 결정한다.
4. 잠재 디리클레 할당과 잠재 의미 분석의 차이
LSA : 단어 문서 행렬을 차원 축소하여 축소 차원에서 근접 단어들을 토픽으로 묶는다.
LDA : 단어가 특정 토픽에 존재할 확률과 문서에 특정 토픽이 존재할 확률을 결합확률로 추정하여 토픽을 추출한다.
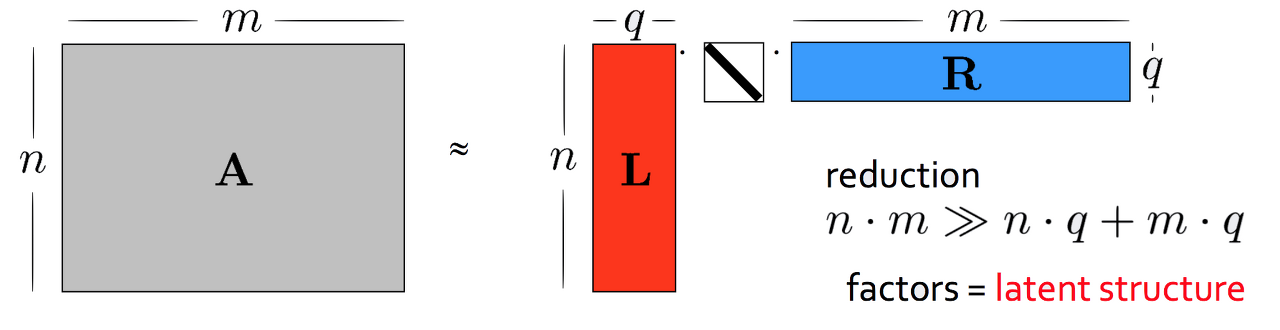
pLSA는 기존잠재 의미분석(Latene Semantic Analysis) 과는아예 다른 기법이지만 개념을 공유하는 게 많아서 먼저 설명해볼까 합니다. LSA에 대한 자세한 내용은이곳을 참고하시면 좋을 것 같습니다. 어쨌든 LSA는 말뭉치 행렬A를 다음과 같이 분해하는 걸 말합니다.
LSA 수행 결과로n 개문서가 원래 단어 개수보다 훨씬 작은q 차원의벡터로 표현된 걸 확인할 수 있습니다.
마찬가지로m 개단어는 원래 문서 수보다 훨씬 작은q 차원벡터로 변환됐습니다.
q가 3이라면 전체 말뭉치가 3개의 토픽으로 분석됐다고도 말할 수 있을 것입니다.
위 그림에서 행렬L의 열벡터는 각각 해당 토픽에 대한 문서들의 분포 정보를 나타냅니다.
R의 행벡터는 각각 해당 토픽에 대한 단어들의 분포 정보를 나타냅니다.
중간에 대각행렬은q 개토픽 각각이 전체 말뭉치 내에서 얼마나 중요한지 나타내는 가중치가 될 겁니다.
pLSA
pLSA는 단어와 문서 사이를 잇는, 우리 눈에 보이지 않는 잠재 구조가 있다는 가정 하에 단어와 문서 출현 확률을 모델링 한 확률모형입니다.
pLSA는 아래 그림처럼Latent concepts가 존재하고 이것이 문서와 단어를 연결한다고 가정합니다. 문서들의 주제(토픽)이라고 생각하면 좋을 것 같습니다.
왼쪽부터 차례로 살펴보겠습니다. P(z|d)는 문서 하나가 주어졌을 때 특정 주제(토픽)가 나타날 확률을 의미합니다. P(w|z)는 주제가 정해졌을 때 특정 단어가 나타날 확률을 가리킵니다.
LSA와 pLSA
LSA는 행렬 인수분해(matrix factorization),
pLSA는 확률모형입니다.
아예 그 종류가 다르다고 할 수 있죠. 하지만 개념상 연결되는 부분이 있습니다. 그래서일까요? 이름도 좀 많이 비슷해요. 어쨌든 아래 그림을 보겠습니다.
LSA 결과물인 행렬Uk의 열벡터는 각각 해당 토픽에 대한 문서들의 분포 정보를 나타냅니다. 이는 pLSA의 P(d|z)에 대응합니다.
행렬Vk의 행벡터는 각각 해당 토픽에 대한 단어들의 분포 정보를 나타냅니다. 이는 pLSA의 P(w|z)에 대응합니다.
Σk의 대각성분은 토픽 각각이 전체 말뭉치 내에서 얼마나 중요한지 나타내는 가중치가 됩니다. 이는 pLSA의 P(z)에 대응합니다.
pLSA의 결과물은 확률이기 때문에 각 요솟값이 모두 0 이상, 전체 합이 1이 됩니다. 하지만 LSA는 이런 조건을 만족하지 않습니다.
pLSA의 목적식
pLSA는m 개단어,n 개문서,k 개주제(토픽)에 대해 아래 우도 함수를 최대화하는 걸 목표로 합니다.
위 식에서n(wi,dj)는j 번째문서에i 번째단어가 등장한 횟수를 나타냅니다.
p(wi,dj)는k 개주제(토픽)에 대해 summation 형태로 돼 있는데요. 같은 단어라 하더라도 여러 토픽에 쓰일 수 있기 때문입니다.
예컨대 정부(government) 같은 흔한 단어는 정치, 경제, 외교/국방 등 다양한 주제에 등장할 수 있습니다.
pLSA의 학습 : EM 알고리즘
EM 알고리즘은동시에 최적화할 수 없는 복수의 변수들을 반복적인 방식으로 계산하는 기법입니다. 우선 모든 값을 랜덤으로 초기화합니다. 이후 하나의 파라미터를 고정시킨 다음에 다른 파라미터를 업데이트하고, 이후 단계에선 업데이트된 파라미터로 고정시킨 파라미터를 다시 업데이트합니다. 다음과 같습니다.
여기서의 특이값 분해(Singular Value Decomposition, SVD)는 실수 벡터 공간에 한정하여 내용을 설명함을 명시합니다.
SVD란 A가 m × n 행렬일 때, 다음과 같이 3개의 행렬의 곱으로 분해(decomposition) 하는 것을 말합니다.
2. 절단된 SVD(Truncated SVD)
위에서 설명한 SVD를 풀 SVD(full SVD)라고 합니다. 하지만 LSA의 경우 풀 SVD에서 나온 3개의 행렬에서 일부 벡터들을 삭제시킨 절단된 SVD(truncated SVD)를 사용하게 됩니다.
3. 잠재 의미 분석(Latent Semantic Analysis, LSA)
기존의 DTM이나 DTM에 단어의 중요도에 따른 가중치를 주었던 TF-IDF 행렬은 단어의 의미를 전혀 고려하지 못한다는 단점을 갖고 있었습니다. LSA는 기본적으로 DTM이나 TF-IDF 행렬에 절단된 SVD(truncated SVD)를 사용하여 차원을 축소시키고, 단어들의 잠재적인 의미를 끌어낸다는 아이디어를 갖고 있습니다.
4. 실습을 통한 이해
1) 뉴스그룹 데이터에 대한 이해
2) 텍스트 전처리
3) TF-IDF 행렬 만들기
4) 토픽 모델링(Topic Modeling)
이제 TF-IDF 행렬을 다수의 행렬로 분해해보도록 하겠습니다. 여기서는 사이킷런의 절단된 SVD(Truncated SVD)를 사용합니다. 절단된 SVD를 사용하면 차원을 축소할 수 있습니다. 원래 기존 뉴스그룹 데이터가 20개의 카테고리를 갖고 있었기 때문에, 20개의 토픽을 가졌다고 가정하고 토픽 모델링을 시도해보겠습니다. 토픽의 숫자는 n_components의 파라미터로 지정이 가능합니다.
5. LSA의 장단점(Pros and Cons of LSA)
정리해보면 LSA는 쉽고 빠르게 구현이 가능할 뿐만 아니라 단어의 잠재적인 의미를 이끌어낼 수 있어 문서의 유사도 계산 등에서 좋은 성능을 보여준다는 장점을 갖고 있습니다. 하지만 SVD의 특성상 이미 계산된 LSA에 새로운 데이터를 추가하여 계산하려고 하면 보통 처음부터 다시 계산해야 합니다. 즉, 새로운 정보에 대해 업데이트가 어렵습니다. 이는 최근 LSA 대신 Word2Vec 등 단어의 의미를 벡터화할 수 있는 또 다른 방법론인 인공 신경망 기반의 방법론이 각광받는 이유이기도 합니다.
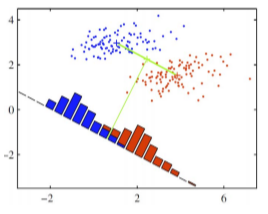
PCA의 경우 선형 분석 방식으로 값을 사상하기 때문에 차원이 감소되면서 군집화되어 있는 데이터들이 뭉개져서 제대로 구별할 수 없는 문제를 가지고 있다.
출처 https://www.youtube.com/watch?v=NEaUSP4YerM
이 그림은 2차원에서 1차원으로 PCA 분석을 이용하여 차원을 줄인 예인데, 2차원에서는 파란색과 붉은색이 구별이 되는데, 1차원으로 줄면서 1차원 상의 위치가 유사한 바람에, 두 군집의 변별력이 없어져 버렸다.
t-SNE
이런 문제를 해결하기 위한 차원 감소 방법으로는 t-SNE (티스니라고 읽음) 방식이 있는데, 대략적인 원리는 다음과 같다.
먼저 점을 하나 선택한다. 아래는 검은색 점을 선택했는데, 이 점에서부터 다른 점까지의 거리를 측정한다.
다음 T 분포 그래프를 이용하여, 검정 점(기준점) 을 T 분포 상의 가운데 위치한다면, 기준점으로부터 상대점까지 거리에 있는 T 분포의 값을 선택(위의 T 분포 그래프에서 파란 점에서 위로 점성이 올라가서 T 분포 그래프상에 붉은색으로 X 표가 되어 있는 값) 하여, 이 값을 친밀도 (Similarity)로 하고, 이 친밀도가 가까운 값끼리 묶는다.
이 경우 PCA처럼 군집이 중복되지 않는 장점은 있지만, 매번 계산할 때마다 축의 위치가 바뀌어서, 다른 모양으로 나타난다.
단 데이터의 군집성과 같은 특성들은 유지되기 때문에시각화를 통한 데이터 분석에는 유용하지만, 매번 값이 바뀌는 특성으로 인하여, 머신러닝 모델의 학습 피처로 사용하기는 다소 어려운 점이 있다.
다차원 공간에서 두 개의 점 p와q가 각각p=(p1, p2, p3,...,pn)과q=(q1, q2, q3,...,qn)의좌표를 가질 때 두 점 사이의 거리를 계산하는 유클리드 거리 공식은 다음과 같습니다.
2. 자카드 유사도(Jaccard similarity)
A와 B 두 개의 집합이 있다고 합시다. 이때 교집합은 두 개의 집합에서 공통으로 가지고 있는 원소들의 집합을 말합니다. 즉, 합집합에서 교집합의 비율을 구한다면 두 집합 A와 B의 유사도를 구할 수 있다는 것이 자카드 유사도(jaccard similarity)의 아이디어입니다.
자카드 유사도는 0과 1사이의 값을 가지며, 만약 두 집합이 동일하다면 1의 값을 가지고, 두 집합의 공통 원소가 없다면 0의 값을 갖습니다. 자카드 유사도를 구하는 함수를J라고 하였을 때, 자카드 유사도 함수J는 아래와 같습니다.
두 개의 비교할 문서를 각각doc1,doc2라고 했을 때doc1과doc2의 문서의 유사도를 구하기 위한 자카드 유사도는 이와 같습니다.
즉, 두 문서doc1,doc2사이의 자카드 유사도J(doc1, doc2)는두 집합의 교집합 크기를 두 집합의 합집합 크기로 나눈 값으로 정의됩니다.