https://velog.io/@nawnoes/10.-RNDExploration-by-Random-Network-Distillation
RND (Exploration by Random Network Distillation)
OpenAI에서 발표한 Exploration에 대한 논문. 18년도까지 여러 강화학습 알고리즘이 있었지만 Reward가 Sparse 한 환경인 몬테주마의 복수에서 인간의 성능을 최초로 넘은 방법이다.
Abstract
이 논문에서 강화학습을 휘한 Exploration bonus를 소개한다.
이 Exploration bonus는 적용하기 쉽고, 동작하는데 최소의 오버헤드가 든다.
이때 bonus는 고정되고 랜덤하게 초기화된 네트워크로부터 얻은 관측(observations)의 특징(feature)을 예측하는 신경망의 에러를 말한다.
intrinsic and extrinsic reward를 적절하게 결합하여 사용한 flexibility에 대한 method를 소개한다
이 알고리즘을 통해 몬테주마의 복수에서 SOTA를 달성하였고 인간의 성능을 뛰어넘게 된 첫 번째 방법으로 의의를 가진다.
1. Introduction
기존의 제한 사항들
강화학습은 Policy의 반환값(return)의 기댓값을 극대화하도록 동작한다. 보상(reward)가 밀집된(dense) 한 경우, 대체적으로 잘 학습한다. 하지만 보상이 뜨문뜨문한(sparse) 경우, 학습시키기 어렵다.
실제 세계에서도 모든 보상들이 밀집된 경우는 드물다. 따라서 보상이 드문 경우에도 잘 학습하기 위한 방법이 필요하다.
18년 당시 RL에서는 어려운 문제들을 풀기 위해 환경을 병렬적으로 크게 만들고 경험들을 샘플링하여 얻었지만 이러한 방법은 당시에 소개된 exploration 방법들에 대해서는 적용하는데 어려움이 있었다.
제시하는 것
간단하고 고차원의 관측에서도 잘 동작하는 Exploration bonus를 소개한다.
이 알고리즘은 policy optimization과 함께 적용할 수도 있고, 계산 효율적이기도 하다.
아이디어
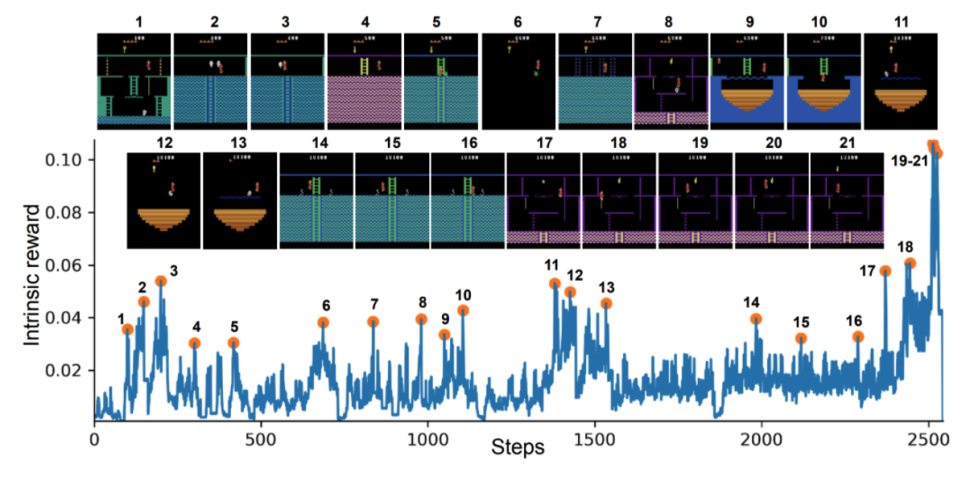
유의미한 이벤트가 발생할 때 내부 보상이 높은 것을 볼 수 있다. (2, 8, 10, 21) 은 life를 잃을 때, (3, 5, 6, 11, 12, 13, 14, 15)는 적을 아슬아슬하게 피할 때, (7, 9, 18) 은 어려운 장애물을 피할 때, 그리고 (19, 20, 21) 은 아이템을 습득할 때
이 논문에서 제시된 Exploration bonus는 신경망에서 학습된 것들과 유사한 예들에 대해서 prediction error가 현저하게 낮은 것에서 아이디어를 얻었다.
새로운 경험들의 참신함을 측정하기 위해, 에이전트의 과거 경험들에 대해 학습한 네트워크의 prediction error를 사용하였다.
prediction error를 극대화하는 것의 문제 이전에 많은 저자들이 지적했듯이 prediction error를 최대화하는 에이전트의 경우는 prediction problem의 답이 입력의 확률적 함수인 transition 들에 대해 끌리게 된다.
예를 들어 Noise TV 와 같은 예가 있다. 현재 obsevation에서 다음 observation을 예측하는 prediction problem이 있고, 이때 에이전트가 prediction error를 극대화하도록 행동한다면, 확률적 전환(stochastic transitions)을 찾도록 하는 경향이 있다.
그 예로 무작위로 변하는 아래와 같은 화면인 Noise TV와 무작위로 동전을 던지는 이벤트와 같은 것들이 있다.

문제를 극복하기 위한 대안
논문의 저자들은 적절하지 않은 stochasticity에 대한 대안을 제시한다. 답이 그것의 입력에 deterministic function인 prediction problem을 exploration bonus으로 정의하면서 대안으로 제안한다.
대안으로는, 현재 Observation에 대해서 output을 fixed randomly initialized network를 사용해서 예측한다는 것이다.
강화학습에서 어려운 게임들 🤦♂️
Bellemare의 2016년 논문에서 보상이 드물고 탐색이 어려운 게임들을 확인했다. 그 게임들로는 Freeway, Gravitar, Montezuma's Revenge, Pitfall, Private Eye, Solaris, Venture 들이 있고, 어떤 경우에서는 단 하나의 긍정보상도 찾지 못했다.
그중에서도 어려운 몬테주마의 복수
몬테주마의 복수는 강화학습에서 어려운 게임으로 여겨진다. 게임에서 치명적인 장애물을 피하기 위해 다양한 게임 스킬들에 대한 조합들이 필요하고, 최적의 플레이를 하면서도 보상이 수백 스텝 이상 떨어져 있기 때문에, 보상을 찾기에 어려운 과제로 여겨진다.
몇 논문들에서 꽤 좋은 성과를 거두었지만, expert demonstrations와 emulator state에 대한 접근 없이는 가장 좋은 성과가 전체 방의 절반만 찾아내었다.
논문에서 발견한 것 🔍
extrinsic reward 없는 경우
extrinsic reward를 무시하여도 agent가 RND exploration bonus를 극대화하도록 한다면 일관되게 몬테주마의 복수 게임에서 절반 이상의 방을 찾았다.
extrinsic reward와 exploration bonus 결합
exploration bonus와 extrinsic reward를 결합하기 위해서 수정된 PPO(Poximal Policy Optimization)을 제안한다.
수정된 PPO는 2개의 보상을 위해 2개의 value head를 사용한다.
서로 다른 보상(reward)에 대해 서로 다른 discount rate를 사용하고, episodic과 non-episodic 반환값(return)을 결합한다.
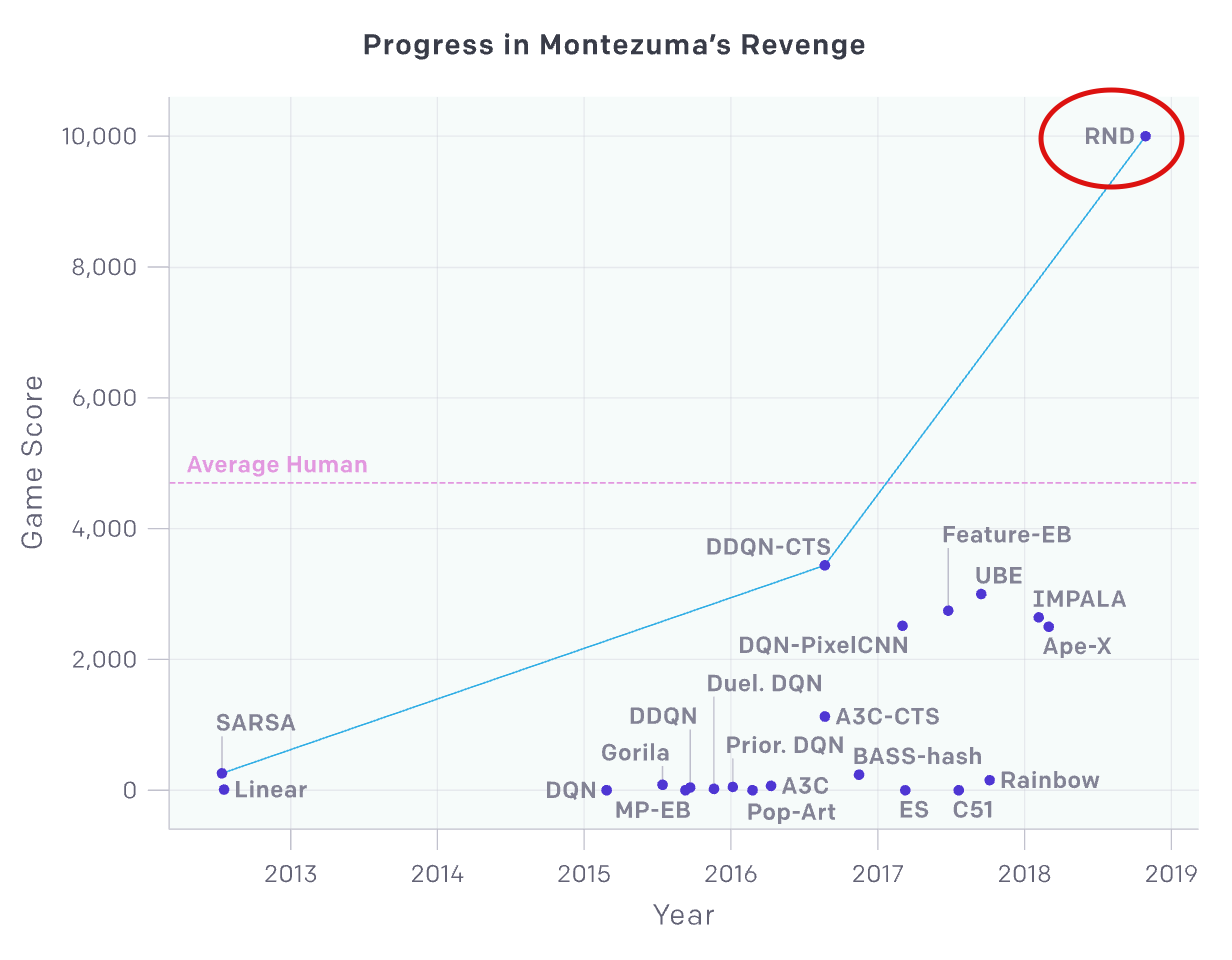
성과
first level에서 종종 몬테주마 게임에서 24개의 방 중에서 22개를 찾았고, 이따금씩 클리어하기도 했다. 그리고 같은 방법으로 Venture와 Gravitar에서 SOTA를 달성하였다.

2. Method
2.1 Exploration Bonuses
1) Count-Based
2.2 Random Network Distillation
2.2.1 Source of Prediction Errors
일반적으로 prediction error 들은 아래 요소들로부터 나온다.
1. Amount of training data
predictor가 전에 학습한 example 들과 다를수록 prediction error가 높다
2. Stochasticity
target function이 확률적이기 때문에 prediction error가 크다. stochastic transition들은 forward dynamic prediction과 같은 에러들의 원인이다.
3. Model misspecification
필요한 정보가 부족하거나 모델이 target funtion의 복잡도에 맞추기 위해 제한적인 경우
4. Learning dynamics
predictor가 target funtion을 근사하는 과정에서 최적화를 실패했을 때,
2번째 요소는 noisy TV 문제를 야기하고 3번째 요소도 적절하지 않기 때문에 RND에서는 요소 2,3을 제거한다. 3 since the target network can be chosen to be deterministic and inside
the model-class of the predictor network.
2.2.2 Relation to Uncertaionty Quantification
RND의 prediction errror는 불확실한 것을 수량화하는 것과 관련이 있다.
2.3 Combining Intrrinsic and Extrinsic Return
2.4 Reward and Observation Normalization
reward
prediction error를 exploration bonus로 사용하는 것이 보상의 크기가 환경에 따라, 시간에 따라 크게 다르기 때문에 모든 환경에서 동작하는 하이퍼파라미터를 찾는 것은 어려운 부분이 있다.
일정한 크기의 reward를 유지하기 위해서 intrinsic reward를 intrinsic reward의 표준편차들에 대한 추정치로 나누어 주어 normalization 과정을 거친다.
observation
랜덤 신경망을 사용할 때는 파라미터들이 고정되고 다른 데이터 셋들에 대해서도 조정되면 안 되기 때문에 observation normalization이 중요하다. normalization이 부족하면 임베딩의 분산이 극단적으로 낮아지고 입력에 대한 정보가 조금만 전달되는 결과가 발생할 수 있다.
이러한 문제를 해결하기 위해 continuous control 문제에서 사용하는 observation normalization scheme을 사용하고, 각 dimension에 running mean을 빼고 running standard deviation을 나누어 값을 normalization.
그 후 값이 -5와 5사이에 오도록 잘라준다.
predictor와 target network는 동일한 obsevation nomalization, policy network에 대해서는 사용하지 않는다.
References
https://arxiv.org/pdf/1810.12894.pdf
https://kr.endtoend.ai/slowpapers/rnd
https://bluediary8.tistory.com/37
https://openai.com/blog/reinforcement-learning-with-prediction-based-rewards/
https://bluediary8.tistory.com/37
Random Network Distillation 방법은 다음과 같습니다.
1. State의 feature를 뽑기 위한 Network를 랜덤으로 초기화 시키고 고정시킵니다. (Target Network, 이 네트워크는 학습하지 않습니다)
2. Target Network와 똑같은 구조를 가지는 네트워크를 초기화 시키고 (Predictor Network), Target network에서 나온 state의 feature와 이 predictor network에서 나온 feature의 차이가 최소화 되도록 학습시킵니다.
즉, predictor network를 Target Network 화 시키는 거죠. 그리고 그때 state의 차이를 Intrinsic reward로 정의합니다. 결국 다음 state의 feature space가 predictor network가 잘 예측하지 못한 state라면 더 많은 reward를 주게 되는 것이죠.
예측한 다음 state와 실제 다음 state의 차이를 intrinsic reward로 정의하는 것은 일반적인 curiosity 모델의 컨셉과 같습니다.
그러나 기존의 curiosity 모델은 현재 state와 action을 통해 다음 state를 "예측해야만" 했다면, RND는 실제 다음 state를 가지고 "feature만을 추출"합니다. 즉, 예측을 잘 해야 할 필요가 없는 것이죠.
그러므로 RND의 predictor model을 stochastic 한 게 아니라 deterministic 하게 되는 것입니다.
랜덤으로 초기화시키고 고정시킨 target network 또한, feature를 예측하는 것이 아니라, 추출의 목적이 있기 때문에 굳이 학습 시킬 필요가 없습니다.
어차피 비슷한 state에 대해서는 비슷한 output feature를 내뱉게 됩니다.
Target network의 output을 predictor network로 학습을 시키면 결국 predictor network는 target network와 비슷한 모델이 되어갑니다.
하지만 episode 과정 중에 계속 보았던 state에 대해 학습이 되기 때문에, 이전에 보았던 state에 대해서 overfitting 되게 되고, 보지 않았던 새로운 state를 보게 된다면, target network의 output 과는 조금 다른 output을 내게 됩니다.
즉, 새로운 state를 찾아가면서 하는 행동에 대해서는 reward를 많이 줄 수 있게 되는 것이죠.
이때, predictor network와 target network가 완전히 동일하게 돼서 무조건 같은 output을 내지 않을까 하는 의문이 들 수도 있습니다만, MNIST 데이터를 학습시키는 CNN 모델만 생각해도 완전히 overfitting 되는 열 개의 모델을 만들어도 각기 NN의 weight는 다르다는 것을 생각해 보면 직관적으로 절대 같아질 수 없다는 것을 이해할 수 있습니다.

Predictor: A series of 3 convolutional layers and 3 fully connected layers that predict the feature representation of s(t+1).
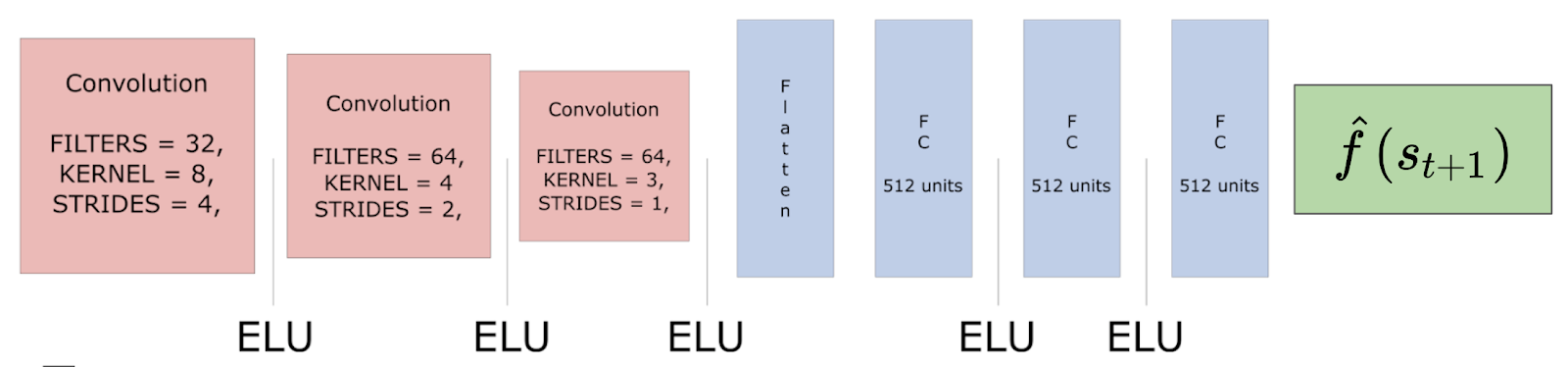
Target: A series of 3 convolutional layers and 1 fully connected layer that outputs a feature representation of s(t+1).
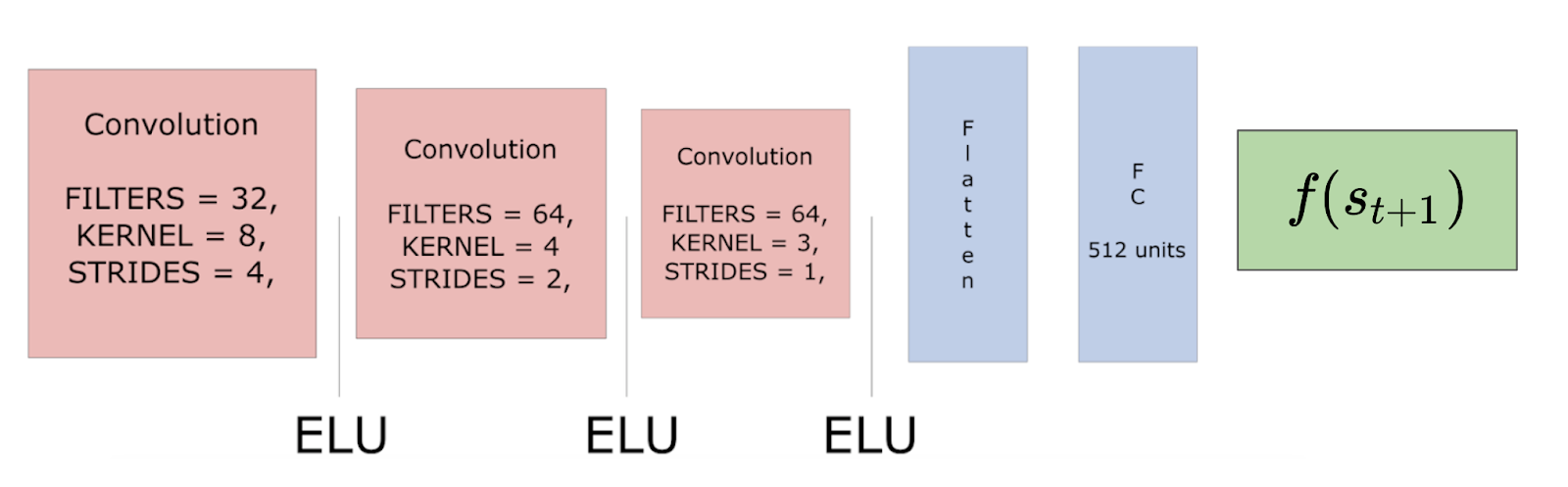
Combining Intrinsic and Extrinsic Returns
In ICM, we used only IR — treating the problem as non-episodic resulted in better exploration because it is closer to how humans explore games. Our agent will be less risk averse since it wants to do things that will drive it into secret elements.
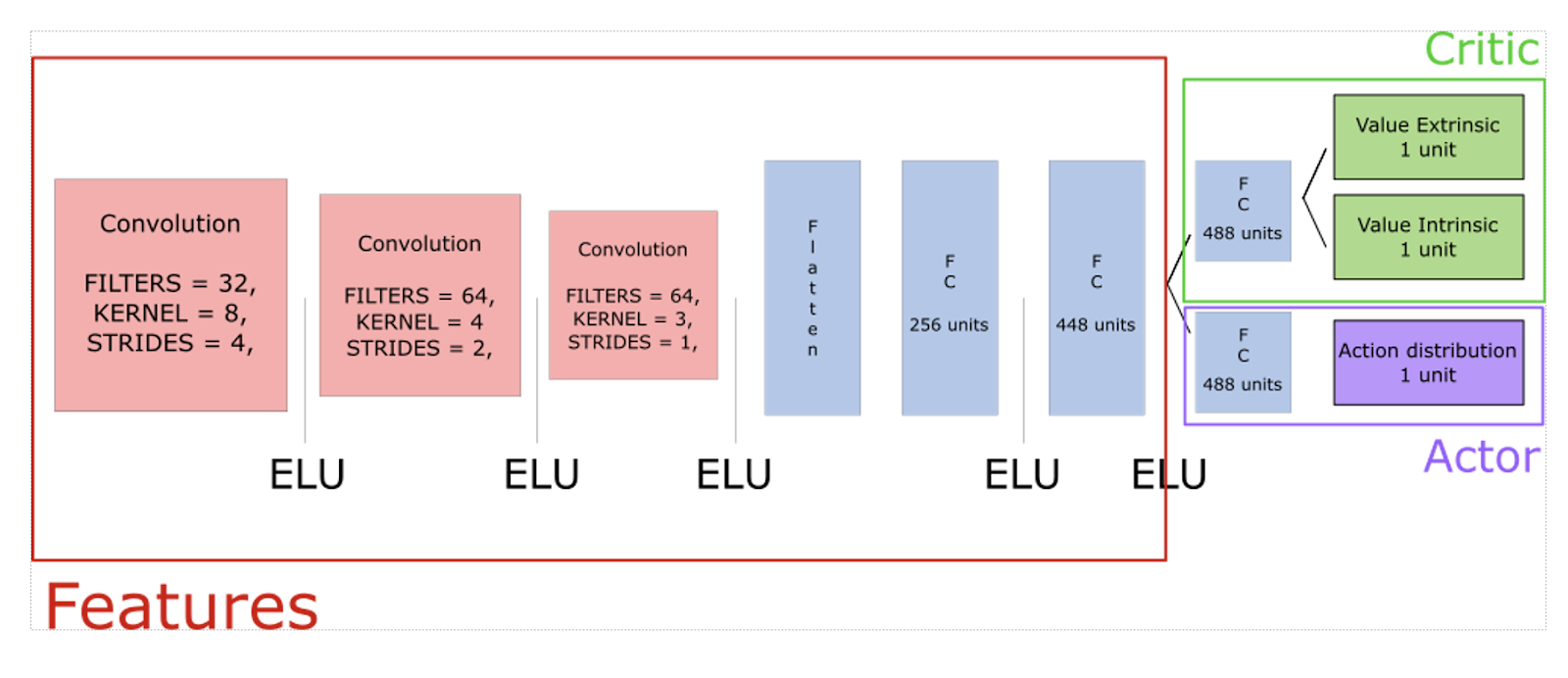
Two Value Heads
Our new PPO model needs to have two value function heads: because extrinsic rewards (ER) are stationary whereas intrinsic reward (IR) are non-stationary, it’s not obvious to estimate the combined value of the non-episodic stream of IR and episodic stream of ER.
The solution is to observe that the return is linear i.e R = IR + ER. Hence, we can fit two value heads VE and VI and combine them to give the value function V = VE + VI. Furthermore, the paper explains that it’s better to have two different discount factors for each type of reward.

'머신러닝' 카테고리의 다른 글
| 인공지능(AI) 이용하여 동화책 만들기 (1) | 2022.12.15 |
|---|---|
| 문서 요약 summarize, summarizer, summarizing (0) | 2022.11.23 |
| 강화학습 - DQN (0) | 2021.01.18 |
| 강화학습3 - Temporal Difference Learning (0) | 2021.01.17 |
| 강화학습2 - 몬테카를로 방법 (0) | 2021.01.16 |