배울 점이 많은 강의가 있어서 추천드리며, 시리즈로 글을 쓰고자 합니다.
비정형 데이터 분석 3/11 문장, 문단, 문서 임베딩(Embedding)
설명 구조
지난 시간까지 배운 내용돌아보면
가장 고전적방법
가장 보편적방법
예시로 간단히 소개

키워드 및 핵심 내용
문장, 문단, 문서, Categoly (자연어) 임베딩
Doc2Vec
- 문장 분석을 위한 임베딩
- Word2Vec과 유사한 아이디어(CBOW, Skip gram) 활용
PV-DM (Paragraph Vector - Distributed Memory model)
- paragraph-id(문서정보) + 단어들 -> 다음 단어 예측
- paragraph-id는 그 문장의 모든 단어들과 학습 -> 그 문장의 주제 정보 함축
- paragraph vector 가 문서의 주제를 저장(Memory) -> PV-DM 명명
PV-DBOW (Paragraph Vector - Distributed Bag Of Words)
- skip gram(중심단어로 주변단어 예측) : PV-DBOW(paragraph-ID로 주변단어 예측)
- paragraph vector는 그 문서(문단, 문장)의 모든 정보 함축
사례) Wikipedia 문단 벡터의 시각화(t-SNE 차원축소)
- 비슷한 주제끼리 임베딩 됨
- 리뷰 데이터의 임베딩
- 평점이 유사한 문단, 단어끼리 임베딩
- 특정 평점과 가까이 있는 문단은 해당 평점을 받을 확률이 높다는 의미
자연어 이외의 임베딩
- 일별 뉴스 임베딩
- 서로 가까이 있는 사건으로 사회, 경제, 정치적 상황의 유사성 예측 가능
- 시스템 콜 임베딩
- 시스템 작업 로그 -> 정상적 로그와 떨어져 있는 의심이 가는 이상 행동 사용자 파악
- 방송 임베딩(afreecaTV Live2Vec)
- 시간순 시청 이력을 문장, 문단으로 보고 임베딩(학습)하여 유사한 방송 추천
[유사도 기법]
1. 유클리드 거리(Euclidean distance)
다차원 공간에서 두 개의 점 p와q가 각각p=(p1, p2, p3,...,pn)과q=(q1, q2, q3,...,qn)의좌표를 가질 때 두 점 사이의 거리를 계산하는 유클리드 거리 공식은 다음과 같습니다.

2. 자카드 유사도(Jaccard similarity)
A와 B 두 개의 집합이 있다고 합시다. 이때 교집합은 두 개의 집합에서 공통으로 가지고 있는 원소들의 집합을 말합니다. 즉, 합집합에서 교집합의 비율을 구한다면 두 집합 A와 B의 유사도를 구할 수 있다는 것이 자카드 유사도(jaccard similarity)의 아이디어입니다.
자카드 유사도는 0과 1사이의 값을 가지며, 만약 두 집합이 동일하다면 1의 값을 가지고, 두 집합의 공통 원소가 없다면 0의 값을 갖습니다. 자카드 유사도를 구하는 함수를J라고 하였을 때, 자카드 유사도 함수J는 아래와 같습니다.
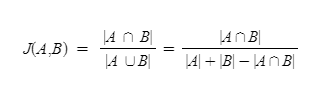
두 개의 비교할 문서를 각각doc1,doc2라고 했을 때doc1과doc2의 문서의 유사도를 구하기 위한 자카드 유사도는 이와 같습니다.
즉, 두 문서doc1,doc2사이의 자카드 유사도J(doc1, doc2)는두 집합의 교집합 크기를 두 집합의 합집합 크기로 나눈 값으로 정의됩니다.

[이은아님 강의 모음]
www.youtube.com/playlist?list=PLGAnpwASolI0vViZItiP90nWI_s9m91Av
이은아님 머신러닝 자연어처리 - YouTube
www.youtube.com

'머신러닝' 카테고리의 다른 글
| [추천강의] 이은아님 머신러닝 비정형 데이터 분석 5/11 Feature Extraction t-SNE (0) | 2020.07.09 |
|---|---|
| [추천강의] 이은아님 머신러닝 비정형 데이터 분석 4/11 Feature Selection (0) | 2020.07.08 |
| [추천강의] 이은아님 머신러닝 비정형 데이터 분석 2/11 Word2Vec (0) | 2020.07.07 |
| [인공지능 뉴스] 공동이익 추론 기반 조정, 협력, 타협 학습 (0) | 2020.07.05 |
| [추천강의] 이은아님 머신러닝 비정형 데이터 분석 1/11 신경망언어모델(NNLM) (0) | 2020.07.05 |