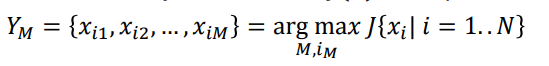배울 점이 많은 강의가 있어서 추천드리며, 시리즈로 글을 쓰고자 합니다.
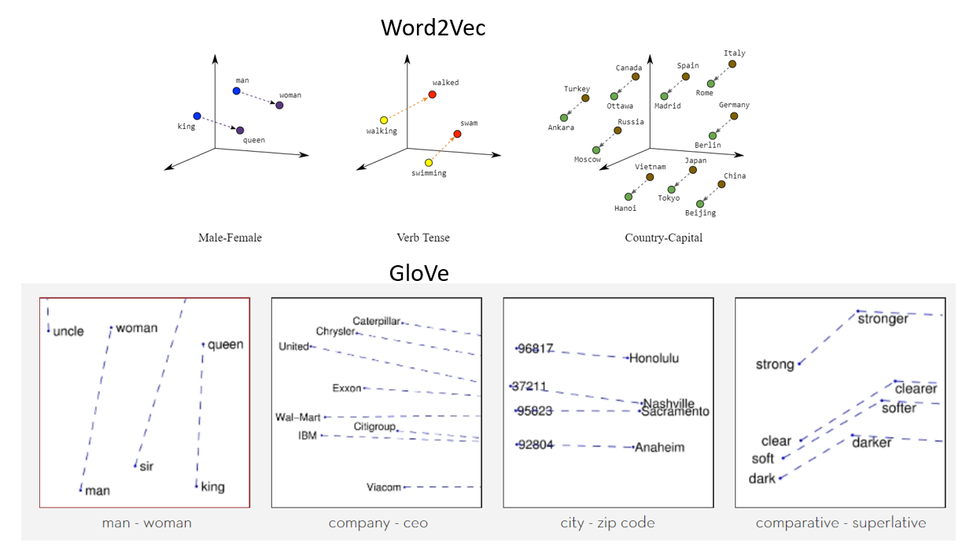
비정형 데이터 분석 5/11 Feature Extraction t-SNE
키워드 및 핵심 내용
Feature extraction 2가지 방법
- LSA
- t-SNE
t-SNE
- SNE (Stochastic Neighbor Embedding)
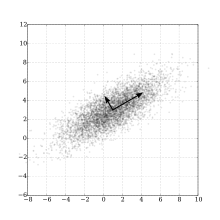
고차원의 데이터를 저차원으로 변환할 때 개체 간의 거리를 확률적으로 정하기
- Symmetric SNE
어떤 개체를 기준으로 할지에 따라 거리가 달라짐 -> 양쪽의 평균
- Crowding problem & t-SNE
normal distribution -> t-distribution -> 꼬리가 두꺼워짐 -> 웬만히 가까운 점들 이외는 멀리 배치
Crowding problem : 저차원으로 변환할 때 완벽하게 거리 보전은 불가능하다고 보고 오차를 줄이는 방향으로 학습
알고리즘
1. 개체를 임베딩 공간에 랜덤 배치
2. 각 개체에 대해 원래 공간에서의 거리가 가까우면 끌어당기고 멀면 민다
3. 모든 개체에 대해 반복하면 끝

[t-SNE 추가자료]
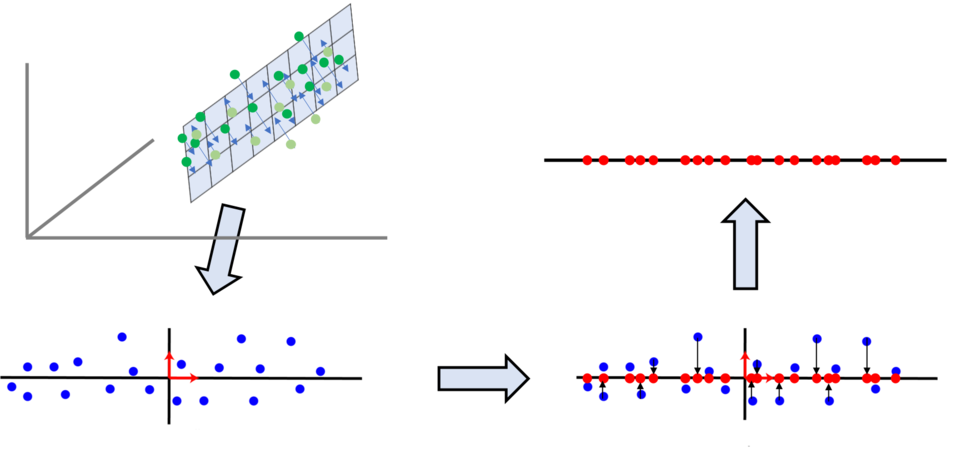
PCA 기반 차원 감소의 문제점
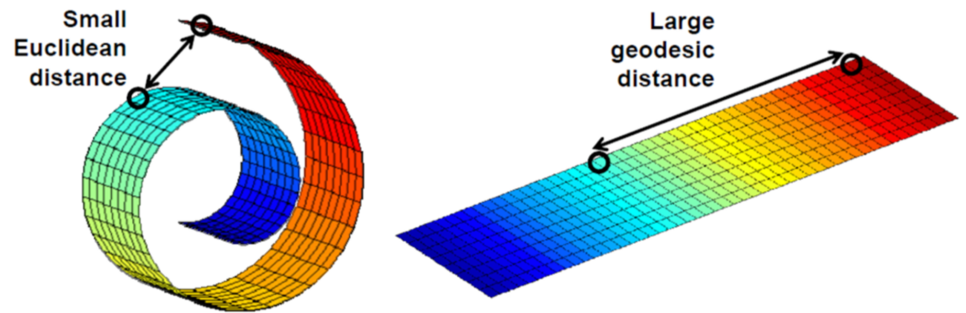
PCA의 경우 선형 분석 방식으로 값을 사상하기 때문에 차원이 감소되면서 군집화되어 있는 데이터들이 뭉개져서 제대로 구별할 수 없는 문제를 가지고 있다.

이 그림은 2차원에서 1차원으로 PCA 분석을 이용하여 차원을 줄인 예인데, 2차원에서는 파란색과 붉은색이 구별이 되는데, 1차원으로 줄면서 1차원 상의 위치가 유사한 바람에, 두 군집의 변별력이 없어져 버렸다.
t-SNE
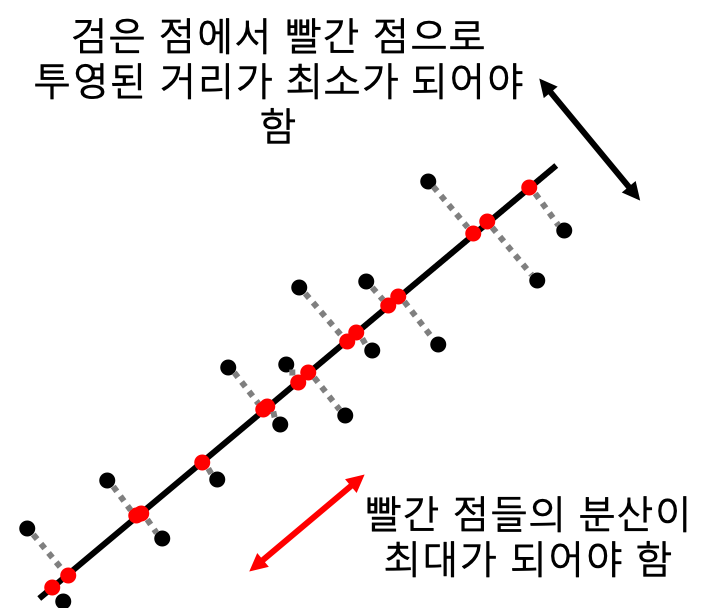
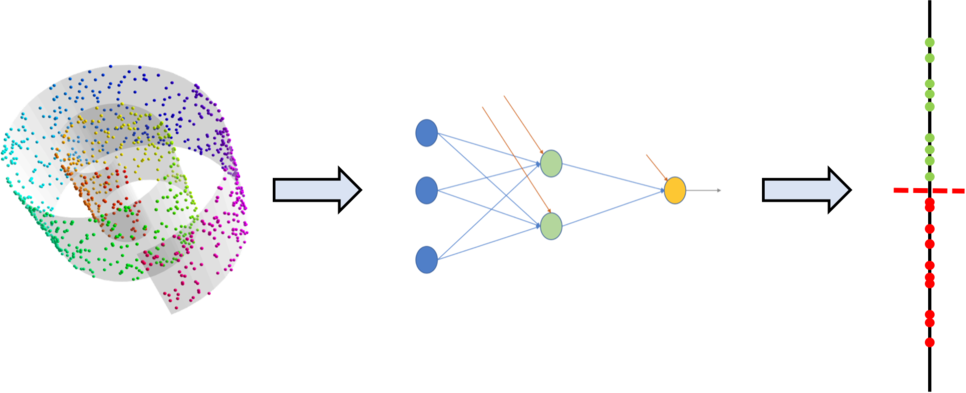
이런 문제를 해결하기 위한 차원 감소 방법으로는 t-SNE (티스니라고 읽음) 방식이 있는데, 대략적인 원리는 다음과 같다.
먼저 점을 하나 선택한다. 아래는 검은색 점을 선택했는데, 이 점에서부터 다른 점까지의 거리를 측정한다.

다음 T 분포 그래프를 이용하여, 검정 점(기준점) 을 T 분포 상의 가운데 위치한다면, 기준점으로부터 상대점까지 거리에 있는 T 분포의 값을 선택(위의 T 분포 그래프에서 파란 점에서 위로 점성이 올라가서 T 분포 그래프상에 붉은색으로 X 표가 되어 있는 값) 하여, 이 값을 친밀도 (Similarity)로 하고, 이 친밀도가 가까운 값끼리 묶는다.
이 경우 PCA처럼 군집이 중복되지 않는 장점은 있지만, 매번 계산할 때마다 축의 위치가 바뀌어서, 다른 모양으로 나타난다.
단 데이터의 군집성과 같은 특성들은 유지되기 때문에 시각화를 통한 데이터 분석에는 유용하지만, 매번 값이 바뀌는 특성으로 인하여, 머신러닝 모델의 학습 피처로 사용하기는 다소 어려운 점이 있다.
출처: https://bcho.tistory.com/1210?category=555440 [조대협의 블로그]
[이은아님 강의 모음]
https://www.youtube.com/playlist?list=PLGAnpwASolI0vViZItiP90nWI_s9m91Av
이은아님 머신러닝 자연어처리 - YouTube
www.youtube.com

'머신러닝' 카테고리의 다른 글
| [추천강의] 이은아님 머신러닝 비정형 데이터 분석 7/11 토픽모델링 LDA (0) | 2020.07.11 |
|---|---|
| [추천강의] 이은아님 머신러닝 비정형 데이터 분석 6/11 Topic Modeling: pLSA (0) | 2020.07.10 |
| [추천강의] 이은아님 머신러닝 비정형 데이터 분석 4/11 Feature Selection (0) | 2020.07.08 |
| [추천강의] 이은아님 머신러닝 비정형 데이터 분석 3/11 문장, 문단, 문서 임베딩 (0) | 2020.07.07 |
| [추천강의] 이은아님 머신러닝 비정형 데이터 분석 2/11 Word2Vec (0) | 2020.07.07 |