배울 점이 많은 강의가 있어서 추천드리며, 시리즈로 글을 쓰고자 합니다.
비정형 데이터 분석 4/11 Feature Selection
키워드 및 핵심 내용
차원축소(Dimensionality Reduction)
- Feature Selection
- Feature Extraction
Feature Selection
- Feature를 가공 없이 선택해서 사용
Feature Selection 지표
F1 (데이터의 밸런스가 맞지 않을 때 즉 각 class 비중이 차이가 날 경우 사용)
- Recall = TP / (TP + FN) : 긍정문서 중 해당 Term 등장 횟수
- Precision = TP / (TP + FP) : 해당 Term 이 나타난 문서 중 긍정문서의 개수
- Harmonic Mean(조화평균) : 큰 값에 페널티 -> 작은 값의 비중 높임
- F1 Score = 2 x ( Precsion x Recall ) / ( Precision + Recall )
- F1 단점 : 긍정문서를 잘 판독하는 단어에 높은 점수, 상대적으로 부정문서를 판독하는 단어에 낮은 점수
IG (Information Gain)
- 분류기에 의해서 얼마나 정보가 발생했는지로 판단
- Entropy(무질서의 정도) -> 정보 -> Entropy 낮아짐
- 단어(feature)의 등장에 의해 전후 Entropy의 차이가 클수록 그 단어(feature)에 높은 점수
X2 (Chi(카이)-squared Statistic)
- 해당 단어의 출현 여부와 긍정, 부정 분류가 통계적으로 완전히 독립적이라면 기댓값을 구할 수 있다는 아이디어
- X^2으로 나온 결괏값이 크다는 것은 우리가 가정한 독립성의 가정에 적합하다는 것을 의미한다.
BNS (Bi-Normal Separation)
- 잘 안 쓰임
PR, OddR, OddN / Acc, AccR / DF

[Feature Selection 추가 자료]
https://blog.naver.com/jamiet1/221419434072

1. Feature Selection vs Feature extraction
둘 다 차원 감소를 하는 방법이다.
- Feature selection : 변환 없이 원래 있는 d개 feature 중 m개만 뽑아 쓰겠다는 것
- Feature extraction : d개 feature를 m 차원 공간 벡터로 변환시키는 것
2. Feature Subset Selection(#FSS)
정확도가 높은 목적함수 J(Y)를 찾는 것
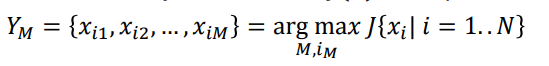
왜 feature extraction 안 하고 FSS를 할까?
1) feature를 획득하기 어렵거나 비싼 경우
test 해야 하는 feature는 너무 많은데 final 선택은 한 개... 막 이런 경우
2) 내 classifier에서 의미 있는 rule을 추출하고 싶은 경우
project 할 때, feature들이 사라질 가능성도 있으니까
3) feature가 숫자가 아니라 test나 모양일 경우
feature를 줄이면
1) 일반화 성능이 올라간다.
2) 복잡도와 실행시간이 줄어든다.
3. Search strategy and objective function
feature를 어떻게 선택해볼까?
목적함수는 뽑아낸 것이 용도에 맞게 잘 뽑아냈는지를 판단해야 한다.
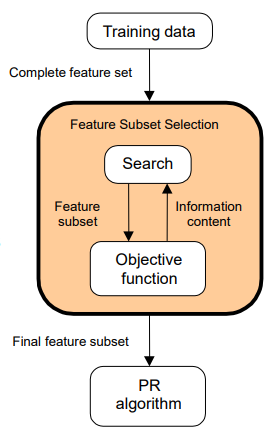
1) Filter : feature, 클래스 간 정보를 이용한다
- 클래스 간 거리... (유클라드, 멘하탄)
- separability... (LDA 고윳값)
- 상관관계... 상관관계의 여부를 따져본다
- 정보이론
1-1) 선형 관계 : correlation coefficient를 이용한다

Pic : feature i와 클래스 label 간의 correlation coefficient
Pij : feature i, j 간 correlation coefficient
1-2) 비선형 관계 : 상호 정보량 I를 사용한다.
상관관계는 선형에서만 가능하니까.

I(Ym, C) : feature 벡터와 클래스 label 간 상호 정보량으로 클래스 불확실성의 양.
H(.) : 엔트로피 함수
상호 정보량이 0 이면 독립이니까 변별 불가능하다.
상호정보량이 큰 걸 선택한다.

가중치를 넣어서 빼준다.
장점 1 : 계산이 빠르다. 데이터셋에 대한 반복 계산 없다. training 빠름.
장점 2 : 일반화. 데이터의 고유 형태를 평가하기 때문에 어떤 형태의 분류기가 와도 좋은 성능을 가진다.
단점 : large subset을 고르는 경향이 있다. 목적 함수 자체가 단조로워서... 모든 feature를 선택해버리기도 한다. user가 선택할 feature의 수를 직접 골라줘야 함.
2) Wrapper : classifier를 사용한다.
cross-validation이나 resampling 같은 것
매번 인식기 모델을 훈련 후 cross-validation 해준다.
장점 1 : 정확도.
장점 2 : 일반화 능력. 오버 피팅을 피하는 메커니즘을 통해 상승!
단점 1 : 느린 실행 속도. subset마다 classifier training
단점 2 : 부족한 일반화. classifier의 평가 함수에 달려있다.
즉, 목적함수에서 선택한 분류기의 성능에 따라 일반화 정도가 갈린다.
[출처][패턴인식] sequential feature selection|작성자Karen
[허민석님 강의] 다중 분류 모델 성능 측정 (accuracy, f1 score, precision, recall on multiclass classification)
[IG, X2 추가 자료]
http://freesearch.pe.kr/archives/1324
Feature Selection - from __future__ import dream
Machine Learning을 하기 전에 수가지의 후보 Feature 셋중에 쓸만한 것들을 골라내는 작업을 한다. 이 작업이 필요한 이유는 쓸데없는 noise feature를 추가할 경우 실험셋에서만 적합한 classifier가 나올 ��
freesearch.pe.kr
확률적인 단점 때문에 chi-square 방법이 feature 셋을 작게 선정했을 때 성능이 좋지 않다고 한다.
예를 들어 spam class에 erlang이 한번 나왔다고 그것을 스팸 확률을 100으로 주는 건 문제가 있는 것과 비슷하다.
저런 저빈도 고확률의 feature들이 다 선택이 되고 난 다음에 선택되는 고빈도 중확률 feature들과의 조화로 인해 feature 셋이 추가될수록 성능은 나아진다고 한다.
물론 위의 단점을 보완하기 위한 Roinson의 희소 확률 보정식 같은 게 있긴 하지만 이런 카이제곱 방법의 단점은 알아두는 게 좋을 거 같다.
Mutual Information 방법은 feature 선정 초반에 정확도가 높아지다가 셋이 추가될수록 점점 하강하는 곡선을 탄다.
따라서 feature 셋의 크기가 작게 선정이 되어야 되는 경우라는 Mutual Information 방법이 더 나을 거란 생각을 해본다.
[이은아님 강의 모음]
https://www.youtube.com/playlist?list=PLGAnpwASolI0vViZItiP90nWI_s9m91Av


'머신러닝' 카테고리의 다른 글
| [추천강의] 이은아님 머신러닝 비정형 데이터 분석 6/11 Topic Modeling: pLSA (0) | 2020.07.10 |
|---|---|
| [추천강의] 이은아님 머신러닝 비정형 데이터 분석 5/11 Feature Extraction t-SNE (0) | 2020.07.09 |
| [추천강의] 이은아님 머신러닝 비정형 데이터 분석 3/11 문장, 문단, 문서 임베딩 (0) | 2020.07.07 |
| [추천강의] 이은아님 머신러닝 비정형 데이터 분석 2/11 Word2Vec (0) | 2020.07.07 |
| [인공지능 뉴스] 공동이익 추론 기반 조정, 협력, 타협 학습 (0) | 2020.07.05 |