배울 점이 많은 강의가 있어서 추천드리며, 시리즈로 글을 쓰고자 합니다.
비정형 데이터 분석 6/11 Topic Modeling: pLSA
키워드 및 핵심 내용
Topic Modeling
LSA
- Probabilistic Latent Semantic Analysis (확률적 잠재 의미 분석)
pLSA 개념
- 문장의 등장하는 단어는 Latent Concepts (잠재 의미, 주제, Topic)에 따른다
parameter 추론
- Maximum Likelihood Estimator (MLE) 을 통해 parameter 추정
- MLE : 데이터로부터 (정규, 지수, 감마) 분포를 알아냄 -> 모집단의 평균, 분산, ...
- Likelihood function 최대화
pLSA 학습
- EM 알고리즘(최적해 찾기)
- 동시에 최적화할 수 없는 복수의 변수들을 반복적으로 계산하는 기법
- E-step
- M-step
[pLSA 추가 자료]
https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/05/25/plsa/
LSA
pLSA는 기존잠재 의미분석(Latene Semantic Analysis) 과는아예 다른 기법이지만 개념을 공유하는 게 많아서 먼저 설명해볼까 합니다. LSA에 대한 자세한 내용은이곳을 참고하시면 좋을 것 같습니다. 어쨌든 LSA는 말뭉치 행렬A를 다음과 같이 분해하는 걸 말합니다.
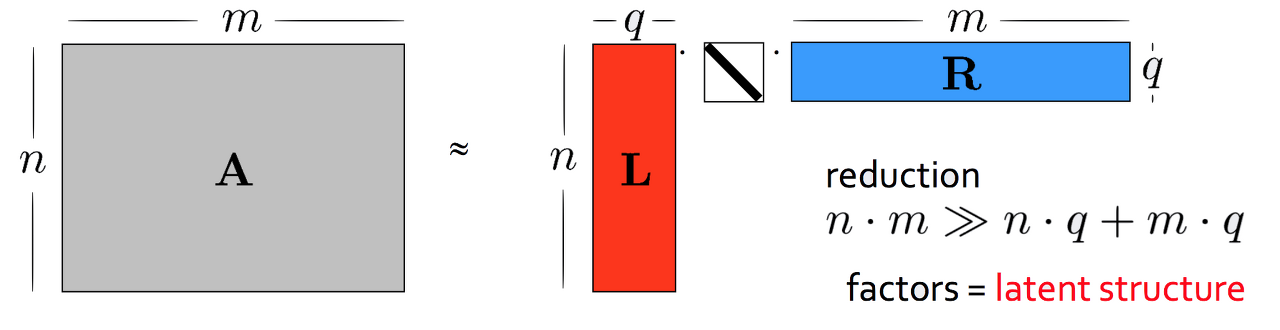
LSA 수행 결과로n 개문서가 원래 단어 개수보다 훨씬 작은q 차원의벡터로 표현된 걸 확인할 수 있습니다.
마찬가지로m 개단어는 원래 문서 수보다 훨씬 작은q 차원벡터로 변환됐습니다.
q가 3이라면 전체 말뭉치가 3개의 토픽으로 분석됐다고도 말할 수 있을 것입니다.
위 그림에서 행렬L의 열벡터는 각각 해당 토픽에 대한 문서들의 분포 정보를 나타냅니다.
R의 행벡터는 각각 해당 토픽에 대한 단어들의 분포 정보를 나타냅니다.
중간에 대각행렬은q 개토픽 각각이 전체 말뭉치 내에서 얼마나 중요한지 나타내는 가중치가 될 겁니다.
pLSA
pLSA는 단어와 문서 사이를 잇는, 우리 눈에 보이지 않는 잠재 구조가 있다는 가정 하에 단어와 문서 출현 확률을 모델링 한 확률모형입니다.
pLSA는 아래 그림처럼Latent concepts가 존재하고 이것이 문서와 단어를 연결한다고 가정합니다. 문서들의 주제(토픽)이라고 생각하면 좋을 것 같습니다.

왼쪽부터 차례로 살펴보겠습니다. P(z|d)는 문서 하나가 주어졌을 때 특정 주제(토픽)가 나타날 확률을 의미합니다. P(w|z)는 주제가 정해졌을 때 특정 단어가 나타날 확률을 가리킵니다.
LSA와 pLSA
LSA는 행렬 인수분해(matrix factorization),
pLSA는 확률모형입니다.
아예 그 종류가 다르다고 할 수 있죠. 하지만 개념상 연결되는 부분이 있습니다. 그래서일까요? 이름도 좀 많이 비슷해요. 어쨌든 아래 그림을 보겠습니다.

LSA 결과물인 행렬Uk의 열벡터는 각각 해당 토픽에 대한 문서들의 분포 정보를 나타냅니다. 이는 pLSA의 P(d|z)에 대응합니다.
행렬Vk의 행벡터는 각각 해당 토픽에 대한 단어들의 분포 정보를 나타냅니다. 이는 pLSA의 P(w|z)에 대응합니다.
Σk의 대각성분은 토픽 각각이 전체 말뭉치 내에서 얼마나 중요한지 나타내는 가중치가 됩니다. 이는 pLSA의 P(z)에 대응합니다.
pLSA의 결과물은 확률이기 때문에 각 요솟값이 모두 0 이상, 전체 합이 1이 됩니다. 하지만 LSA는 이런 조건을 만족하지 않습니다.
pLSA의 목적식
pLSA는m 개단어,n 개문서,k 개주제(토픽)에 대해 아래 우도 함수를 최대화하는 걸 목표로 합니다.

위 식에서n(wi,dj)는j 번째문서에i 번째단어가 등장한 횟수를 나타냅니다.
p(wi,dj)는k 개주제(토픽)에 대해 summation 형태로 돼 있는데요. 같은 단어라 하더라도 여러 토픽에 쓰일 수 있기 때문입니다.
예컨대 정부(government) 같은 흔한 단어는 정치, 경제, 외교/국방 등 다양한 주제에 등장할 수 있습니다.
pLSA의 학습 : EM 알고리즘
EM 알고리즘은동시에 최적화할 수 없는 복수의 변수들을 반복적인 방식으로 계산하는 기법입니다. 우선 모든 값을 랜덤으로 초기화합니다. 이후 하나의 파라미터를 고정시킨 다음에 다른 파라미터를 업데이트하고, 이후 단계에선 업데이트된 파라미터로 고정시킨 파라미터를 다시 업데이트합니다. 다음과 같습니다.

[LSA 추가 자료]
https://www.wikidocs.net/24949
1. 특이값 분해(Singular Value Decomposition, SVD)
여기서의 특이값 분해(Singular Value Decomposition, SVD)는 실수 벡터 공간에 한정하여 내용을 설명함을 명시합니다.
SVD란 A가 m × n 행렬일 때, 다음과 같이 3개의 행렬의 곱으로 분해(decomposition) 하는 것을 말합니다.

2. 절단된 SVD(Truncated SVD)
위에서 설명한 SVD를 풀 SVD(full SVD)라고 합니다. 하지만 LSA의 경우 풀 SVD에서 나온 3개의 행렬에서 일부 벡터들을 삭제시킨 절단된 SVD(truncated SVD)를 사용하게 됩니다.

3. 잠재 의미 분석(Latent Semantic Analysis, LSA)
기존의 DTM이나 DTM에 단어의 중요도에 따른 가중치를 주었던 TF-IDF 행렬은 단어의 의미를 전혀 고려하지 못한다는 단점을 갖고 있었습니다. LSA는 기본적으로 DTM이나 TF-IDF 행렬에 절단된 SVD(truncated SVD)를 사용하여 차원을 축소시키고, 단어들의 잠재적인 의미를 끌어낸다는 아이디어를 갖고 있습니다.
4. 실습을 통한 이해
1) 뉴스그룹 데이터에 대한 이해
2) 텍스트 전처리
3) TF-IDF 행렬 만들기
4) 토픽 모델링(Topic Modeling)
이제 TF-IDF 행렬을 다수의 행렬로 분해해보도록 하겠습니다. 여기서는 사이킷런의 절단된 SVD(Truncated SVD)를 사용합니다. 절단된 SVD를 사용하면 차원을 축소할 수 있습니다. 원래 기존 뉴스그룹 데이터가 20개의 카테고리를 갖고 있었기 때문에, 20개의 토픽을 가졌다고 가정하고 토픽 모델링을 시도해보겠습니다. 토픽의 숫자는 n_components의 파라미터로 지정이 가능합니다.
5. LSA의 장단점(Pros and Cons of LSA)
정리해보면 LSA는 쉽고 빠르게 구현이 가능할 뿐만 아니라 단어의 잠재적인 의미를 이끌어낼 수 있어 문서의 유사도 계산 등에서 좋은 성능을 보여준다는 장점을 갖고 있습니다. 하지만 SVD의 특성상 이미 계산된 LSA에 새로운 데이터를 추가하여 계산하려고 하면 보통 처음부터 다시 계산해야 합니다. 즉, 새로운 정보에 대해 업데이트가 어렵습니다. 이는 최근 LSA 대신 Word2Vec 등 단어의 의미를 벡터화할 수 있는 또 다른 방법론인 인공 신경망 기반의 방법론이 각광받는 이유이기도 합니다.
[Latent Space 추가자료]
https://blog.naver.com/qbxlvnf11/221752228681
오토인코더(autoencoder), GAN (Generative Adversarial Networks) 등의 생성 모델은 학습 과정 중 잠재 공간 (latent space)을 만들어낸다.
일반적인 경우 이 잠재 공간은 고정된 차원의 연속적인 표현형 공간(continous representations)으로 나타내어지지만 이는 해석(interpretation) 하기 힘들 뿐만이 아니라 효율성이 떨어지는 측면이 있다.
그래서 잠재 공간을 이산적인 표현형 공간(discrete representations)으로 나타내려 하는 연구가 활발히 진행 중이다.
물론 이렇게 할 경우 trade-off로 그레디언트(gradients) 계산 즉, 최적화(optimization)이 쉽지 않다는 문제가 발생한다.
그럼에도 불구하고 위에서 언급했던 장점과 함께 지금껏 해석하기도 어려웠던 잠재 공간의 컨트롤 가능에 대한 희망과 설명 가능한(explainable) 인공지능 개발의 키가 될 수 있다는 것 때문에 최근에 활발히 연구되고 있는 분야이다.
이 기술은 순환 모델(recurrent model)의 효율성(efficiency) 강화를 통한 수렴 속도 향상, 다양한 잠재 공간 컨트롤을 통한 여러 언어 번역, 화자 분리 문제에서의 타깃 화자 선택 문제 등 머신러닝에서 산재하는 많은 문제에 응용될 수 있을 것이다.
[출처] Discrete latent space에 대한 연구|작성자 예비개발자
[이은아님 강의 모음]
https://www.youtube.com/playlist?list=PLGAnpwASolI0vViZItiP90nWI_s9m91Av
이은아님 머신러닝 자연어처리 - YouTube
www.youtube.com

'머신러닝' 카테고리의 다른 글
| [추천강의] 이은아님 머신러닝 비정형 데이터 분석 8/11 LDA Inference: Collapsed Gibbs Sampling (0) | 2020.07.13 |
|---|---|
| [추천강의] 이은아님 머신러닝 비정형 데이터 분석 7/11 토픽모델링 LDA (0) | 2020.07.11 |
| [추천강의] 이은아님 머신러닝 비정형 데이터 분석 5/11 Feature Extraction t-SNE (0) | 2020.07.09 |
| [추천강의] 이은아님 머신러닝 비정형 데이터 분석 4/11 Feature Selection (0) | 2020.07.08 |
| [추천강의] 이은아님 머신러닝 비정형 데이터 분석 3/11 문장, 문단, 문서 임베딩 (0) | 2020.07.07 |