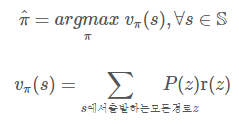[RL] 강화학습 part1 - policy, value function Reinforcement Learning 1. 강화학습 원리와 성질 state, action을 번갈아 가면서 목표를 달성합니다. 강화학습 교과서(Sutton, 2017) 참고 1) 계산 모형 상태, 행..
wordbe.tistory.com
강화학습의 목표는 '누적' 보상액을 최대화하는 것입니다.
에이전트가행동을 선택하는 데 사용하는 규칙을 정책(policy)이라고 하며, 강화 학습 알고리즘은최적의 정책을 찾아야 합니다.
탐험과 탐사 갈등(Exploration and exploitation conflict) :
k-손잡이 밴딧(k-am bandit) 문제
이 둘의 방식을 보완하기 위해 균형 방식을 사용합니다.
2번에서 잭팟이 나온 이후로 2번 기계를 더 자주 선택하는 대신다른 기계에게도 계속 기회를 주며 잭팟이 또 터지면 새로운 정보를 고려하여 확률을 배분하고 수정하는 것입니다.
마르코프 결정 프로세스(MDP)Markov Decision Process
현재 상태에서 행동을 결정할 때 이전 이력은 중요하지 않고, 현재 상황이 중요한 조건을 마르코프 성질(Markov Property)을 지녔다고 합니다. 예를 들면 바둑이 있습니다.
강화학습은 마르코프 성질을 만족한다는 전제하에 동작합니다.
따라서 Markov property를 근사하게라도 만족하는 문제에 국한하거나, 근사하게 만족할 수 있도록 상태 표현을 설계해서 적용합니다.
결정론적(Deterministic) MDP : 딱 한가지 상태와 보상이 있는 경우, 나머지 보상은 전부 0
확률론적(Stochastic) MDP : 다음 상태와 보상이 확률적으로 결정되는 경우
정책과 가치함수
강화 학습의 핵심은 좋은 정책을 찾아내는 것입니다.
좋은 정책이 있으면 누적 보상을 최대로 만들 최적 행동을 매 순간 선택할 수 있습니다.
정책 공간은 너무 방대해서 최적 정책을 찾는 접근 방법은 무모하며,
최적 정책을 찾아가는 길잡이 역할을 하는 가치함수를 소개합니다.
1) 정책(policy)
정책이란 상태 s에서 행동 a를 취할 확률을 모든 상태와 행동에 대해 명시한 것입니다.
최적 정책 찾기
goodness(π)가 정책π의 품질을 측정해주는 함수라고 합시다.
학습 알고리즘은 위를 만족하는 정책 π^를 알아내어야 합니다.
바둑 같은 문제 에서는 상태공간(state space)이 방대합니다.
정책 공간(policy space)은 서로 다른 정책 집합을 뜻하며, 상태 공간보다 훨씬 방대합니다.
따라서 강화학습에서는 정책공간을 일일이 직접 탐색하는 대신 '가치함수'를 이용합니다.
최적 가치함수를 찾으면 최적 정책을 찾는 것은 사소한(trivial) 문제가 됩니다.
2) 가치함수(Value function)
가치함수는 특정 정책의 좋은 정도(상태 s로부터 종료 상태 이르기까지 누적 보상치의 추정치)를 평가합니다.
정책π에서 추정하며 상태 s의 함수이므로vπ(s)로 표기합니다.
즉, 위에서 쓰인 goodness는 곧 가치함수로 바뀝니다.
P(z)는 경로 z의 발생확률, r(z)는 경로 z의 누적 보상액입니다.
강화학습에서 유한 경로를 가진 과업을 에피소드 과업(episode task)이라고 합니다.
반면, 무한경로를 가진 과업을 영구과업(continuing task)이라고 합니다.
특별히 영구과업은 무한대 보상을 막기 위해 할인 누적 보상액(discounted accumulating reward)을 사용합니다.
γ를 할인율(discounting rate)이라고 하며,0≤γ≤1입니다.
0이면rt+1만 남으므로순간의 이득을 최대화하는 탐욕 방법인 근시안적 보상액이 되며,
1이면 맨 위의 식처럼 된다.
따라서 할인 누적 보상액은현재에서 멀어질수록 보상을 할인하여 공헌도를 낮추는 전략을 사용합니다.
가치함수 추정을 위한 순환식
마치 점화식처럼, 다음 상태에서의 가치함수를 표현하여, 가치함수를 간단히 쓸 수 있습니다.
스토캐스틱 프로세스에서 가치함수 추정
지금 까지 수식은 결정론적 프로세스(deterministic process)였습니다.
결정론적 프로세스는 많은 응용을 설명하지 못하지만,
현실에서 모든 요인을 상태 변수에 반영하는 대신 주요 요인만 반영하고 나머지는 무시한 상황서의 상태, 행동, 보상을 스토캐스틱 프로세스(stochastic process)라고 합니다.
스토캐스틱한 성질은P(s', r|s,a)확률로 표현됩니다. 이는MDP 확률분포입니다. 즉,상태 s에서 행동 a를 취했을 때 상태 s'로 전환하고 보상 r을 받을 확률입니다. 스토캐스틱은 이 값이 여러개일 수 있으므로, 모두 더해줍니다.
가치함수는 MDP 확률분포가 제공하는 정보와 정책 π가 제공하는 정보를 모두 활용하여 정책을 평가합니다.
무한 경로를 가진 응용문제에는 할인율을 적용한식을 사용하면 됩니다.
위 두식은상태 가치 함수(State value function)라고 합니다.
위 두식의 순환식을 가치함수를 위한벨만 수식(Bellman equation)이라고 하며,현재 상태의 가치는 다음 상태의 가치의 관계를 간결하게 표현합니다.
이와는 다르게 상태와 행동에 대한 가치함수는상태-행동 가치함수(state-action value function)라고 하며 식은 아래와 같습니다.
3) 최적 가치 함수
최적 가치함수를 알아 최적 정책을 쉽게 결정할 수 있습니다.
상태 가치함수는 mean 연산을 통해 구하는 반면, 최적 가치함수는 max 연산을 통해 구합니다.
1) 처음에는 임의값으로 정책을 설정하고 출발합니다.
2) 정책에 따라 가치함수를 계산합니다.(정책의 품질 평가)
3) 얻은 가치함수로 더 나은 정책으로 개선합니다.
정책의 평가와 개선은 MDP 확률분포를 기초로 이루어집니다.
4) 정책 개선 싸이클이 없을 때까지 반복합니다.
동적 프로그래밍, 몬테카를로 방법, 시간차 학습 알고리즘은 모두 이 아이디어에 근거합니다.
명쾌한 코드 파이썬으로 어둠의 마법을 부릴 수 있다면, 가장 명쾌하고 간단한 방법을 추천합니다. 나쁜 예 def make_complex ( * args ): x , y = args return dict ( ** locals ()) 좋은 예 def make_complex ( x , y ): return { 'x' : x , 'y' : y } 위의 좋은 코드 예시에서 x와 y는 호출자로부터 직접 값을 받아와 곧바로 딕셔너리로 반환합니다. 이 함수를 쓰는 개발자들은 첫 줄과 마지막 줄을 읽는 것만으로 무엇을 하는 함수인지 정확히 알 수...
파이썬 코딩 스타일 PEP 8 파이썬 코딩 스타일 Python Enhancement Proposal 8 (PEP 8)은 파이썬 코딩 스타일에 대한 가이드를 제시하고 있다. PEP 8은 2001년 귀도 반 로썸에 의해 처음 제안되었으며, python.org 의 PEP 링크에 자세히 소개되어 있다. 파이썬 프로그래머들은 일반적으로 이러한 PEP 8 코딩 스타일에 따라 프로그래밍을 하고 있는데, 이러한 일관된 코딩 스타일을 적용하는 것은 자신의 코드를 명료하게 할 뿐만 아니라 특히 다른 개발자 혹은 커뮤니...
도메인 주도 설계에서 도메인이란 우리가소프트웨어로 “해결하고자 하는 문제 영역”을 의미합니다.
.
일반적으로 UML(Unified Modeling Language)에서 자주 사용하는 “클래스 다이어그램(Class Diagram)”부터, 필요에 따라 “상태 다이어그램(State Diagram)”이나 “시퀀스 다이어그램(Sequence Diagram)”을 사용할 수도 있고, 아니면 UML이 아닌 다른 방식으로 표현해도 무방합니다.
다만 도메인 모델을 표현할 때 최대한 표현력을 가질 수 있게 단순히 속성만 나열하는 것이 아니라 행위를 통해 도메인 기능을 나타내도록, 그리고 실제로 사용하는 도메인 용어를 사용하도록 해야 합니다.
도메인 객체는 기본적으로 “엔티티(Entity)”와 “밸류(Value)”로 구분할 수 있습니다.
엔티티는 식별성과 연속성을 가지는 객체인데, 좀 더 풀어서 얘기하자면 고유한 식별자로 식별할 수 있으며 자신의 상태와 라이프사이클(Life cycle)을 가지는 도메인 객체입니다.
밸류는 개념적으로 묶을 수 있는 데이터 집합을 표현합니다. 도메인 주도 설계를 몰랐더라도 자주 들었던 “값 객체(Value Object)”라고 부르는 것이 바로 이것입니다. 밸류를 사용하면 각각의 데이터를 단일로 취급할 때보다 표현력을 향상시킬 수 있습니다.
더불어 엔티티와 밸류의 메서드(행위)로 기능과 제약을 표현하고, 습관적으로 사용하는 setter/getter 메서드는 지양하라고 최범균님이 언급하셨는데,
// case 1
if (order.getStatus() == OrderStatus.DELIVERY_IN_PROGRESS)
저는 case 2가 case 1보다 무엇을 하고자 하는지 그 의도가 비교적 분명하게 느껴지고,
case 2처럼 만든 객체가 도메인 기능을 잘 표현하고 있는 도메인 객체라고 생각합니다.
애그리거트(Aggregate)
도메인 모델은 점차 복잡해지기 마련입니다. 서비스가 자랄수록 도메인 역시 함께 자라기 때문입니다. 이렇게 도메인 모델의 복잡도는 점차 증가하기 마련인데, 이러한 복잡도를 관리하기 위해 도메인 객체들의 묶음이자 집합체인 “애그리거트(Aggregate)”가 필요합니다. 애그리거트를 사용하면 우리가 다루는 도메인 객체를 좀 더 상위 수준으로 추상화할 수 있습니다.
이러한 애그리거트에는 포함된 객체들의 대표가 되는 “애그리거트 루트(Aggregate root)”가 필요합니다. 애그리거트에는 다수의 객체들이 포함되어 있고 이들은 함께 움직이면서 일관성을 유지해야 하는데, 만약 바깥에서 애그리거트 내부의 객체들에게 직접 접근해서 상태나 속성을 변경해버리면 일관성이 깨져버립니다.
따라서 애그리거트 바깥에서 애그리거트에 직접 접근할 수 있는 곳은 오직 애그리거트 루트 뿐이어야 합니다. 애그리거트 루트가 이러한 창구 역할을 하면서 애그리거트에 포함된 객체들의 일관성을 유지할 수 있습니다.
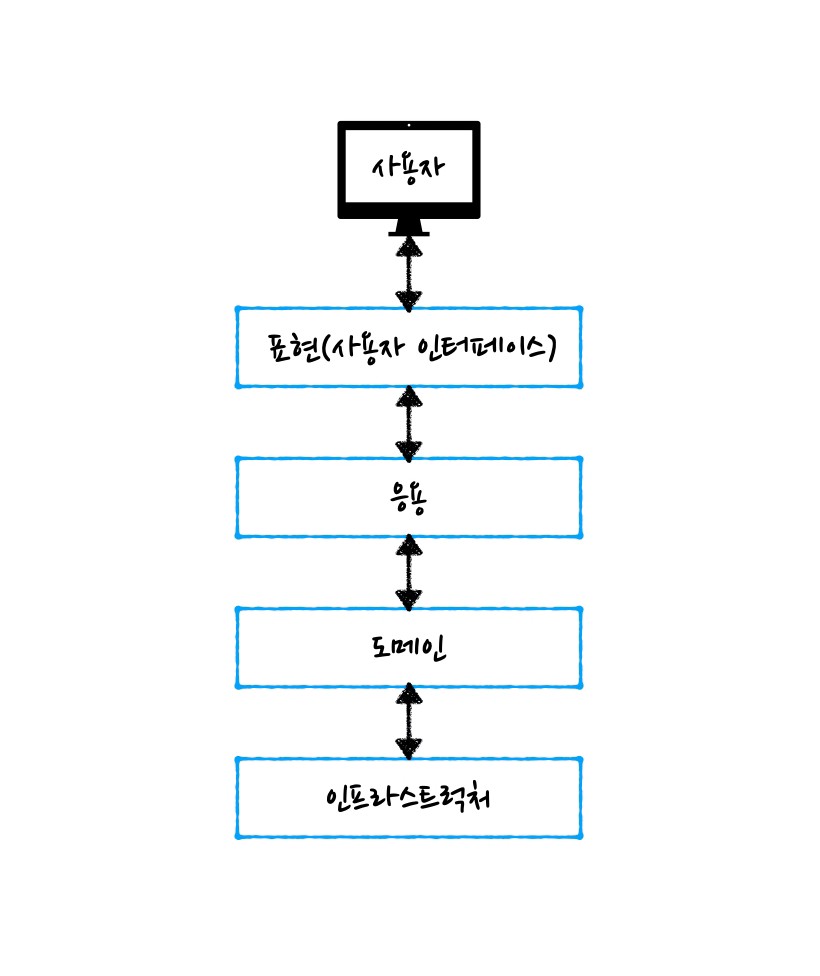
계층형 아키텍처(Layered Architecture)
계층형 아키텍처
계층형 아키텍처에서는 일반적으로 상위 계층이 하위 계층에 의존합니다. 표현 계층은 응용 계층에 의존하고, 응용 계층은 도메인 계층에 의존하는 방식입니다.
DIP(Dependency Inversion Principle)
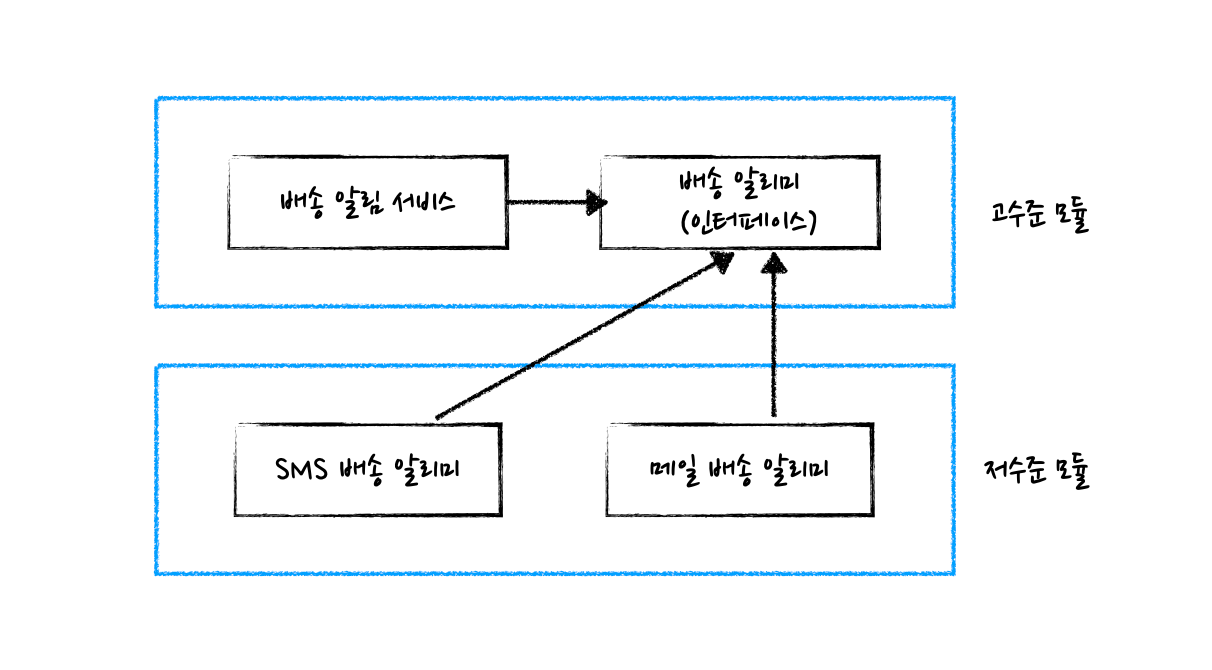
예를 들어 “배송 알림” 기능은 고수준 모듈의 기능이고, “RDBMS에서 주문의 배송 정보를 조회하고, 주문자에게 메일로 배송 알림 메일을 전송한다”는 저수준 모듈의 기능이라고 할 수 있죠.
흔히 고수준 모듈이 저수준 모듈에 의존하도록 구현하는데, 이 경우 저수준 모듈의 변경이 곧 고수준 모듈의 변경으로 이뤄지곤 합니다.
고수준에서의 “배송 알림” 자체에 변경이 없어도, 저수준인 “메일로 배송 알림 메일을 전송한다”라는 저수준의 기능이 “SMS로 배송 알림 메시지를 전송한다”로 바뀐다면 고수준 모듈에서도 변경이 발생하는 것이죠.
이러한 단점을 극복하기 위해 의존 관계를 역전시켜서 저수준 모듈이 고수준 모듈에 의존하도록 구현하는 것을 DIP(Dependency Inversion Principle)라고 합니다.
저수준 모듈이 고수준 모듈을 의존
“배송 알림” 기능을 정의한 “배송 알리미” 인터페이스를 만들고, 저수준 모듈에서 “배송 알리미” 인터페이스를 구현한 저수준 모듈인 “메일 배송 알리미”나 “SMS 배송 알리미”를 만드는 것이죠.
이렇게 저수준 모듈이 고수준 모듈에 의존하도록 바꾸면 저수준 기능인 “메일로 배송 알림 메일을 전송”하던 것이 “SMS로 배송 알림 메시지를 전송”하는 것으로 바뀌더라도 고수준 모듈에서의 변경은 최소화할 수 있습니다.
이때 한 가지 주의사항이 있는데, DIP를 적용하는 목적은 고수준 모듈이 저수준 모듈에 의존하지 않고 반대로 저수준 모듈이 고수준 모듈에 의존하게 하려는 것이기에, 인터페이스를 도출할 때 저수준 모듈의 관점에서 도출하면 안 된다는 것입니다.
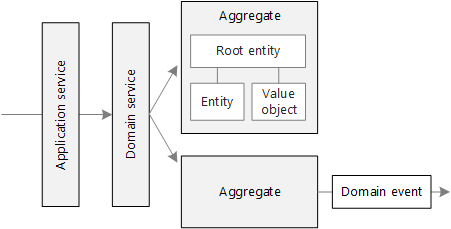
응용 서비스(Application service)
“응용 서비스(Application service)”는 도메인 객체를 이용하여 사용자의 요청에 알맞는 기능을 처리하고 결과를 반환하는 역할을 합니다. 표현 계층과 도메인 계층을 연결해주는 일종의 창구 역할이라고 볼 수 있습니다.
응용 서비스는 응용 계층에 속하기 때문에 도메인과 관련된 로직이 직접적으로 포함되지 않아야 합니다. 대신 도메인 계층에 포함된 도메인 객체들을 사용하여 도메인 기능을 처리하면서 흐름을 제어합니다. 이렇게 처리 흐름을 제어하는 역할을 하다보니 응용 서비스의 기능은 종종 트랜잭션의 단위가 되기도 합니다.
또한 응용 서비스는 표현 계층에 의존하지 않아야 합니다. 예를 들면 표현 계층의 기술인 HTTP 프로토콜에 대한 것(HttpSession, MultipartFile 등)은 응용 서비스에서 사용되지 않도록 해야 합니다.
응용 서비스의 전형적인 구현을 보자면,
1. 리포지터리로 사용할 도메인의 애그리거트 루트를 구하고,
2. 애그리거트 루트의 도메인 기능을 실행하고 처리 흐름을 제어하면서,
3. 처리 결과를 반환합니다.
응용 서비스에 대해서 최범균님이 언급하신 내용 중 하나는 “응용 서비스의 메서드 파라미터로 필요한 값들을 넘기는 대신 도메인 객체 자체를 넘기는 것은 최대한 지양하자”, 였습니다. 응용 서비스의 메서드 파라미터로 도메인 객체를 사용하다보면 도메인 객체에 원래는 필요하지 않던 속성들을 추가하기 마련이고, 이러한 속성들을 영속화에서 제외하는 경우 이를 위해 별도의 설정을 하는 등의 문제를 야기할 수 있기 때문입니다. 따라서 메서드 파라미터로 도메인 객체가 딱 들어맞는 경우에만 사용할 것을 권장하셨습니다.
또 하나 고민해볼 수 있는 내용으로는 “응용 서비스의 결과로 도메인 객체를 반환하는 것과 조회 전용 객체를 반환하는 것 중 어떤 것이 좋을까”, 입니다. 물론 각자 팀의 표준이나 구현 편의성, 성능 등 여러가지 상황을 고려하면 절대적인 답은 없겠지만 별도의 조회 전용 객체를 만들어 반환하는 편을 추천해주셨습니다.
리포지터리(Repository)
“리포지터리(Repository)”는 애그리거트의 영속성을 처리하기 위해 사용합니다.
리포지터리는 애그리거트 루트 단위로 존재해야 합니다. 애그리거트는 그 자체로 하나의 완전한 집합체이기 때문입니다. 따라서 영속화할 때 애그리거트 루트인 객체뿐만 아니라 애그리거트에 포함된 모든 객체를 함께 영속화해야 합니다. 물론 애그리거트를 저장소에서 조회하는 경우에도 애그리거트 루트와 애그리거트에 포함된 객체들을 전부 가져와야 하며, 삭제하는 경우도 마찬가지입니다.
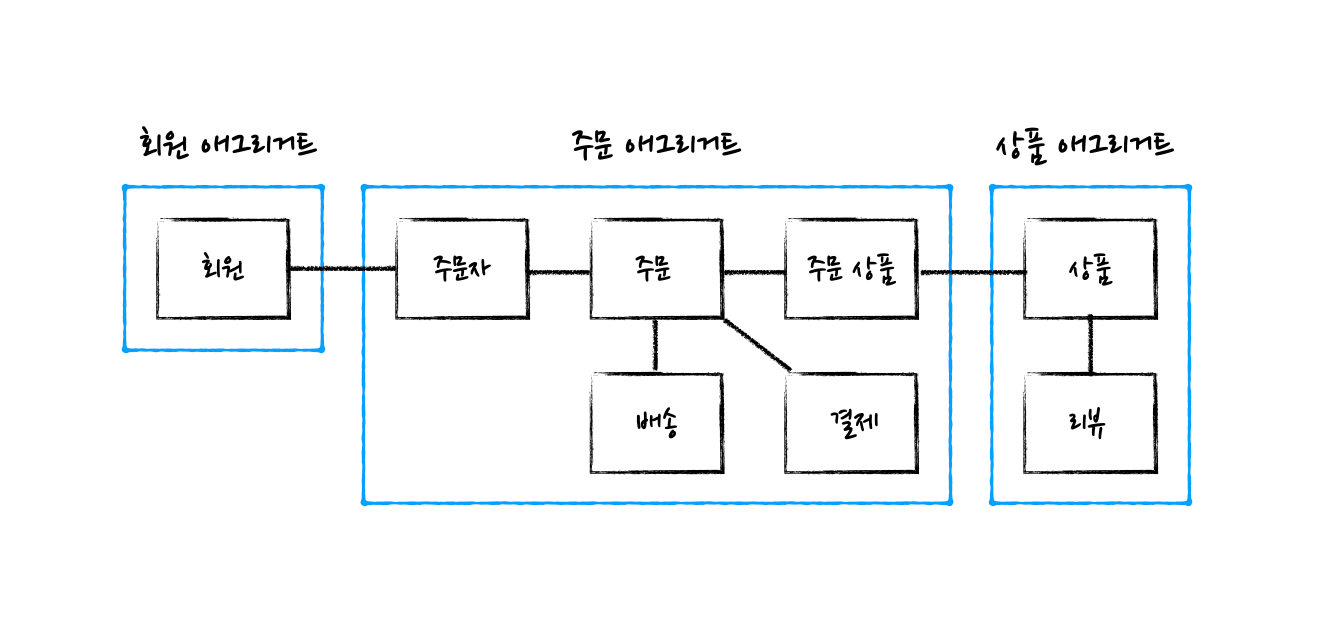
따라서 “주문 애그리거트”가 있고 애그리거트 루트가 주문 객체라면, 주문 객체에 대한 리포지터리를 만들면 됩니다. 주문 애그리거트에 포함된 다른 객체인 “배송”이나 “주문 상품”, “주문자” 각각에 대해서 리포지터리를 만들 필요는 없습니다. 주문 리포지터리가 주문 애그리거트 전체의 영속성을 관리해주니까요.
최범균님은 JPA의 리포지터리를 사용하여 엔티티 객체를 로딩할 때 연관된 객체들을 기본적으로 EAGER 로딩하고, 필요한 경우에만 LAZY 로딩을 사용하기를 언급하셨습니다.
- 애플리케이션의 기능 요구 사항을 이해하기 위한 비즈니스 도메인 분석부터 시작합니다. 이 단계의 결과는 비공식적인 도메인 설명으로, 보다 공식적인 도메인 모델 세트로 구체화할 수 있습니다.
- 다음으로 도메인의 경계가 있는 컨텍스트 를 정의합니다. 각각의 제한된 컨텍스트에는 큰 애플리케이션의 특정 하위 도메인을 나타내는 도메인 모델이 포함됩니다.
- 제한된 컨텍스트 내에서 전술적 DDD 패턴을 적용하여 엔터티, 집계 및 도메인 서비스를 정의합니다.
- 이전 단계의 결과를 사용하여 애플리케이션에서 마이크로 서비스를 식별합니다.
제한된 컨텍스트 정의
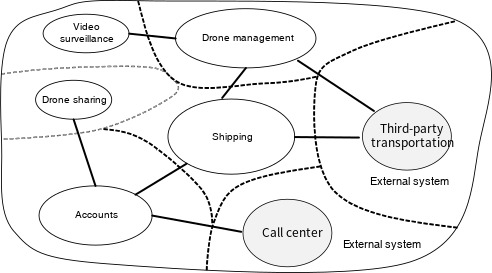
도메인 모델은 현실 세계에 존재하는 항목 — 사용자, 드론, 패키지 등의 표현을 포함합니다. 그렇다고 해서 시스템의 모든 부분에서 동일한 항목에 대해 동일한 표현을 사용해야 한다는 것은 아닙니다.
예를 들어 드 론 복구 및 예측 분석을 처리 하는 하위 시스템은 유지 관리 기록, 진행 중, 연령, 모델 번호, 성능 특성 등 드 론의 여러 물리적 특성을 나타내야 합니다. 그러나 배달 예약에서는 그러한 특징을 고려하지 않습니다. 예약 하위 시스템은 드론의 가용 여부와, 수거 및 배달의 ETA를 알기만 하면 됩니다.
이 두 하위 시스템 모두에 대해 하나의 모델을 만들려고 하면 불필요하게 복잡해질 것입니다. 시간이 흘러 이 모델을 확장하게 되면 변경 사항이 개별 하위 시스템을 담당하는 여러 팀을 만족시켜야 하기 때문에 더 어려워집니다. 따라서 동일한 현실 세계 엔터티(이 경우 드론)을 두 가지 다른 컨텍스트에 표현하는 별도의 모델을 설계하는 것이 더 나은 경우가 종종 있습니다. 각 모델은 특정 컨텍스트 내에서 관련된 기능 및 특성만 포함합니다.
이 경우 바인딩된 컨텍스트의 DDD 개념이 재생 됩니다. 제한된 컨텍스트는 단순히 특정 도메인 모델이 적용되는 도메인 내의 경계입니다. 이전 다이어그램을 살펴보면 다양한 기능이 단일 도메인 모델을 공유하는지의 여부에 따라 기능을 그룹화할 수 있습니다.
경계가 있는 컨텍스트가 반드시 서로 격리될 필요는 없습니다. 이 다이어그램에서 경계가 있는 컨텍스트를 연결하는 실선은 경계가 있는 두 컨텍스트가 상호 작용하는 지점을 나타냅니다. 예를 들어 배송은 고객 정보를 가져오기 위해 사용자 계정을, 선단에서 드론을 예약하기 위해 드론 관리를 사용합니다.
Domain Driven Design 책에서 Eric Evans는 다른 경계가 있는 컨텍스트와 상호 작용할 때 도메인 모델의 무결성을 유지 관리하기 위한 여러 가지 패턴을 설명합니다. 마이크로 서비스의 기본 원칙 중 하나는 서비스가 잘 정의된 API를 통해 통신하는 것입니다. 이 방법은 Evans가 개방형 호스트 서비스와 게시된 언어라고 칭한 두 패턴에 해당합니다. 개방형 호스트 서비스란 하위 시스템이 다른 하위 시스템과의 통신을 위한 공식 프로토콜(API)를 정의하는 것입니다. 게시된 언어는 다른 팀이 클라이언트를 작성하는 데 사용할 수 있는 양식으로 API를 게시하여 이러한 개념을 확장합니다. 마이크로 서비스용 Api 디자인문서에서 openapi 사양 (이전의 Swagger)을 사용 하 여 JSON 또는 yaml 형식으로 표현 된 REST api에 대 한 언어에 관계 없는 인터페이스 설명을 정의 하는 방법을 설명 합니다.
이 섹션에서는 전술적 DDD 패턴에 대한 간략한 개요를 제공하므로 이미 DDD에 익숙하다면 이 섹션을 건너뛸 수 있습니다. 패턴은 Eric Evans의 책 5 – 6장과, Vaughn Vernon의 Implementing Domain-Driven Design(DDD 구현) 에서 더 상세히 설명합니다.
엔터티. 엔터티는 시간이 지나도 지속되는 고유의 ID가 있는 개체입니다. 예를 들어 뱅킹 애플리케이션에서 는 고객과 계좌가 엔터티입니다.
엔터티에는 엔터티를 조회하거나 검색하는 데 사용할 수 있는 고유의 식별자가 있습니다. 식별자가 항상 사용자에게 직접 노출되는 것은 아닙니다. 데이터베이스의 GUID 또는 기본 키가 될 수 있습니다.
ID는 여러 경계가 있는 컨텍스트를 포괄할 수 있고 애플리케이션의 수명을 넘어설 수 있습니다. 예를 들어 은행 계좌번호나 정부 발급 ID는 특정 애플리케이션의 수명 주기에 종속되지 않습니다.
엔터티의 특성은 시간이 지나면서 변화할 수 있습니다. 예를 들어 사용자 이름 또는 주소는 변경될 수 있지만 여전히 같은 사람입니다.
엔터티는 다른 엔터티에 대한 참조를 포함할 수 있습니다.
값 개체. 값 개체에는 ID가 없습니다. 해당 특성의 값으로만 정의됩니다. 값 개체도 변경할 수 없습니다. 값 개체를 업데이트하려면 항상 새 인스턴스를 만들어 기존 인스턴스를 대체합니다. 값 개체는 도메인 논리를 캡슐화하는 메서드를 갖을 수 있으나 이러한 메서드는 개체의 상태에 부작용을 주지 않아야 합니다. 값 개체의 대표적인 예로 색, 날짜 및 시간, 통화 값 등이 있습니다.
집계. 집계는 하나 이상의 엔터티에 대한 일관성 경계를 정의합니다. 한 집계에서 정확히 한 엔터티가 루트입니다. 조회는 루트 엔터티의 식별자를 사용하여 수행됩니다. 집계의 다른 엔터티는 루트의 자식 요소로, 루트의 다음 포인터에서 참조합니다.
집계의 목적은 트랜잭션 고정 항목을 모델링하는 것입니다. 현실은 매우 복잡한 관계로 얽혀있습니다. 고객이 주문을 접수하고, 주문에는 제품이 포함되어 있으며, 제품을 제공하는 공급자가 있는 등 이와 같은 관계가 계속 이어집니다. 애플리케이션이 몇 가지 관련 개체를 수정하는 경우 일관성을 어떻게 유지하나요? 고정 항목을 어떻게 추적하고 적용할까요?
전통적 애플리케이션에서는 데이터베이스 트랜잭션을 사용하여 일관성을 적용하는 경우가 종종 있었습니다. 그러나 분산형 애플리케이션의 경우 현실성이 떨어지는 경우가 많았습니다. 단일 비즈니스 트랜잭션이 여러 데이터 저장소에 걸쳐 있거나, 오래 실행되거나, 타사 서비스와 관련될 수 있습니다. 궁극적으로 이것은 데이터 계층이 아니라 도메인에 필요한 불변 항목을 시행하는 애플리케이션에 달려 있습니다. 이것이 집계가 모델링에서 갖는 의미입니다.
참고 집계는 자식 엔터티 없이 단일 엔터티로 구성될 수 있습니다. 집계를 만드는 것은 트랜잭션 경계입니다.
도메인 및 애플리케이션 서비스. DDD 용어에서 서비스란 상태를 유지하지 않고 일부 논리를 구현하는 개체입니다. Evans는 도메인 논리를 캡슐화 하는 도메인 서비스 와 사용자 인증 또는 SMS 메시지 전송과 같은 기술 기능을 제공 하는 응용 프로그램 서비스 를 구분 합니다. 도메인 서비스는 종종 여러 엔터티를 포괄하는 동작을 모델링하는 데 사용됩니다.
참고 서비스 라는 용어는 소프트웨어 개발에서 범위가 넓습니다. 여기에서는 그 정의가 마이크로 서비스와 직접적인 연관이 없습니다.
도메인 이벤트. 도메인 이벤트는 변경이 있을 때 시스템의 다른 부분에 이를 알리는 데 사용됩니다. 이름에서 알 수 있듯이 도메인 이벤트는 도메인 내의 이벤트를 나타내야 합니다. 예를 들어 "테이블에 레코드가 삽입"되는 것은 도메인 이벤트가 아닙니다. "배달 취소"는 도메인 이벤트입니다. 도메인 이벤트는 마이크로 서비스 아키텍처에서 특히 관련이 있습니다. 마이크로 서비스는 분산되고 데이터 저장소를 공유하지 않으므로, 도메인 이벤트를 통해 마이크로 서비스에서 서로 조정할 수 있습니다. 서비스 간 통신 문서에서는 비동기 메시징에 대해 자세히 설명 합니다.
필자는 도메인 주도 설계Domain-Driven Design(이하 DDD) 빌딩 블록Building blocks[1]으로 애플리케이션을 구현하면서 엔티티ENTITY[2] 마다 리파지토리REPOSITORY를 만드는 것을 자주 보았는데 자세히 살펴보면…
medium.com
필자는 도메인 주도 설계Domain-Driven Design(이하 DDD) 빌딩 블록Building blocks[1]으로 애플리케이션을 구현하면서 엔티티ENTITY[2] 마다 리파지토리REPOSITORY를 만드는 것을 자주 보았는데 자세히 살펴보면 여러 엔티티를 묶어서 하나처럼 사용하는 경우가 대부분이었다. DDD에서는 이러한 연관 객체의 묶음을 애그리게잇AGGREGATE이라고 정의하고 애그리게잇에 포함된 특정 엔티티를 루트Root 엔티티라고 부른다. 그리고 리파지토리를 만들 때 애그리게잇 루트 엔티티에 대해서만 리파지토리를 제공하라고 한다.
이 글은 주문 도메인 예시를 통해 애그리게잇이 무엇인지 알아보고 왜 애그리게잇 루트에 대해서만 리파지토리를 제공해야 하는지에 대해 설명한다.
OrderService에 비즈니스 규칙을 구현함에 따라 OrderService는 Order 뿐만 아니라 연관된 LineItem, OrderPayment, ShippingAddress을 함께 참조하고 있다. 이런 경우 Order를 사용할 때 늘 비즈니스 규칙을 머릿속에 넣어두고 코딩해야 한다. 이 글에서는 이해를 위해 Order를 단순화했지만 실무에서는 Order는 훨씬 더 복잡한 연관 관계와 속성을 가진다. 복잡한 연관 관계를 가지는 Order를 모두 파악하고 사용하는 것은 쉬운 일이 아니다.
DDD의 저자 에릭 에반스Eric Evans는 “모델 내에서 복잡한 연관 관계를 맺는 객체를 대상으로 변경의 일관성을 보장하기란 쉽지 않다. 그 까닭은 단지 개별 객체만이 아닌 서로 밀접한 관계에 있는 객체 집합에도 불변식이 적용돼야 하기 때문이다.” 라고 말했다. 여기서 불변식Invariants은 데이터가 변경될 때마다 유지돼야 하는 일관성 규칙(비즈니스 규칙)을 뜻한다.
Order, LineItem, ShippingAddress, OrderPayment는 각각이 아닌 하나의 집합으로 다루어야 한다. 에릭 에반스는 이를 애그리게잇AGGREGATE으로 정의한다.
모델 내의 참조에 대한 캡슐화를 추상화할 필요가 있다. AGGREGATE는 우리가 데이터 변경의 단위로 다루는 연관 객체의 묶음을 말한다.
각 AGGREGATE에는 루트(root)와 경계(boundary)가 있다.
경계는 AGGREGATE에 무엇이 포함되고 포함되지 않는지를 정의한다.
루트는 단 하나만 존재하며, AGGREGATE에 포함된 특정 ENTITIY를 가르킨다.
경계 안의 객체는 서로 참조할 수 있지만, 경계 바깥의 객체는 해당 AGGREGATE의 구성요소 가운데 루트만 참조할 수 있다.
— 도메인 주도 설계, 131쪽
애그리게잇에 포함된 특정 엔티티를 루트 엔티티라고 한다고 했다. Order, LineItem, ShippingAddress, OrderPayment 중 어떤 것이 루트 엔티티일까?
DDD에서는 루트 엔티티는 전역 식별성Global identity을 지닌 엔티티라고 말한다. 필자는 전자 상거래 사이트에서 주문 파트 개발자로 일한 적이 있다. 콜 센터나 상품 파트, 회원 파트와 협업할 일이 매우 많았는데 대부분 사람들이 주문 번호를 말하며 의사소통했다. 필자가 보기에는 이것이 바로 전역 식별성이다.