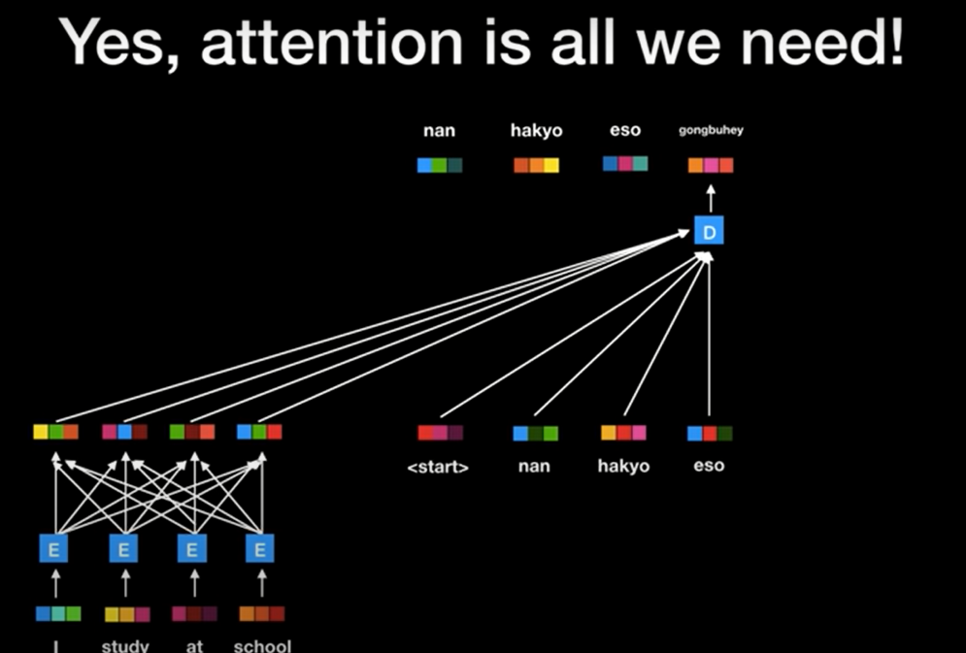
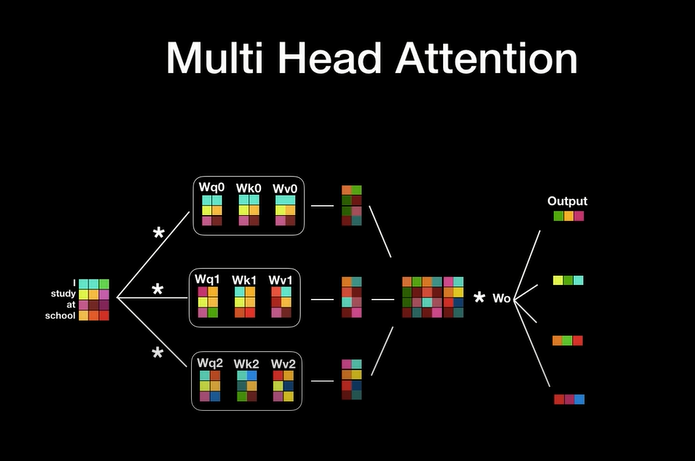
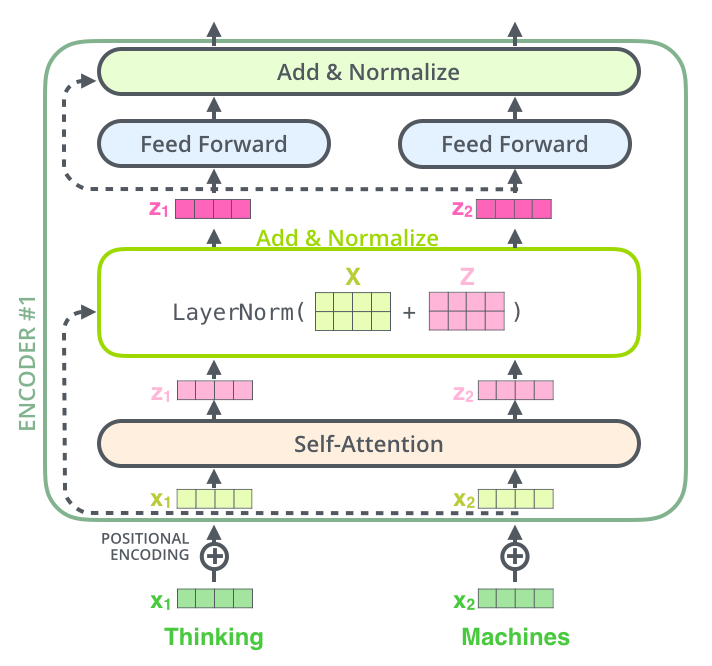
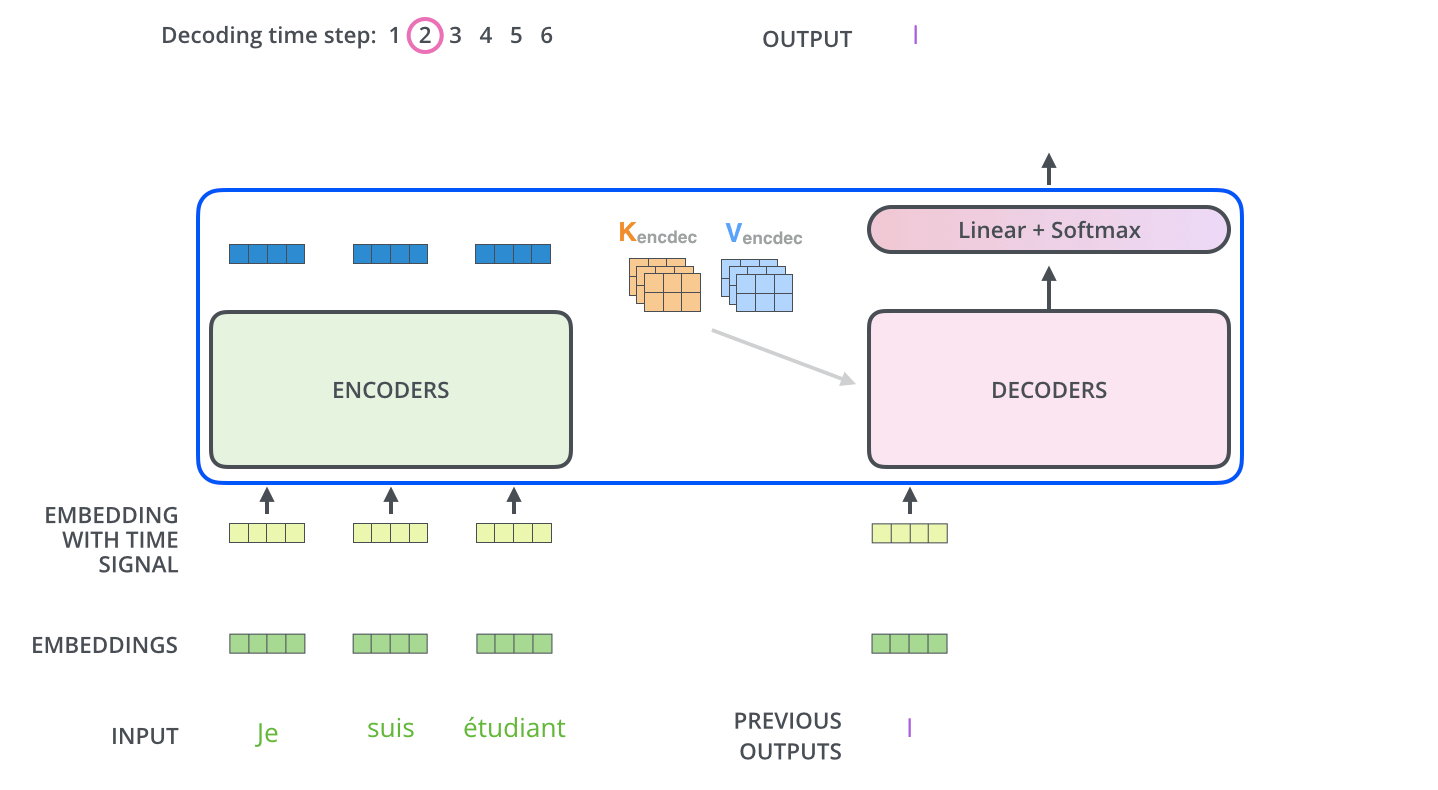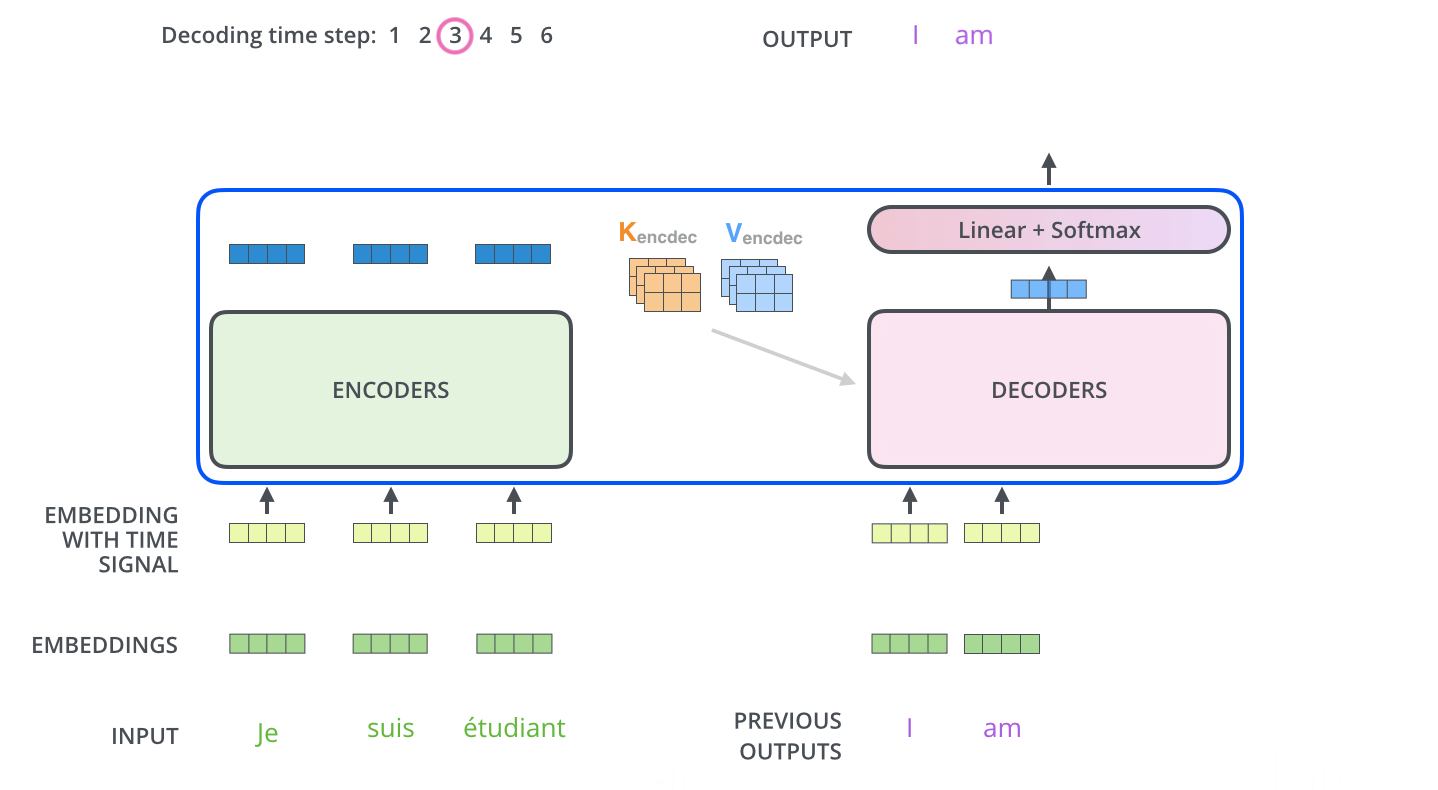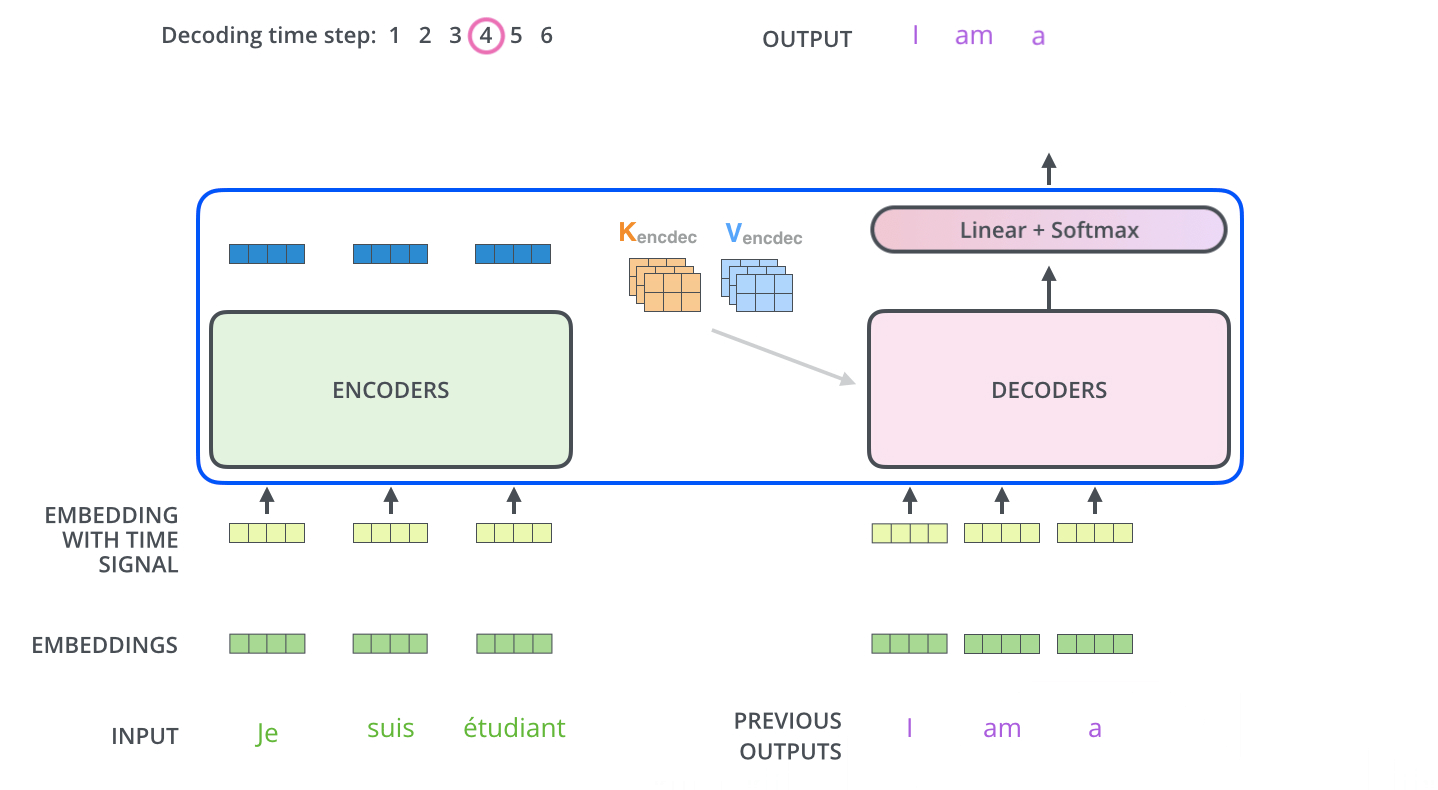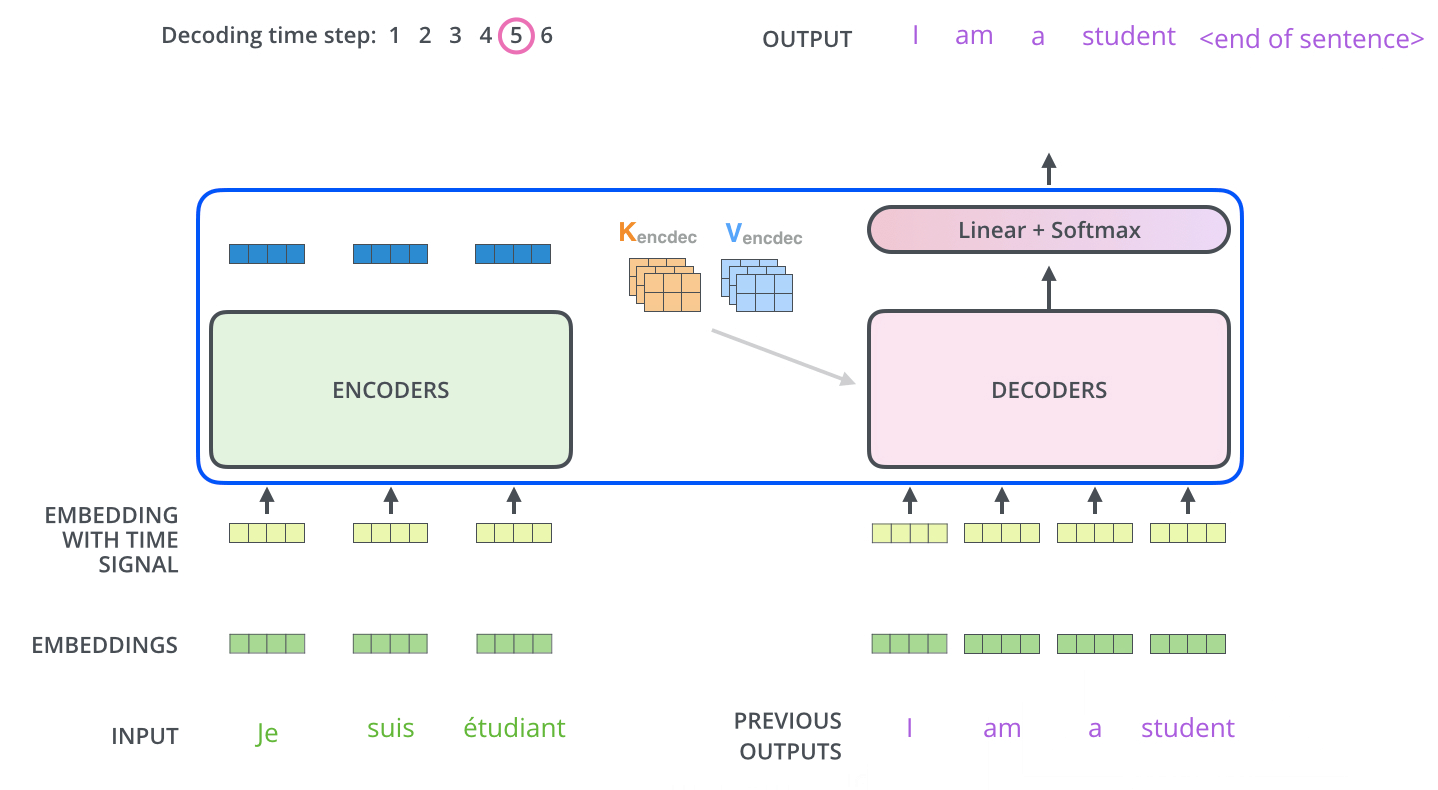
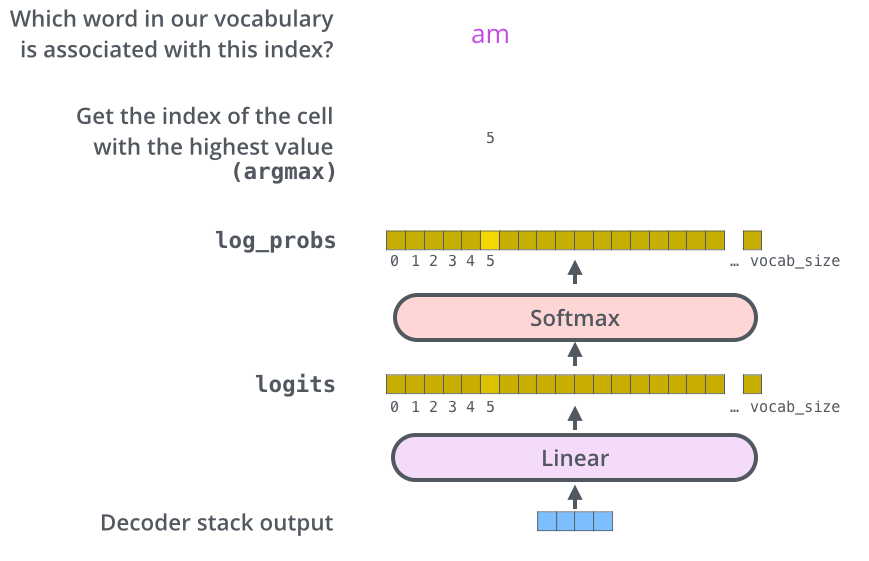
추천 시스템이란?
추천 시스템이 어떻게 활용되나?
추천 시스템 새로운 응용
추천 시스템(Recommendation System) 이란
추천 시스템의 전반적인 내용
https://yamalab.tistory.com/68
추천 시스템 - 위키백과
https://ko.wikipedia.org/wiki/%EC%B6%94%EC%B2%9C_%EC%8B%9C%EC%8A%A4%ED%85%9C
접근법
Collaborate filtering은 사용자 행동, 활동 또는 선호도에 대한 많은 정보를 분석하고 모으고 다른 사용자와의 비슷함에 기초를 두고 사용자들이 무엇을 좋아할지를 예측하는 것에 기초를 두고 있다. Collaborative Filtering 접근법의 한 중요한 장점은 machine analyzable content에 의존하고 있지 않다는 것이다. 그래서 정확하게 아이템 그 자체를 이해하지 않고도 영화와 같은 복잡한 아이템들을 추천할 수 있다. 많은 알고리즘은 추천 시스템에서 사용자나 아이템의 비슷함(similarity)을 측정하는 데 사용되고 있다. 예를 들어, KNN[1]과 Pearson correlation이 있다.
KNN
분류할 때, 분류 대상과 가까운 k 개를 뽑아 그중 가장 많은 비율을 차지 한 쪽으로 분류
Pearson correlation
연속형 두 변수 간의 선형 관계(관련성)를 구하기 위해 사용된다. -1에서 +1사이의 범위 값
Collaborate filtering은 과거에 동의한 사람들이 미래에도 동의하고 그들이 그들이 과거에 좋아했던 것들을 좋아할 것이라는 가정에 기초를 두고 있다.
사용자의 행동으로부터 모델을 만들 때, 특징(차이점)은 종종 data collection의 뚜렷하기도 하고 암시적이도 한 형태 사이에서 만들어진다.
Explicit data collection의 예
사용자에게 item을 평가하게 하기, 검색하게 하기, 가장 선호하는 것과 가장 덜 선호하는 것을 순위 매기게 하기 등
implicit data collection의 예
사용자가 본 item을 관찰하고 분석하기, 사용자가 구매한 item을 기록하기, 사용자의 SNS를 분석하고 비슷한 likes와 dislikes를 찾아내기
이 추천 시스템은 모아진 데이터를 다른 사람들로부터 모아진 비슷하고 안 비슷한 데이터와 비교하고, 사용자의 추천된 items 목록을 계산한다.
Linkedin, facebook과 같은 SNS는 collaboprative filtering을 친구 추천 등에 사용한다.
Content-based filtering
또 다른 잘 알려진 접근법은 content-based filtering이다. 이는 item에 대한 설명(description)과 사용자 선호에 대한 profile을 기반으로 한다.
Content-based 추천 시스템에서, 키워드는 item을 설명(describe) 하는데 사용되고 사용자의 프로필은 이 사용자가 좋아하는 류(type)의 item을 가리키게(indicate) 만들어진다. 다른 말로 하면, 이런 알고리즘들은 과거에 사용자가 좋아했던 것들(또는 현재 보고 있는 것들)과 비슷한 items을 추천하려고 한다. 구체적으로 말하면, 다양한 후보 items은 사용자에 의해 현재 평가되는 (rated) items과 비교되고 best-matching items은 추천된다. 이 접근법은 information retrieval과 information filtering에 뿌리를 두고 있다.
Information retrieval
집합적 정보로부터 원하는 내용이나 관련되는 내용을 가져오는 것
Information filtering
필요 없는 정보를 제거하는 것
Items의 특징을 끌어내기 위해, tf-idf 알고리즘이 많이 사용된다.
Tf-idf: Term frequency-inverse document frequency
여러 문서로 이루어진 문서 군이 있을 때 어떤 단어가 특정 문서 내에서 얼마나 중요한 것인지를 나타내는 통계적 수치이다.
TF(term-frequency 단어 빈도)가 높을수록 문서에서 중요하다고 생각될 수도 있지만 단순히 흔하게 등장하는 것일 수도 있음. 이를 DF(document frequency 문서 빈도)라고 하며, 이 값의 역수를 IDF(inverse)라고 한다. TF-IDF는 TF와 IDF를 곱한 값이다.
사용자의 profile을 만들기 위해서, 그 시스템은 대게 두 가지 정보에 집중한다:
1. 사용자의 선호의 model
2. 추천 시스템과 사용자의 상호작용 정보(history)
기본적으로 이런 방법들은 시스템 안에서 item에 특성을 부여하면서 item profile(이산적 features와 attributes)을 사용한다. 그 시스템은 item 특성의 weighted vector을 기반으로 한 사용자의 content-based profile을 만든다. Weights는 사용자에게 각각의 feature의 중요도를 나타내고 개별적으로 점수 매겨진(rated) content vectors로부터 다양한 방법으로 계산될 수 있다. 사용자가 좋아할 것 같은 확률(probability)을 계산하기 위해 다른 복잡한 방법 들해 베이지란 분류, 클러스터 분석, 결정 트리 그리고 인공 신경망 네트워크와 같은 머신러닝 기술을 사용하는 반면에, 간단한 접근법들은 그 점수 매겨진 item vector의 평균 값을 사용한다.
보통 ‘좋아요’와 ‘싫어요’와 같은 형태로 사용자로부터 직접적인 피드백은 특정한 속성(attribute)의 중요도에 대한 더 높거나 낮은 weight를 할당하는데 사용될 수 있다.
Content-based filtering의 중요한 문제점은, 한 content source에 관련된 사용자들 행동으로부터 사용자 선호도를 배울 수 있고 다른 content 종류(type)을 넘어서 그것들을 사용할 수 있을지 아닌 지이다. 그 시스템이 사용자가 이미 사용한 것과 같은 종류의 content를 추천하는 것에 한정돼 있을 때, 다른 서비스의 다른 종류의 content가 추천될 수 있을 때보다 추천 시스템의 가치는 상당히 낮다. 예를 들어, news browsing에 기반한 추천 뉴스 기사는 유용하지만, news browsing에 기반해 추천될 수 있는 다른 서비스의 음악, 비디오, 제품 토론에서 더 유용하다.
Pandora Radio는 첫 seed와 같이 사용자에 의해 제공된 노래와 비슷한 특징의 음악을 재생해 주는 content-based 추천 시스템의 한 예이다.
Hybrid recommender systems
최근 연구는 collaborate 과 content-based filtering을 섞은 hybrid 접근법이 몇몇의 상황에서 더 효과적일 수 있다고 설명한다. Hybrid 접근법은 여러 가지 방법으로 사용(implement) 될 수 있다: 한 접근법을 다른 접근법에 더하거나, 하나의 model로 만들거나. 몇몇의 연구들은 두 가지 접근법을 hybrid와 경험에 기인해서 비교하고 hybrid가 두 접근법들보다 훨씬 더 정확한 추천을 제공한다고 말한다. 이런 방법들은 cold start와 sparsity 문제와 같은 추천 시스템에서 공통적인 문제의 몇몇을 극복할 수 있다고 한다.
Cold start: 충분한 정보가 없어서 필요한 정보를 얻지 못하는 것
Netflix는 hybrid 추천 시스템의 좋은 예이다. 이 웹사이트는 사용자가 높게 평가했던(content-based) 영화와 비슷한 특성을 띄는 영화를 추천하고, 비슷한 사용자(collaborate)들의 검색 습관과 시청을 비교함으로써 추천을 한다.
다양한 기술들은 추천 시스템의 기초로 제안되어 왔다: collaborative, content-based, knowledge-based 그리고 demographic 기술. 이 기술들은, 몇 개의 평가(rating)을 한 새로운 사용자를 어떻게 하지와 같이 collaborative와 content-based의 유명한 cold-start 문제와 knowledge-based 접근법의 the knowledge engineering bottleneck(병목현상)과 같은 단점을 가지고 있다. Hybrid 추천 시스템은 그들 사이의 시너지를 얻기 위해서 여러 기술들을 합치는 것이다
|
Collaborative |
이 시스템은 다른 사용자들과 items에 대한 profiles을 평가하는 정보만 사용하면서 추천을 한다. 이 시스템은 현재의 사용자나 items과 비슷한 평가 기록(history)와 함께 비슷한(peer) 사용자 또는 items을 배치하고, 이 근접 이웃(neighborhood)를 이요 해서 추천을 만든다. 사용자 기반과 item 기반의 가장 가까운 이웃 알고리즘은 cold-start 문제를 해결하기 위해 합쳐질 수 있고 추천 결과를 향상시킬 수 있다. |
|
Content-based |
이 시스템은 사용자가 그들에게 준 평가와 제품들과 관련된 특징이라는 두 가지 Sources로부터 추천을 만든다. Content-based 추천자는 추천을 user-specific 분류 문제처럼 다루고 제품의 특징에 기반한 사용자의 좋아요 와 싫어요의 분류자를 학습한다. |
|
Demographic |
Demographic(인구 통계학적) 추천은 사용자의 인구통계학적 정보(profile)를 기반으로 추천을 제공한다. 추천된 제품은 그 영역의 사용자들의 평가들을 합침으로써 다른 인구통계학적 영역을 위해 만들어질 수 있다. |
|
Knowledge-based |
이 추천자는 사용자의 선호와 요구(needs)에 대한 추론을 기반으로 한 제품을 제안한다. 이 지식(knowledge)는 때때로 얼마나 특정한 제품 특징이 사용자의 요구를 충족시키는지에 대한 뚜렷한 기능적(functional) 지식을 포함한다. |
Hybrid 추천 시스템이란 용어는 여기서 결과를 만들어 내기 위해 다중의 추천 기술을 함께 섞는 어떠한 추천 시스템을 설명하는데 사용된다. 같은 유형의 몇몇의 다른 기술들이 함께 되지(be hybridzed) 못하는지에 대한 이유는 없다. 예를 들어, 두 개의 다른 content-based 추천은 함께 효과를 낼 수 있고 많은 프로젝트들이 이런 종류의 조합에 투자해 왔다: naïve bayes와 knn을 함께 사용한 NewsDude는 한 예다. 7개의 hybridization 기술들:
1. Weighted: 다른 추천 요소들의 점수는 수학적으로 합쳐진다.
2. Switching: 그 시스템은 추천 요소들 안에서 선택하고 고른 것을 적용한다.
3. Mixed: 다른 추천자로부터의 추천들은 추천을 주기 위해 함께 보인다.
4. Feature Combination: 다른 지식 sources로부터 나온 특징들은 함께 합쳐지고 하나의 추천 알고리즘에 쓰인다.
5. Feature Augmentation: 하나의 추천 기술은 하나의 특징이나 다음 기술의 입력의 한 부분이 될 특징들의 세트에 사용된다.
6. Cascade: 추천자는 더 낮은 우선순위들이 더 높은 것들의 점수를 매기는 것이 단절되면서 엄격한 우선순위를 가진다.
7. Meta-level: 한 추천 기술은 적용되고 다음 기술의 입력으로 사용되는 몇몇의 model을 만든다.
정확도를 넘어서
전형적으로, 추천 시스템에 대한 연구는 가장 정확한 추천 알고리즘을 찾는 것에 관심을 둔다. 하지만, 많은 중요한 요소들이 있다.
· Diversity – 사용자들은 다른 아티스트의 items와 같은 더 높은 intra-list 다양성이 있을 때 추천 시스템에 더 만족하는 경향을 보인다.
· Recommender persistence – 어떤 상황에서, 추천을 다시 보여주거나 사용자가 다시 items을 평가하게 하는 것이 더 효과적이다.
· Privacy – 추천 시스템은 대게 privacy 문제를 해결해야 한다. 왜냐하면 사용자들은 민감한 정보를 공개해야 하기 때문이다. · Collaborative filtering을 사용해 사용자의 profiles을 만드는 것은 privacy의 관점에서 문제가 될 수 있다. 많은 유럽 국가들은 data privacy에 대한 강한 문화를 가지고 있고, 사용자의 profile을 만드는 어떠한 단계를 소개하려는 모든 시도는 부정적인 사용자 반응을 초래할 수 있다. Netflix Prize competition을 위해 Netflix에서 제공한 데이터 셋에 관련해서 많은 privacy 문제가 발생했었다. 그 데이터 셋이 고객의 개인 정보를 지키기 위해 익명화됐음에도 불구하고, 2007에 텍사스 대학의 두 연구자는 Internet Movie Database에 영화 평가 데이터 셋을 매치함으로써 사용자 개개인을 식별할 수 있었다. 결과적으로, 2009년 12월, 한 익명의 Netflix 사용자는 Netflix를 고소했다. 이건 2010의 두 번째 Netflix Prize competition을 취소하는 데 부분적으로 영향을 끼쳤다. 많은 연구들은 이 영역의 진행 중인 개인 정보 문제를 행하고 있다. Ramakrishnan 은 개인화와 정보보호 사이에서 교환의 확장적인 개요에 대해 행동했고, 다른 데이터 소스(sources)와 약한 연결들(우연히 발견한 추천을 제공하는 예상치 못한 연결)의 조합이 익명화된 데이터 셋에서 사용자의 정체를 발견하는데 사용될 수 있다는 것을 찾았다.
· User demographics- Beel 은 사용자 인구학이 얼마나 사용자가 추천에 만족해하는지에 대해 영향을 줄지도 모른다는 것을 발견했다. 그들의 연구에서, 그들은 나이가 많은 사용자들이 어린 사용자들보다 추천에 더 관심을 보이는 경향이 있다는 것을 증명했다.
· Robustness – 사용자가 추천 시스템에 참여할 수 있을 때, 속이는 문제(the issue of fraud)는 반드시 다뤄진다.
· Serendipity – Serendipity(우연히 발생, 발견됨)는 얼마나 추천 시스템이 놀라운가에 대한 측정이다. 예를 들어, 마트에서 고객에게 우유를 추천하는 한 추천 시스템은 완벽하게 정확할지라도, 이건 좋은 추천 시스템이 아니다. 왜냐하면 그 고객이 살 품목이 너무 명백하기 때문이다. 하지만, 뜻밖의 serendipity는 정확도에 부정적인 영향을 줄지도 모른다.
· Trust – 추천 시스템은 사용자가 시스템을 신뢰하지 않으면 사용자에게 가치가 없다. 신뢰는 어떻게 추천을 만들어 내는지와 왜 이 item을 추천했는지를 설명함으로써 쌓을 수 있다.
· Labelling – 추천 시스템에 대한 사용자의 만족은 추천의 labeling(그룹 짓기, 이름 짓기)에 따라 영향을 받을지도 모른다. 예를 들어, 한 인용된 연구에서, sponsored로 묶인 추천에 대한 Click Through Rate(CTR)은 Organic으로 묶인 동일한 추천에 대한 CTR보다 낮다. 그 연구에서 Label이 없는 추천이 가장 좋은 성능을 보였다.
추천 시스템 만들기
https://www.slideshare.net/kwnam4u/02-41434707
넷플릭스 추천 시스템
https://m.post.naver.com/viewer/postView.nhn?volumeNo=28425732&memberNo=41516152&vType=VERTICAL
BLENDING
물론 넷플릭스는 단순히 하나의 알고리즘만을 사용하지 않고 많은 알고리즘을 블렌딩하여 사용합니다.
원두를 섞어서 향을 다양하게 만들듯이 여러 알고리즘을 블렌딩하면 정확도가 상승한다는 사실을
Netflix Prize 대회를 통해 알아냈기 때문입니다.

추천 시스템 정리 자료
https://m.blog.naver.com/eqfq1/221551267898
(머신러닝을 이용한 토익 문제 추천 시스템)
https://www.youtube.com/watch?v=v_wnkwuoHew
[교육 분야 추천 시스템 활용]
수학 문제 과외 선생님 콴다 프로젝트
[콴다 프로젝트 추가자료]
https://brunch.co.kr/@mathpresso/9
[인공지능 교육 플랫폼 산타인사이드]
https://santainside.riiid.app/ko/main

산타인사이드


'머신러닝' 카테고리의 다른 글
| 이미지 객체 검출 YOLO, DETR (0) | 2020.12.03 |
|---|---|
| kaggle, dacon, google colab, tensorflow, torch, 머신러닝 기초 입문 (0) | 2020.11.27 |
| [추천강의] 이은아님 머신러닝 비정형 데이터 분석 11/11 GPT (0) | 2020.07.23 |
| [추천강의] 이은아님 머신러닝 비정형 데이터 분석 10/11 Transformer (0) | 2020.07.21 |
| 머신러닝으로 투자에 성공할 수 있을까? (0) | 2020.07.16 |